My IIT Kharagpur professor nailed it: one-hot encoding is a phone book, not a thesaurus.
"king" and "queen" get random, unrelated vectors. 50,000-word vocab? Every word is 49,999 zeros and one 1.
It gives words identity. Not meaning. That's exactly why word embeddings exist.
link: drive.google.com/file/d/1hMYQvL…
🧠 The conversation around AI for developers usually starts with the model.
But inside @code, what really shapes the experience is the coding harness: the layer responsible for context, tool calling, agent loops, terminal execution, memory, and more.
In this new post, the engineering team dives into how GitHub Copilot in VS Code works behind the scenes.
code.visualstudio.com/blogs/2026/05/…
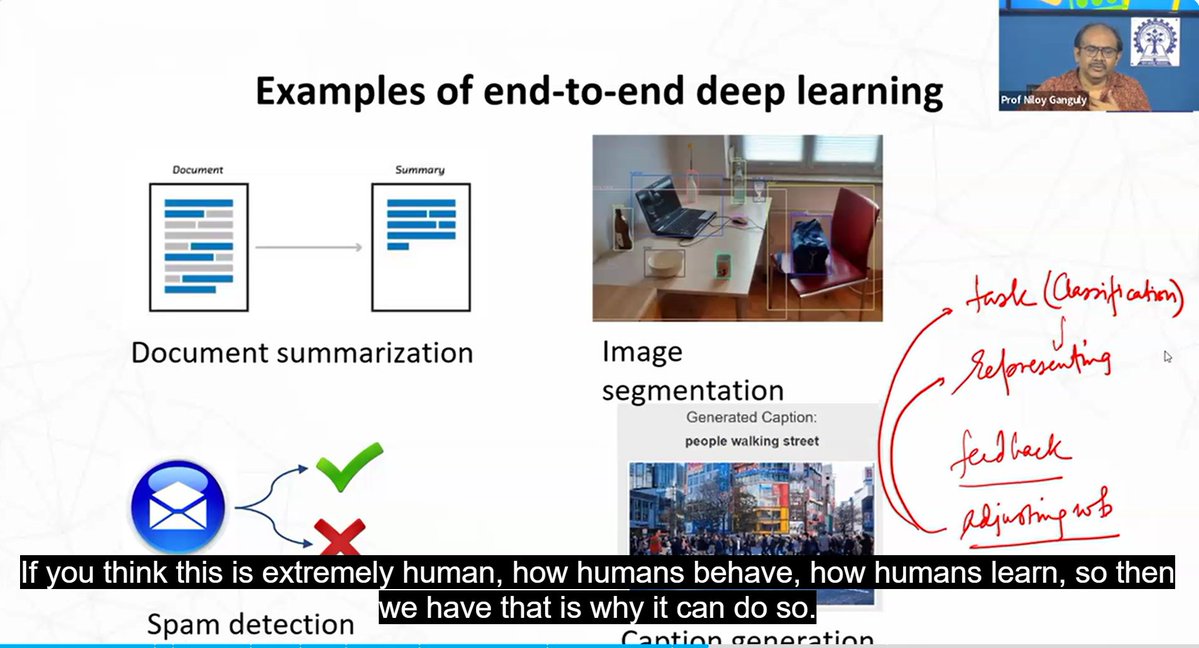
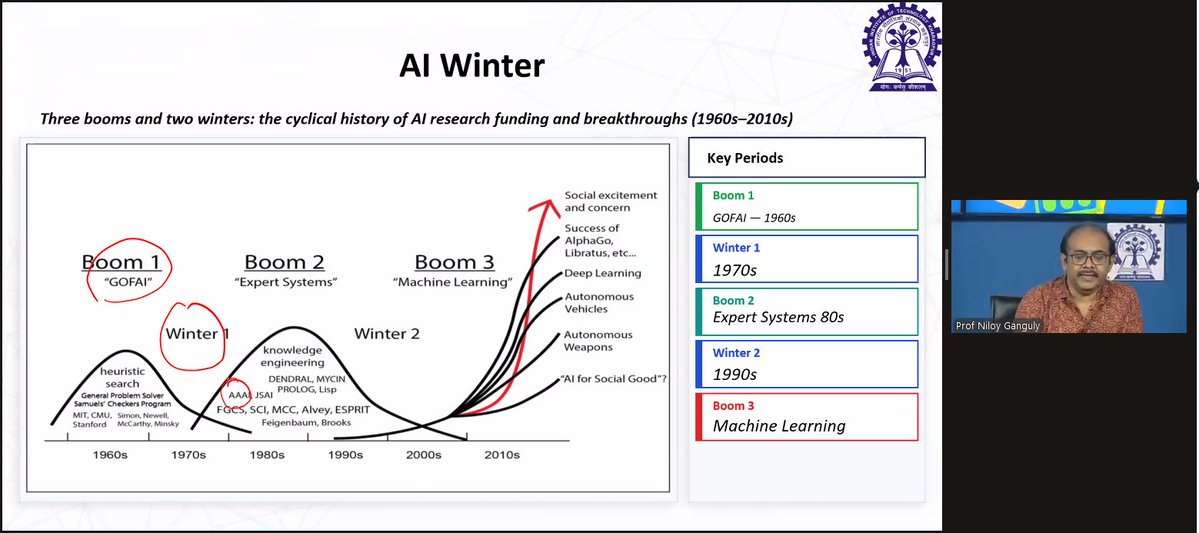
