Sabitlenmiş Tweet

I’m rebuilding GEMM optimisation on H100 from scratch and documenting the full path toward cuBLAS level performance in a deep dive blog.
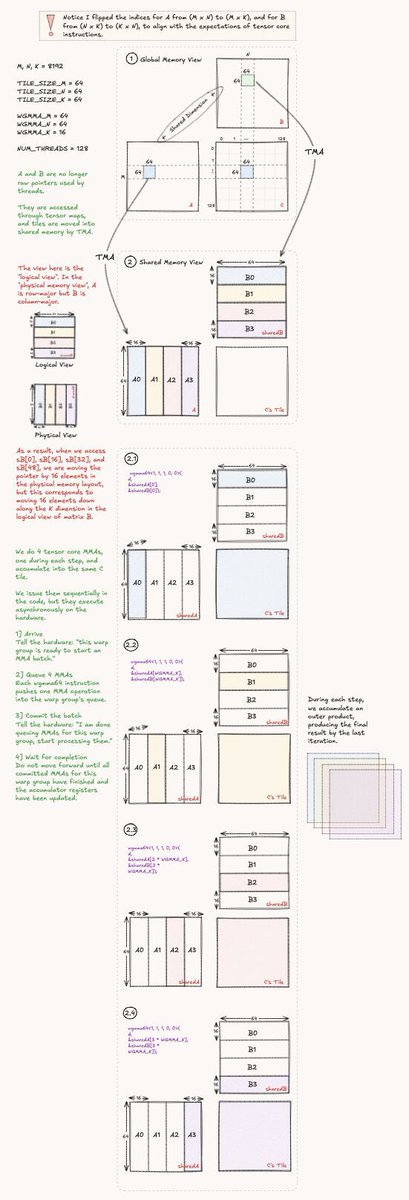
8 kernels in so far, from naive all the way to Tensor Cores (Async TMA + WGMMA). Just hit 407.7 TFLOP/s, now at 56.9% of cuBLAS with Tensor Cores.
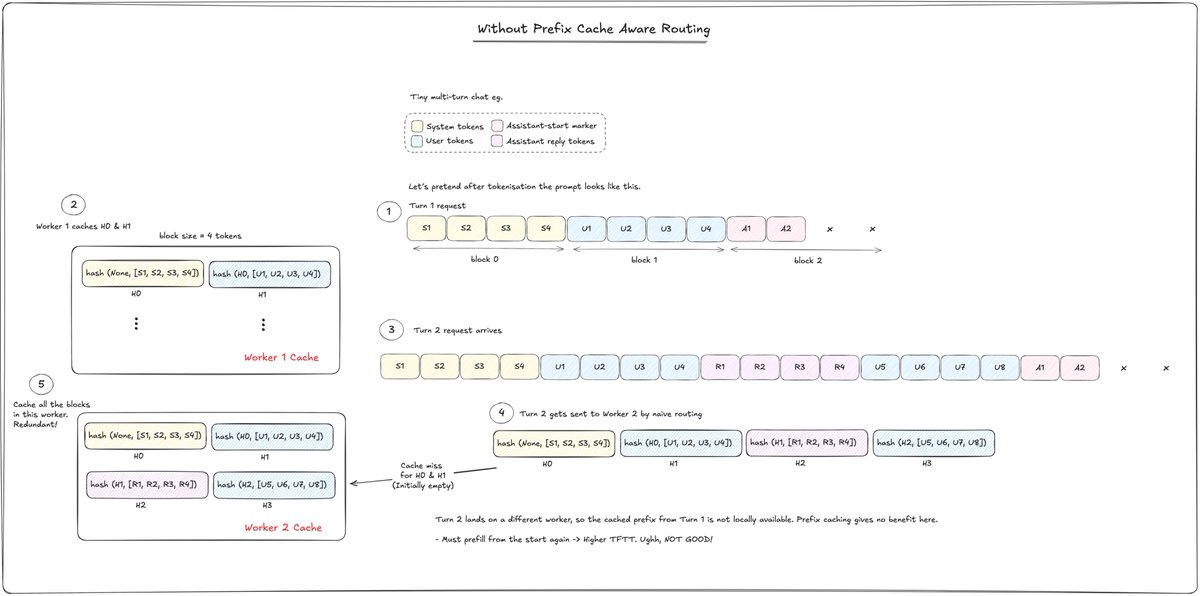
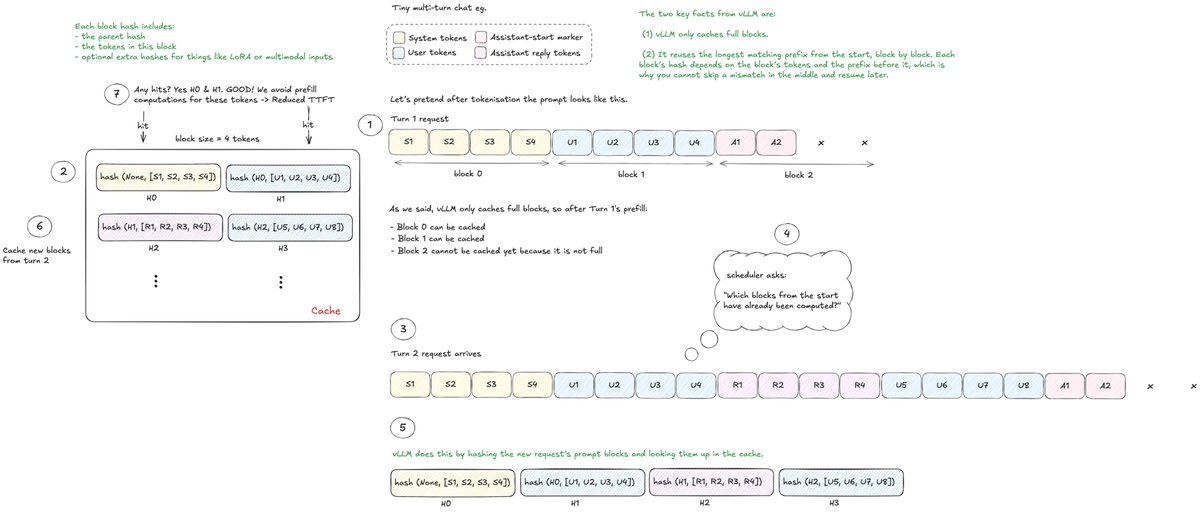
