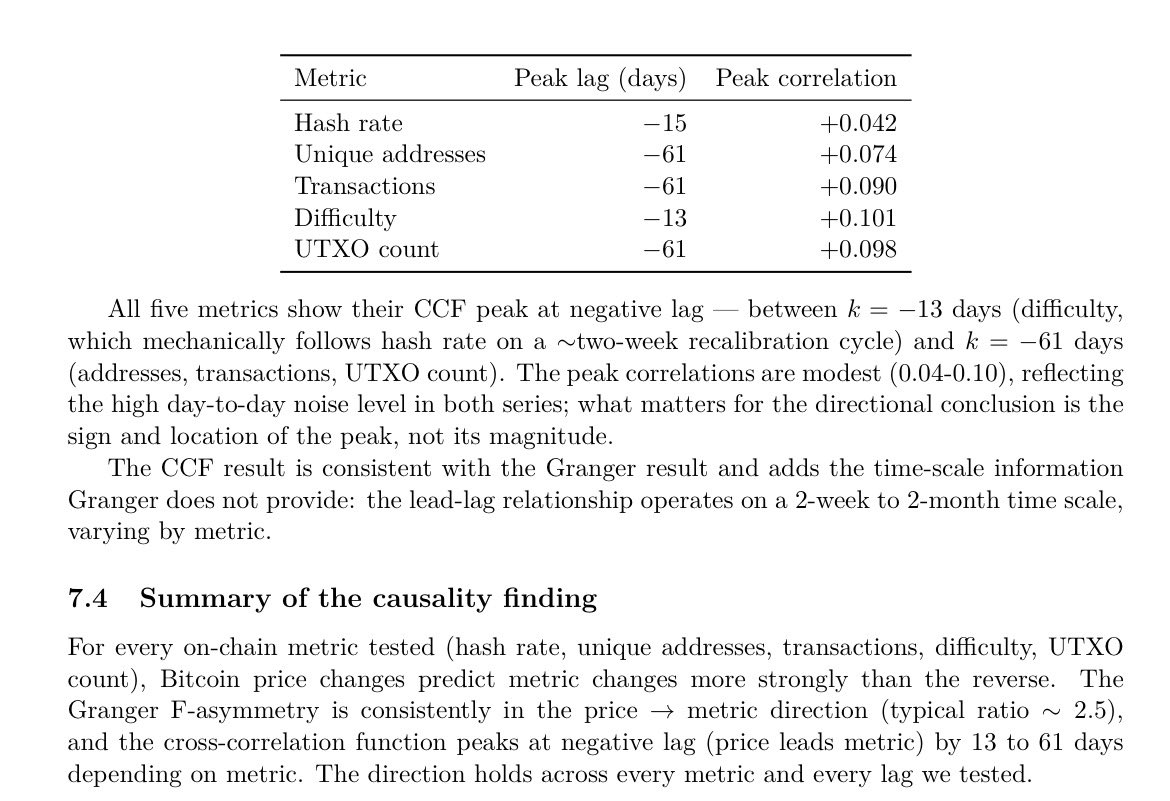
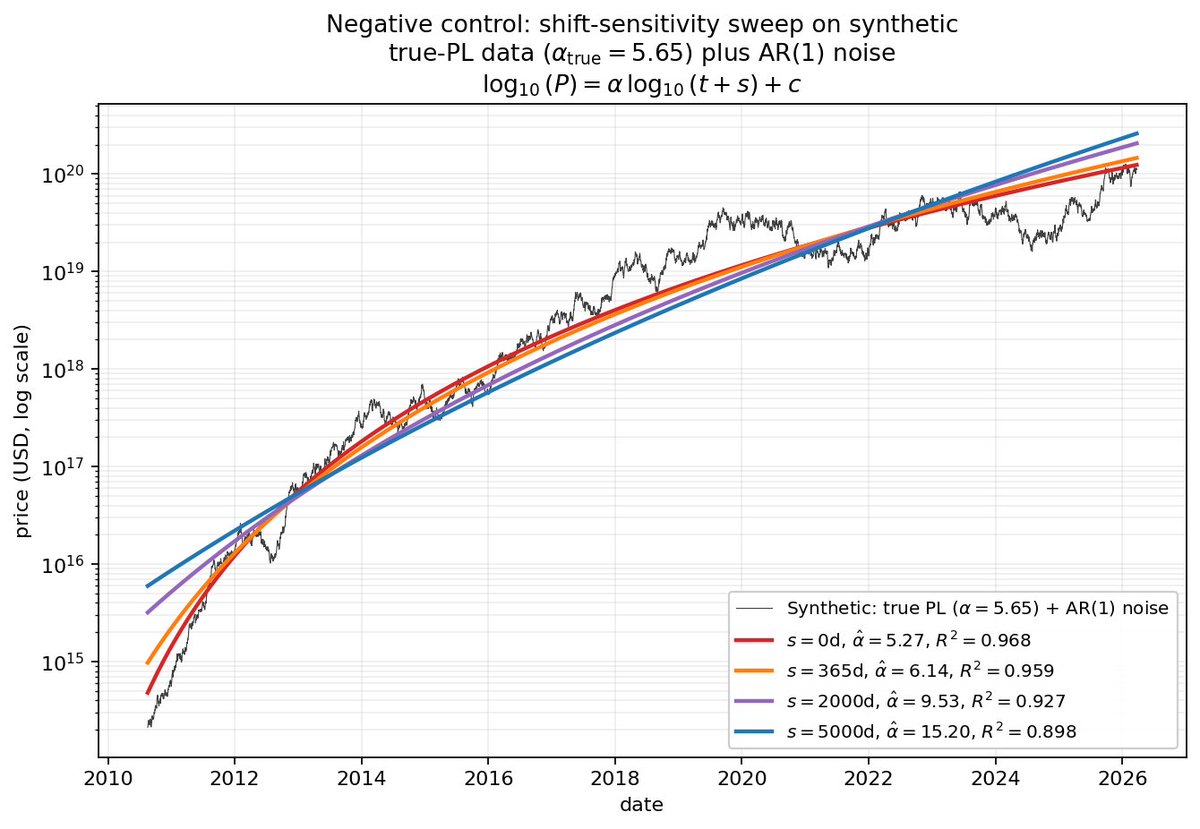
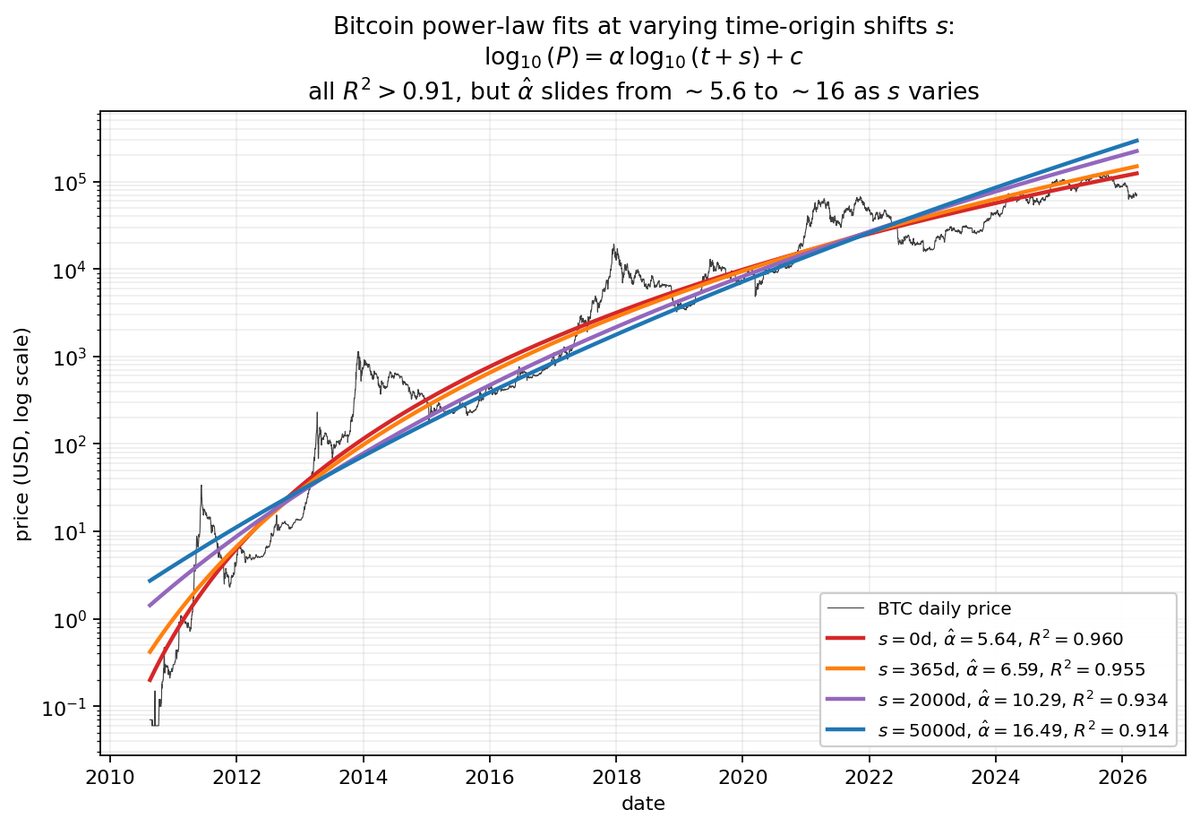
@antirez Did you read the new @LynAldenContact novel? I also found it very interesting, on a topic not dissimilar, but don’t want to do spoilers.