My IIT Kharagpur professor taught deep learning and I turned my notes into a proper PDF.
I'm sharing it because it's the kind of resource I wish I had before the class.
Here's what's in it and why I think it's different from most deep learning intros you'll find online.
Every concept in this PDF maps directly to a slide from the actual class. The slides are embedded right next to the explanation. So if something doesn't click as text, you can see exactly what the professor was pointing at on screen.
The analogies are what make this one stand out.
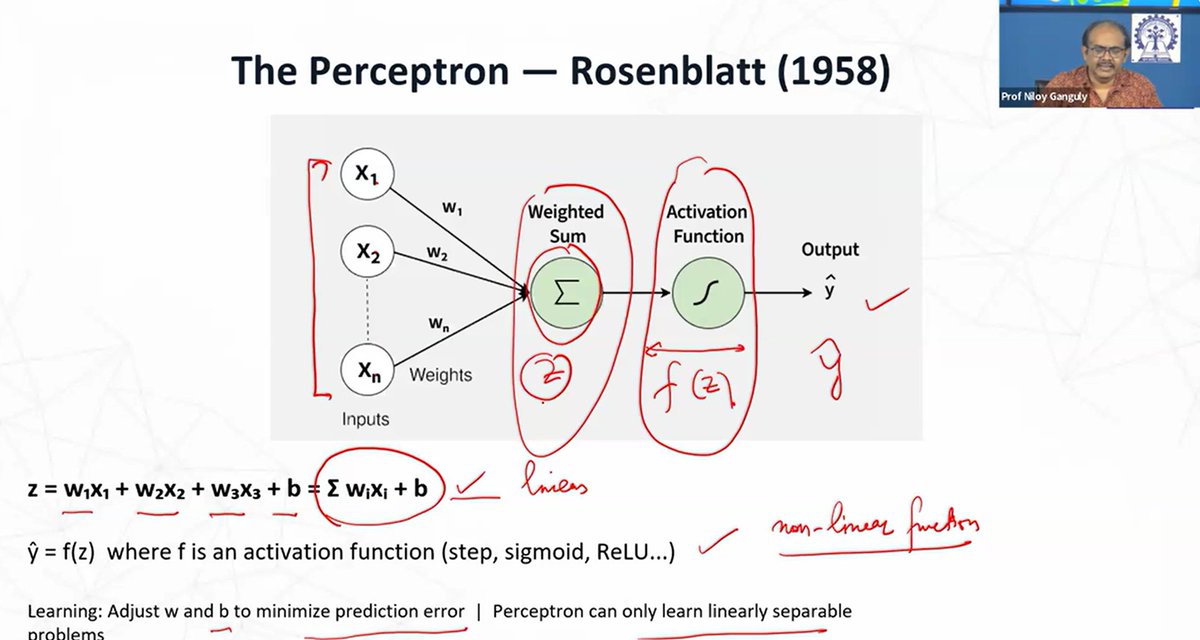
The perceptron isn't explained with math first. It's explained like this: you're deciding whether to go outside. Is it sunny? Is it warm? Am I free? Each answer has a weight. Add them up. If the total crosses your threshold, you go. That's a perceptron.