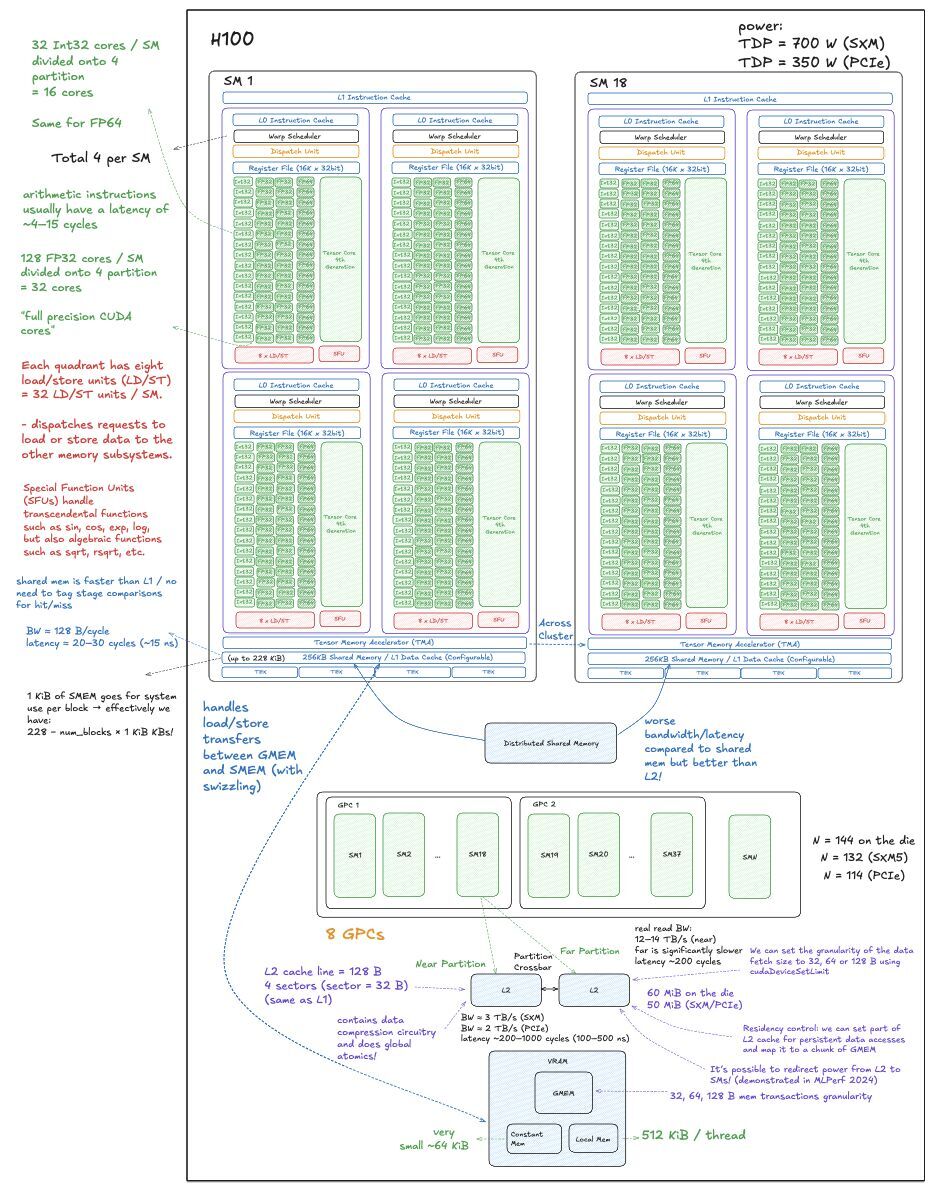
Each kernel is broken down in detail: profiling bottlenecks, PTX and SASS inspection, memory behaviour, and 35+ visuals!!! so far explaining what is happening at the hardware level for each kernel. I also included a full H100 architecture section to ground the optimisation decisions.
Still more to push.
Blog: hamzaelshafie.bearblog.dev/worklog-optimi…
Repo: github.com/HamzaElshafie/…
English