
yonder
8.4K posts



@MikeisIRL @coah80 this is the poor option, rich kids back in the day paid for private server hosting just to host three people
English


Hamachi was genuinely terrible nobody should ever defend this stupid software
Rei 🇳🇴@reikodev
Minecraft added friend requests and easy multiplayer? Real ones used this:
English
@the_andrey_x you can press the power button 5 times to disable face ID and force PIN
English

The comments are full of people saying biometrics are the best...
BIOMETRICS ARE THE WORST SECURITY SYSTEM
Cops and soldiers CAN and WILL:
1) take your phone away and open it by holding it in front of your face
2) forcibly place your finger on your fingerprint ID
There is no reliable way to prevent this from happening. Never use biometrics if you're an activist or working in a high-risk environment.
INSTEAD:
1) Set a long alphanumeric password, change it periodically
2) On iPhones put the setting that erases your phone after 10 incorrect password guesses
3) Make sure your apps don't show your messages when your phone is locked
4) Set all your chats on auto-delete after a week
5) Set additional internal passwords on all important apps
6) If you're getting arrested/kidnapped, try to turn your phone off before it's taken away from you, on latest models this automatically encrypts it
Aditi@aditiraaaj
Hey @grok which one provides better security in 2026?
English


@kayleecodez hate to say it, but everyone that rejects kubernetes inevitably ends up recreating it from first principles lol
English

recently worked on an autoscaling system on top of morph cloud for the past few days and ngl it was hella interesting and some of you might not know what autoscaling is and what morph cloud is so lemme tell you
basically autoscaling means your system automatically creates or removes machines depending on traffic/load. if your app suddenly gets a spike in users, more machines spin up. if traffic drops, extra machines get removed so you dont waste resources. sounds simple until you actually try building it.
morph cloud basically lets you spin up cloud machines programmatically through APIs, snapshots, metadata etc, so my autoscaler could literally create and terminate VMs on its own depending on what the controller decided.
the fun part is the architecture behind it. one loop in the system continuously observes reality by checking instances, health, metrics and provider state. another loop decides what the "desired state" should be. then both loops constantly try to reconcile with each other while the cloud provider itself is asynchronously doing things in the background.
my fav bug was when the controller started creating machines faster than the collector could detect them, so the autoscaler was like "damn still not enough servers" and kept spawning more morph VMs every few seconds cuz of stale state and eventual consistency issues.
also learnt that in infra software, false success is genuinely scarier than failure. if the cloud provider rejects an instance creation request but your control loop records it as success anyway, your entire system starts believing imaginary machines exist and everything slowly turns into some fuckery.
honestly one of the coolest things ive worked on recently.
English





for the last few weeks i kept dodging the "is the dgx spark worth it?" question because i did not have one to test. now i do, and i can give you the real answer.
it is an absolute workhorse. cranks 56 tok/s on a 30b model at q8 with full multimodal + tool calls on hermes agent, eats long prompts at 1,300 tok/s prefill, holds 256k context without breaking a sweat.
128gb unified memory unlocks model classes nothing else in the consumer tier even tries.
low maintenance, silent, sits on the desk and works.
if you can afford it and you are serious about local ai at the frontier consumer tier, this deserves a slot on your desk.
one of the rare pieces of hardware that earns its price the moment it powers on
Sudo su@sudoingX
a week with the dgx spark, here is what is on it and what i have measured so far. nobody is really talking about this machine and it is quietly becoming the workhorse of my whole stack. hardware: nvidia gb10 sm_121, 124 gb unified lpddr5x at 273 gb/s, cuda 13.0 models on disk (305 gb total, 9 ggufs): > qwen 3.6 27b q4_k_m / q5_k_m / q8_0 / ud-q4_k_xl > nemotron 3 omni 30b-a3b q4_k_m / q8_0 / ud-q6_k / ud-q6_k_xl > deepseek v4-flash 158b q4_k_m (112 gb, flagship 128gb-tier test) terminal + shell environment: > zsh + oh-my-zsh + powerlevel10k theme > modern cli stack: bat, eza, ripgrep, fd, git-delta, tldr, neovim, fzf, autojump > 6 tmux sessions actively running for parallel agent work ml + agent stack: > llama.cpp built sm_121 against cuda 13 > uv + venv ml stack with pytorch 2.11.0+cu130 (aarch64) + transformers + diffusers + accelerate > hermes agent v0.11 with codex auth bridge > opencode for free-model overnight research > telegram gateway routing to nemotron q8 right now speeds verified so far: - nemotron 30b-a3b q8: 56 tok/s gen, 1,300 tok/s prefill, 96% gpu, 33gb in unified - qwen 27b dense q4: 40 tok/s consistent 90+ gb of unified memory still free. deepseek v4-flash 158b loading next as the real flagship test, multimodal omni testing once mmproj pulls, comfyui install in flight for the diffusion lane. honestly curious what the actual limit is on this box, i have not hit it yet.
English