English
Carlos Baquero
14.4K posts

@xmal
Professor @feup_porto and researcher @inesctec. Distributed Systems and Data. Co-creator of CRDTs. Still searching for unknown unknowns






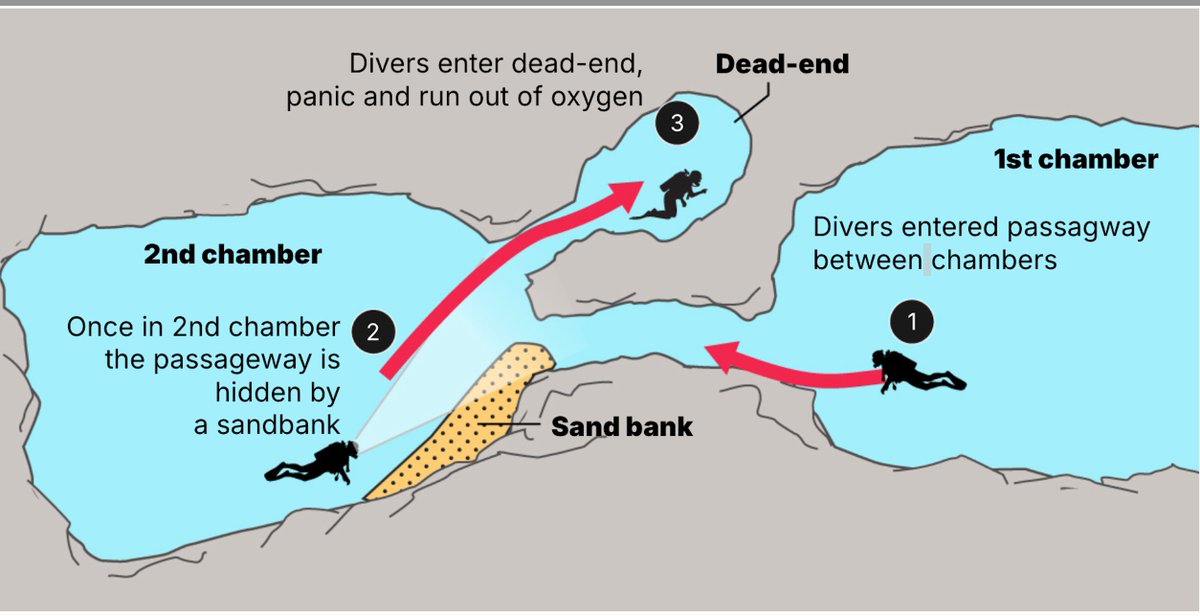

🇲🇻🇮🇹 FLASH | « Ils ont été trompés par le sable et ont pris la mauvaise sortie, se retrouvant piégés. » Une THÉORIE émerge désormais après les inspections menées par l’équipe finlandaise chargée de ramener les corps des plongeurs italiens : les 5 victimes pourraient s’être PERDUES à l’intérieur des tunnels sous-marins et avoir emprunté une mauvaise issue en tentant de regagner la surface, avant de se retrouver dans une impasse. (La Repubblica)