Every formula in the PDF is broken down the same way. Symbol by symbol. Plain English for each part. Then a quick numeric example you can trace by hand. No formula just dropped on the page and left there.
And there are exercises at the end to actually test whether it stuck.
Career Updates
Starting live Agentic AI Learnings with IIT Kharagpur professors.
Not YouTube tutorials. Real industrial AI:
LLMS, embeddings, agents, and what's actually happening in AI labs.
Learning in public from experts. Follow for real insights, not hype 🚀
Hey Techies...!
I'm looking to #CONNECT with people interested in:
- Frontend
- Backend
- Full stack
- DevOps
- AI/ML
- Data Science
- UI/UX
- Freelancing
- Startup
- Saas
Say hi & Let's grow together #BuildingInPublic
trying to connect with more people in computer science, especially in:
AI / Deep Learning Systems / CUDA Backend / Infra Compilers / ML Systems Distributed Systems Performance Engineering Algorithms / Data Structures Operating Systems
If that’s your space (or you’re exploring it), let’s connect 🤝
Claude Code can now send push notifications to your phone when a long task finishes or Claude needs your input.
Walk away from the terminal, we'll let you know when it's done.
Another visual walkthrough of @vllm_project's continuous batching with a full dummy example flow: prefill batch, slot mapping, paged KV block allocations, sampled tokens appended to request state, then a mixed decode + prefill step. Sampled tokens are appended to each request’s state, but the engine rebuilds a fresh flat batch every step from only the tokens that still need compute.
We have just added a new premium collection for anyone prepping for a Google DeepMind interview!
it will go through
1. Math Foundations
2. Probability & Statistics
3. Neural Network Fundamentals
4. Optimization
5. Regularization & Normalization
6. Loss Functions
7. Transformers & Attention
.
.
.
and 6 other sections to make sure you are ready for the interview
Softmax vs Hardmax by hand ✍️ ~ interactive calculator 👉 byhand.ai/vhUJDH
Softmax turns a set of raw scores (z) into a probability distribution (Y) over choices (a, b, c, d, e). Instead of just saying which option is best, it tells us how likely each option is to be chosen. In this example, most of the probability mass is concentrated on c, while the other options are still possible but clearly less likely. That's the point of softmax: it converts relative scores into meaningful, comparable probabilities that sum to 100%.
Think of a raffle. Hardmax is when the person who bought the most tickets always wins the prize — the top score takes it, every time. Softmax is when everyone's chance is proportional to the tickets they hold: even if I bought just one ticket, I may still get lucky. Who knows. That's the psychology of softmax.
This is how a language model chooses its next word. Each time a word appears in the training data, it earns a ticket. Hardmax would always speak the word with the most tickets — the same safe choice, over and over. Softmax gives every word a chance proportional to its tickets, so less common words can still be spoken. The word with the most tickets still has the highest chance of winning — just not 100%. That's what lets the model surprise us with its creativity (and also its hallucinations) instead of repeating itself.
100 → 1350+ followers in 39 days.
No hacks. Just consistency.
Best part? The people:
• Builders scaling startups
• Folks grinding for jobs
• Students (BCA, MTech, MBA) figuring things out
• Deep convos on products, placements & tech
My DMs have been wild. That’s what made this journey worth it.
If you’re into:
• Startups
• Frontend / backend / full stack development
• Tech jobs, remote work, placements
Let’s connect.
Follow + DM “hi”. I reply to everyone 🤝