English


I'm British.
The UK is a warning to the rest of the world.
Please listen very carefully:
English
@ImGregPartlow @yacineMTB "massive" here is hundreds of megabytes, it's practically nothing
English

@yacineMTB static linking simplifies deployment but binary sizes get massive fast
English

@ssskryl @yacineMTB so much better than having to deal with dependency issues
English

@yacineMTB I love it when my CLI tools are 500mb and come bundled with a fucking browser runtime.
English


⁉️So get this, AMD is making a bold move to own the affordable personal inferencing market by launching a Mini PC in June, a 128GB Shared Memory Inferencing Box
🎇 They call it the ⬭ Halo Box.
🧾 It's a Ryzen AI MAX+ 395 (16 Zen 5 cores + 40 RDNA 3.5 CUs + XDNA 2 NPU)
✅ Up to 128GB LPDDR5X-8533 unified memory
✅ Full ROCm support + Day-0 AI model optimization
🧪 Built for local AI development (up to ~200B param models)
📈 Direct shot at NVIDIA’s $4,699 DGX Spark and could cost $2,000–$3,000 (as they do now)
🤔 Why launch now during the RAM shortage?
While memory makers divert capacity to HBM for AI data centers (driving LPDDR5X prices to spike and NVIDIA to raise the price of DGX Spark by $700), AMD is making a bold move to own the affordable, high-memory AI mini-PC segment before the crisis worsens.
💡 My Speculation: AMD could be using its contracts, relationships, and strategic priority to secure better memory access than many traditional OEMs. This could give them an advantage in launching the Halo Box during the shortage.
Smart timing or risky bet?
🔥 This is AMD aggressively fighting for the local AI developer market.

English
English

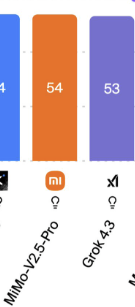

xAI has launched Grok 4.3, achieving 53 on the Artificial Analysis Intelligence Index with improved agentic performance, ~40% lower input price, and ~60% lower output price than Grok 4.20
The release of Grok 4.3 places @xAI just above Muse Spark and Claude Sonnet 4.6 on the Intelligence Index, and a 4 points ahead of the latest version of Grok 4.20. Grok 4.3 improves its Artificial Analysis Intelligence Index score while reducing cost to run the benchmark suite.
Key Takeaways:
➤ Grok 4.3 improves on cost-per-intelligence relative to Grok 4.20 0309 v2: it scores higher on the Intelligence Index while costing less to run the full benchmark suite. Grok 4.3 costs $395 to run the Artificial Analysis Intelligence Index, around 20% lower than Grok 4.20 0309 v2, despite using more output tokens. This makes it one of the lower-cost models at its intelligence level
➤ Large increase in real world agentic task performance: The largest single benchmark improvement is on GDPval-AA, where Grok 4.3 scores an ELO of 1500, up 321 points from Grok 4.20 0309 v2’s score of 1179 Grok 4.3, surpassing Gemini 3.1 Pro Preview, Muse Spark, Gpt-5.4 mini (xhigh), and Kimi K2.5. Grok 4.3 narrows the gap to the leading model on GDPval-AA, but still trails GPT-5.5 (xhigh) by 276 Elo points, with an expected win rate of ~17% against GPT-5.5 (xhigh) under the standard Elo formula
➤ Grok 4.3’s performs strongly on instruction following and agentic customer support tasks. It gains 5 points on 𝜏²-Bench Telecom to reach 98%, in line with GLM-5.1. Grok 4.3 maintains an 81% IFBench score from Grok 4.20 0309 v2
➤ Gains 8 points on AA-Omniscience Accuracy, but at the cost of lower AA-Omniscience Non-Hallucination Rate of 8 points, so Grok 4.20 0309 v2 still leads AA-Omniscience Non-Hallucination Rate, followed by MiMo-V2.5-Pro, in line with Grok 4.3
Congratulations to @xAI and @elonmusk on the impressive release!

