
@TheTopRepost @Polymarket helium, energy, and legal push back from communities
English
zeo
12.5K posts

@zeo_gee
// dev, mystery, conspiracy, and memes //








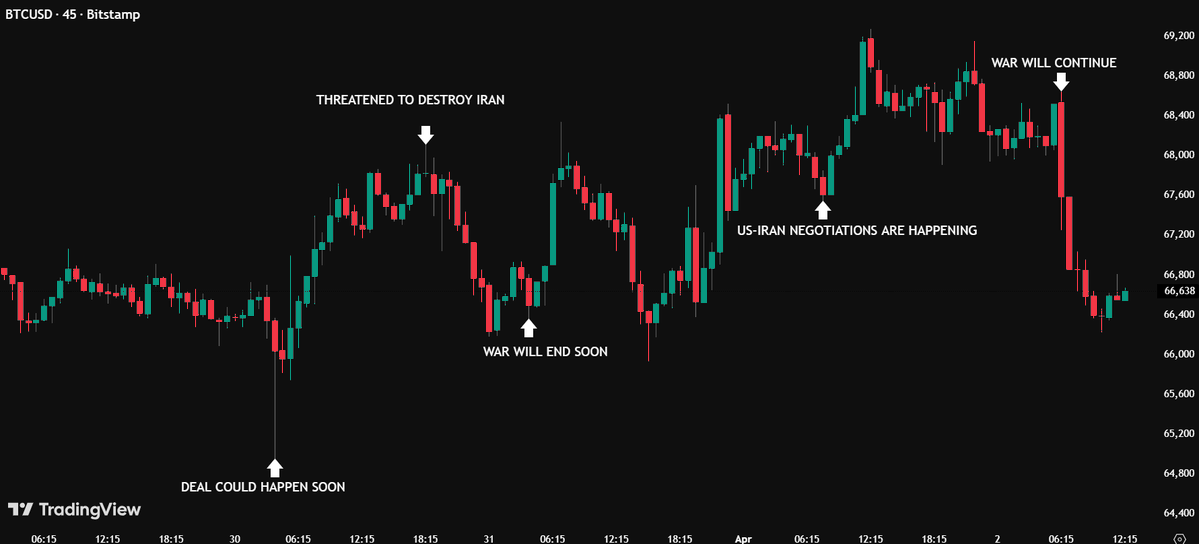
According to @axios "Iran mediators are making a last-ditch push for a 45 day ceasefire." Yet Reuters couldn't verify the report. LOL. The state of Western media right now.






A U.S. CH-47 Chinook helicopter has reportedly been destroyed by an Iranian drone in Kuwait.







Gulf states consider new pipelines to avoid Strait of Hormuz ft.trib.al/OJL9g4d






i've been working on a method called autoreason that is effectively autoresearch extended to subjective domains. autoresearch works because val_bpb gives you an objective fitness function. autoreason constructs a subjective one through independent blind evaluation, the same way science uses peer review where math can use proofs. as you’ve noted, the fundamental problem with using LLMs for iterative refinement on subjective work: the model is always sycophantic when you ask it to improve something, overly critical when you ask it to find flaws, and overly compromising when you ask it to merge two perspectives. the output ends up shaped more by how you prompt than by what's actually better. autoreason fixes this by separating every role into isolated agents with no shared context. you start by generating version A. a fresh agent attacks it as a strawman. a separate author who only sees the original task, version A, and the strawman critique produces version B. a third agent who has no history with either drafting process sees both versions as equal inputs and synthesizes them into version AB. a blind judge panel with fresh context and randomized labels picks the strongest of A, B, or AB. the winner becomes the new A and the loop repeats until the judges consistently pick the incumbent which indicates that no further changes are needed.



