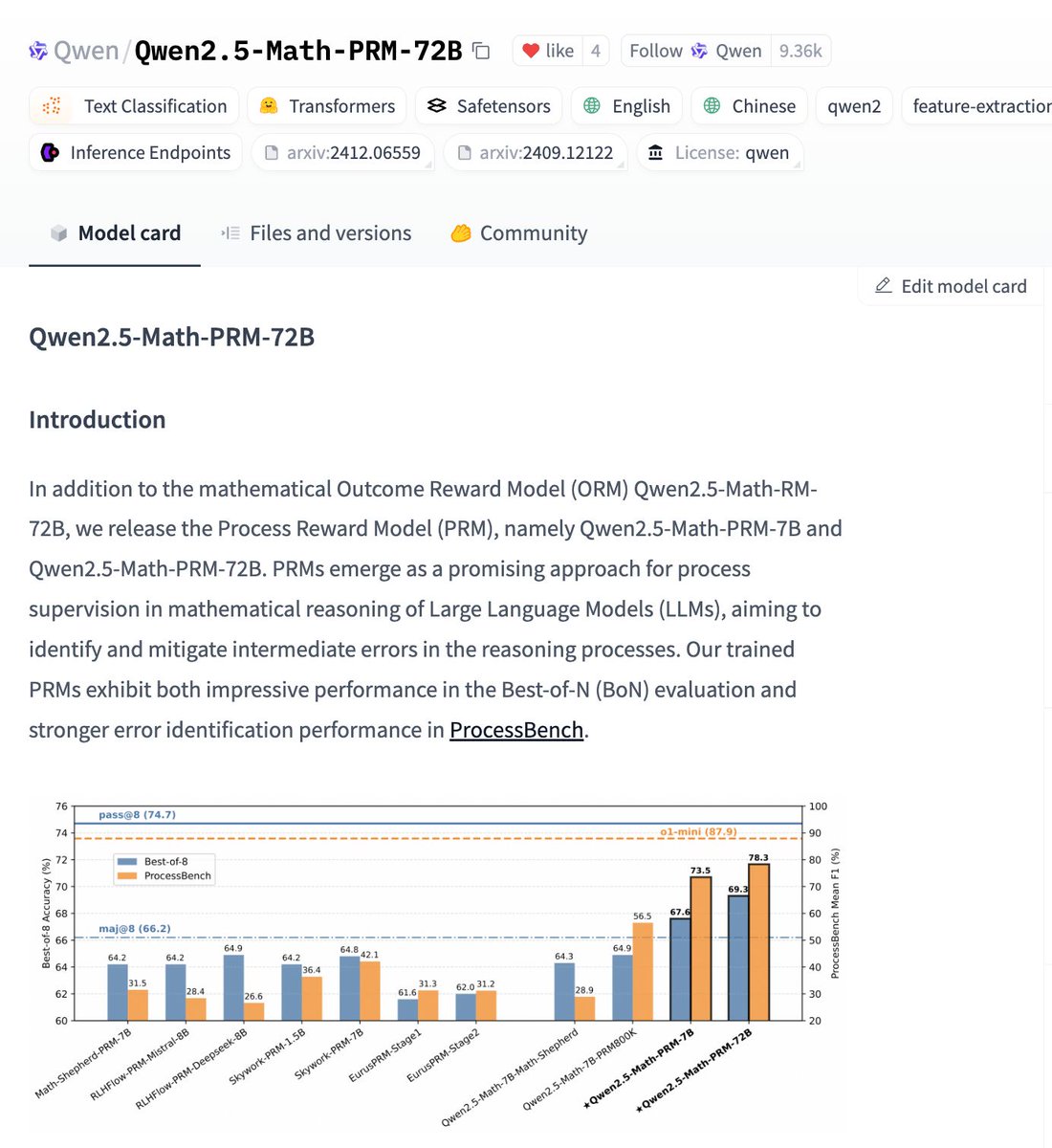
Lex Fridman@lexfridman
Here's my 5-hour conversation with @dylan522p and @natolambert on DeepSeek, China, OpenAI, NVIDIA, xAI, Google, Anthropic, Meta, Microsoft, TSMC, Stargate, megacluster buildouts, RL, reasoning, and a lot of other topics at the cutting edge of AI. This is was a mind-blowing, super-technical, and fun conversation.
Yes, we discuss r1 and o3-mini, but more importantly we look into the future of technology, geopolitics, and humanity in a world that stands on the precipice of a global AI revolution.
The first 4 hours are here on X (4 hours is current limit), and the full 5 hours are up everywhere else. Links in comment.
Timestamps:
0:00 - Introduction
3:33 - DeepSeek-R1 and DeepSeek-V3
25:07 - Low cost of training
51:25 - DeepSeek compute cluster
58:57 - Export controls on GPUs to China
1:09:16 - AGI timeline
1:18:41 - China's manufacturing capacity
1:26:36 - Cold war with China
1:31:05 - TSMC and Taiwan
1:54:44 - Best GPUs for AI
2:09:36 - Why DeepSeek is so cheap
2:22:55 - Espionage
2:31:57 - Censorship
2:44:52 - Andrej Karpathy and magic of RL
2:55:23 - OpenAI o3-mini vs DeepSeek r1
3:14:31 - NVIDIA
3:18:58 - GPU smuggling
3:25:36 - DeepSeek training on OpenAI data
3:36:04 - AI megaclusters
4:11:26 - Who wins the race to AGI?
4:21:39 - AI agents
4:30:21 - Programming and AI
4:37:49 - Open source
4:47:01 - Stargate
4:54:30 - Future of AI