
wildskychen
1.4K posts



外媒报道非洲三国取消台湾总统赖清德专机的飞航许可后,德国和捷克也拒绝让赖清德过境的请求。针对这则报道。台湾总统府没有正面回应。 #Echobox=1777534060" target="_blank" rel="nofollow noopener">zaobao.com.sg/news/china/sto…
中文






一帮披着科技从业者的金融投机客,因Manus事件哀嚎的样子很好笑
当美国以国家安全的名义,阻挠中国公司以正常的流程收购美国科技公司,阻挠英伟达向中国出售ai显卡时,这帮金融投机客连个屁都不放
当中国效仿美国,以国家安全名义限制Manus出售给脸书,这帮金融投机客开始大骂中国破坏自由市场
中文





挺搞笑的,meta20亿高价买了manus,结果Claude Code和Codex 强势崛起,Manus不值钱了😂
现在是不是还得退款啊,我看小扎都要笑疯了吧
中文

中文

中文

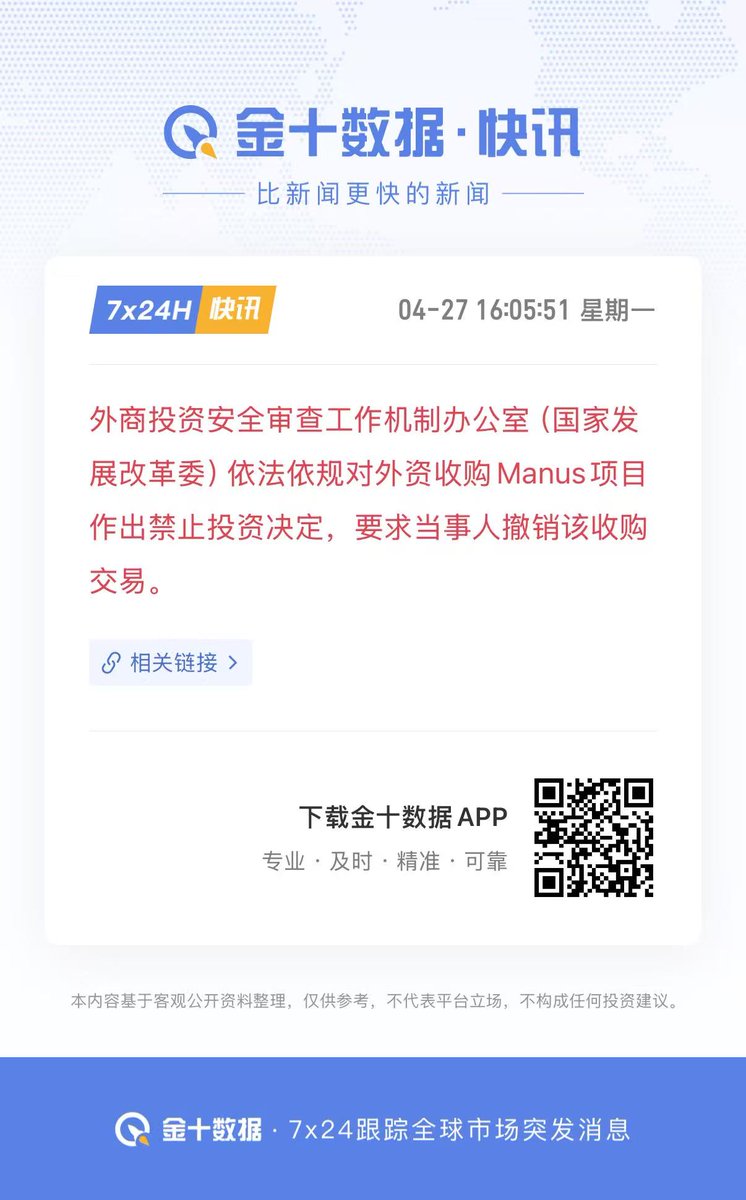


manus 收购案暴露出了一个更大的问题,
官僚系统在面临工业革命的时候,完全无法快速反应,甚至连经验都没有。
几个月前 manus 叫香饽饽,但是 AI 生产力提速实在是太高了,
几个月后龙虾被淘汰,爱马仕被淘汰,现在又整出新活了
回过头看,商务部拦截一堆也被淘汰的产品卖出高价。
而这种事情肯定还会屡屡发生,
因为普通人无法意识到浪潮的快速变化,无法意识到生产力的巨大提升,
而更封闭的官僚反应比普通人还慢,
你不能让一个还在祈祷继续玩房地产经济的人,一下子就理解高科技带来的降维打击了。
这也是为啥龙虾出来,到处跟风,一人公司出来,又 fomo,
因为啥都不懂,所以才会到处捡垃圾吃,别人扔啥你都当个宝。
中文

@wangzhian8848 也沒說錯,我們台灣呢光是對外都無法保持一致,所以一直希望你們這些流亡人士能幫中國多帶來些民主自由,少一些戾氣,這樣我們也安全些,拜託了
中文


张驰,浙大本科,UCLA 博士(导师朱松纯),2025 年加入字节 Seed 做数学推理,干了一年后离职去北大当助理教授。最近上播客 Into Asia 回顾了在字节的一年,不少判断跟目前的公开叙事直接冲突。
他的核心观点:
1. 字节跑完一轮完整迭代(预训练+后训练)要大约半年,谷歌据传三个月。他认为迭代速度差距是追不上的根本原因。
2. Seed 内部 benchmaxxing 严重。领导按 benchmark 分数考核,大家都在刷榜,但他说纸面追平了不等于真的好用,「实际体验不行」。
3. 2024 年底 Seed 自认追平了 GPT-4o,结果 DeepSeek 一出来才发现差距还在。他入职时全组紧急转强化学习。
4. 他认为中美 AI 差距在扩大不是缩小。原话:「我甚至不同意中国在追赶这个说法,我们仍然远远落后。」同事和学生同意,但智谱、MiniMax 这些上市公司的领导层不会同意。
5. 蒸馏走捷径很普遍。很多公司直接调 Claude/GPT/Gemini 的输出当训练数据。不过他也承认 DeepSeek 在 V3/R1 上有真正的架构创新。
6. 字节主力芯片是 NVIDIA H20,最快的卡留给预训练和后训练团队。国产芯片有但没人用于训练。字节在海外采购新一代 NVIDIA 芯片,但「肯定不在中国大陆」。
7. 美国公司有用户反馈飞轮,模型好用→用户多→反馈好→模型更好。中国模型起步差,没人愿意用在重要工作上,数据拿不到,恶性循环。
8. 他在谷歌实习时觉得基础设施「太好了」,跟字节差距巨大。不只是芯片,训练框架和整个基础设施都差一截。
9. 中国 AI 从业者普遍用美国 Agent 工具。他自己用 Claude Code 和 Copilot,中国模型的编码 Agent 他评价「完全不实用」。字节海外团队直接用 Cursor。
10. Claude Code 好用到让他在想还要不要培养博士生,但又怕不培养下一代,以后没人做研究。
背景补充:张驰在字节只待了约一年,所在的数学组他自己说偏宣传性质,不在核心的预训练/后训练团队。他的观点是个人视角,不代表字节全貌。
中文
