Gen z boss and an acquihire
NIK@ns123abc
🚨NEWS: Meta in talks to invest more than $10 billion in Scale AI
Nederlands
yalishandi
23 posts
🚨NEWS: Meta in talks to invest more than $10 billion in Scale AI




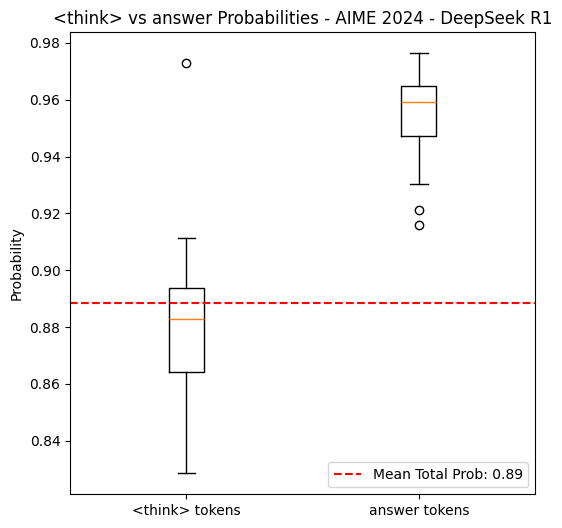
Underrated paper and idea on using RL losses on non-verifiable domains, in this case the perplexity of the next chapter of a book.




🚀 Day 4 of #OpenSourceWeek: Optimized Parallelism Strategies ✅ DualPipe - a bidirectional pipeline parallelism algorithm for computation-communication overlap in V3/R1 training. 🔗 github.com/deepseek-ai/Du… ✅ EPLB - an expert-parallel load balancer for V3/R1. 🔗 github.com/deepseek-ai/ep… 📊 Analyze computation-communication overlap in V3/R1. 🔗 github.com/deepseek-ai/pr…