English

I get people dunking on Mistral, but if you are in Europe looking at this: does your agentic deployment need frontier capability of Claude, 'cause that inference bill will be insane.
so, then you pick a Chinese model that may or may not be marginally better in some verticals?
Matej Sirovatka@m_sirovatka
sometimes I wonder if being poor in sf is worth over being rich in europe, thx to mistral for helping me decide
English



@ThiccQuidity @Hedgeye they're for living, not speculation. other financial instruments are better for speculation
English

@Hedgeye imagine buying a house, and 20 years later it’s worth as much as the day you bought it
English



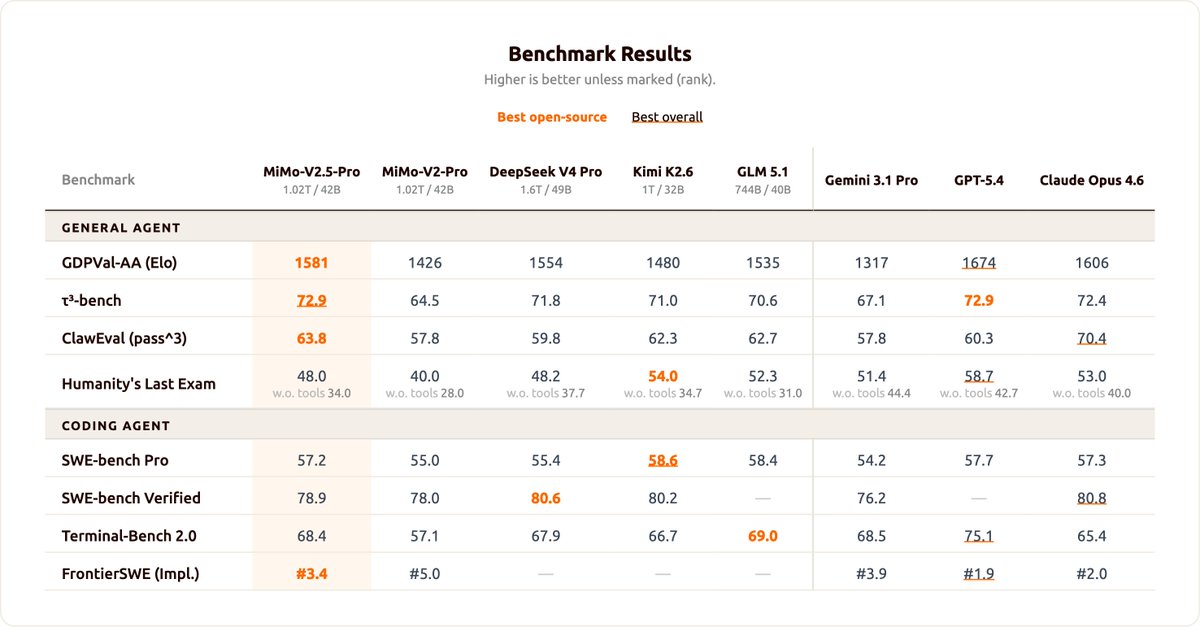
Xiaomi MiMo-V2.5 is now officially open-sourced!
MIT License, supporting commercial deployment, continued training, and fine-tuning - no additional authorization required.
Two models, both supporting a 1M-token context window :
• MiMo-V2.5-Pro: built for complex agent and coding tasks, ranking No.1 among open-source models on GDPVal-AA and ClawEval
• MiMo-V2.5: a native omni-modal model with strong agent capabilities
A model's value isn't measured by rankings alone — it's measured by the problems it solves.
Let's build with MiMo now!
🤗 Weights: huggingface.co/collections/Xi…
📄 Blog: #blog" target="_blank" rel="nofollow noopener">mimo.xiaomi.com/index#blog

English