@MilksandMatcha found you through your cerebras/exa collab on building ai research agents. i build many myself! would love this.
English
Wudlig
1.7K posts

Today, we closed our latest funding round with $122 billion in committed capital at an $852B post-money valuation. The fastest way to expand AI’s benefits is to put useful intelligence in people’s hands early and let access compound globally. This funding gives us resources to lead at scale. openai.com/index/accelera…










JUST IN: 🇮🇷 Exiled Crown Prince Reza Pahlavi says he has accepted role as Iran's transitional leader.





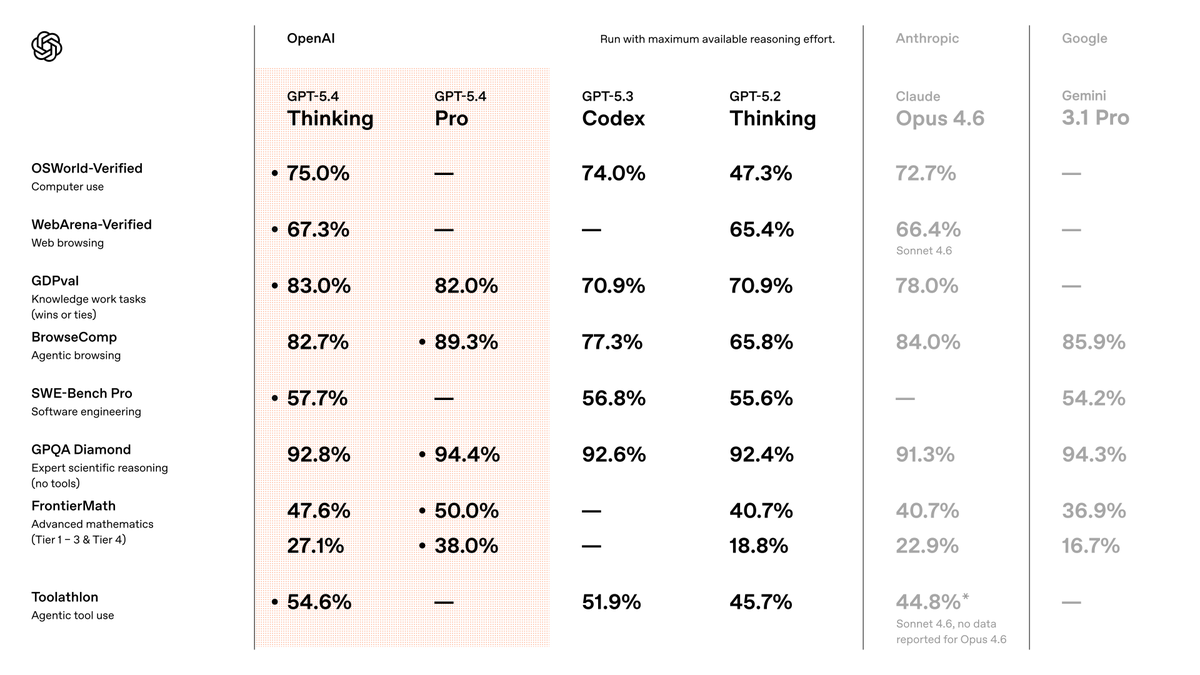
One silly thing about the benchmaxxing wars is that, in every press release, labs omit the benchmarks where they are not winning. That creates an illusion that every release is SOTA at absolutely everything. It is rare for OpenAI not to include results for ARC-AGI