Lancelot
2.9K posts


Lancelot
@wraitii
Building @hyli_org with @sylvechv, and on the weekends I work on @play0ad 🏛
Paris Katılım Eylül 2021
639 Takip Edilen1.8K Takipçiler
@LauriPelto Seems to be a similar « privacy » setup at a sufficiently high level
English

If Canton is so good why isn’t there canton 2
Tempo@tempo
Blockchains still broadcast every transaction publicly. Every stablecoin payment leaks the amount, the sender, and the recipient. We’re excited to share that Tempo is building Zones for businesses that need privacy: private blockchains that are interoperable with the rest of Tempo for stablecoin use cases like payroll, treasury, and settlement.
English
Lancelot retweetledi

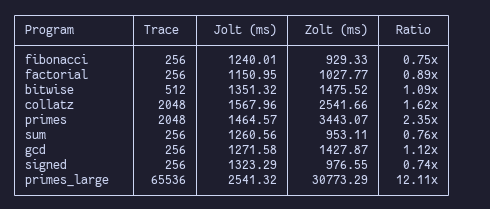
A month later, Zolt v0.1.0 is here!
- Code is good enough to make an official release
- Faster than Jolt on the @eth_proofs' SHA256 benchmarks 😱
- Huge refactoring effort
- Really fun to work on!
- Still a lot of work to do to match Jolt with bigger programs (2^28+)

matteo@mtteom_
Introducing Zolt: the first pure-Zig zkVM Fully compatible with @a16zcrypto's Jolt, the entire cryptography is made from scratch in @ziglang , only using the stdlib! No arkworks FFI or other dependencies 🫡 The first benchmarks:
English
Lancelot retweetledi

God does not bless any conflict. Anyone who is a disciple of Christ, the Prince of Peace, is never on the side of those who once wielded the sword and today drop bombs. Military action will not create space for freedom or times of #Peace, which comes only from the patient promotion of coexistence and dialogue among peoples.
English

trans person: i'm trans
society: ok
ur acadian friend u try to ignore: as-tu des cigarettes
English
Lancelot retweetledi
Introducing Zolt: the first pure-Zig zkVM
Fully compatible with @a16zcrypto's Jolt, the entire cryptography is made from scratch in @ziglang , only using the stdlib!
No arkworks FFI or other dependencies 🫡
The first benchmarks:
English
@eniwhere_ Machine virtuelle pour preuve à divulgation nulle de connaissance gang
Français


@secparam Leader needs to convince 2f+1 that it is not skipping something finalized.
From these 2f+1 at least one has voted on votes and will show the votes as proof.
The showing the votes is not necessary it can bluntly reject. But it makes it simpler if they do.
English

Lancelot retweetledi

