@Teknium @plastic_lab @mem0ai @openvikingai @Vectorizeio @retaindb @ByteroverDev What’s the pricing comparative of those, has anyone looked at it?
English
InternationalOptions
513 posts




@TheAhmadOsman should we secure GPUs or is a Mac Studio 512gb enough?


Sundar Pichai (@sundarpichai), CEO of @Google and Alphabet Inc. and a Stanford alum, will return to the Farm to deliver Stanford’s 135th Commencement address. 🗞️: stanford.io/4sIVtTK


BIG DAY! Qwopus 27B v3 is LIVE from Jackrong! This is the third iteration from the line of the viral finetunes previously titled “Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled” It is now simply Qwopus 27B and I love the name change! On paper, the v3 is another remarkable improvement over v2! Most impressively it is the first model of the series that outperforms the base on HumanEval! And retains significant efficiency increases when thinking than the base Qwen 27b! According to tests by @stevibe the V2 version was already performing very closely to the base model in bug finding and tool calling. V3 should exceed it! In my own tests, V2 was the best front end design local model I’ve ever ran on a single GPU! And the efficiency improvements made it much more usable at long contexts, where base Qwen would think forever! I will be running full analysis on the v3 today in Hermes agent and I am very optimistic! I have also had correspondence directly with Jackrong, and he is incredibly grateful for all of the support we’ve sent his way! The man is a genius and pouring a lot of time and effort into this work, so keep the downloads going and let us know your thoughts in the comments! We’ve exchanged contact info so we can keep up the feedback and momentum! If you get a second, we’d love to see your tests! Let us know how it works for your use case and first impressions, and if you have any issues I will do my best to help out in the comments! GGUF here and MLX in thread! huggingface.co/Jackrong/Qwopu…


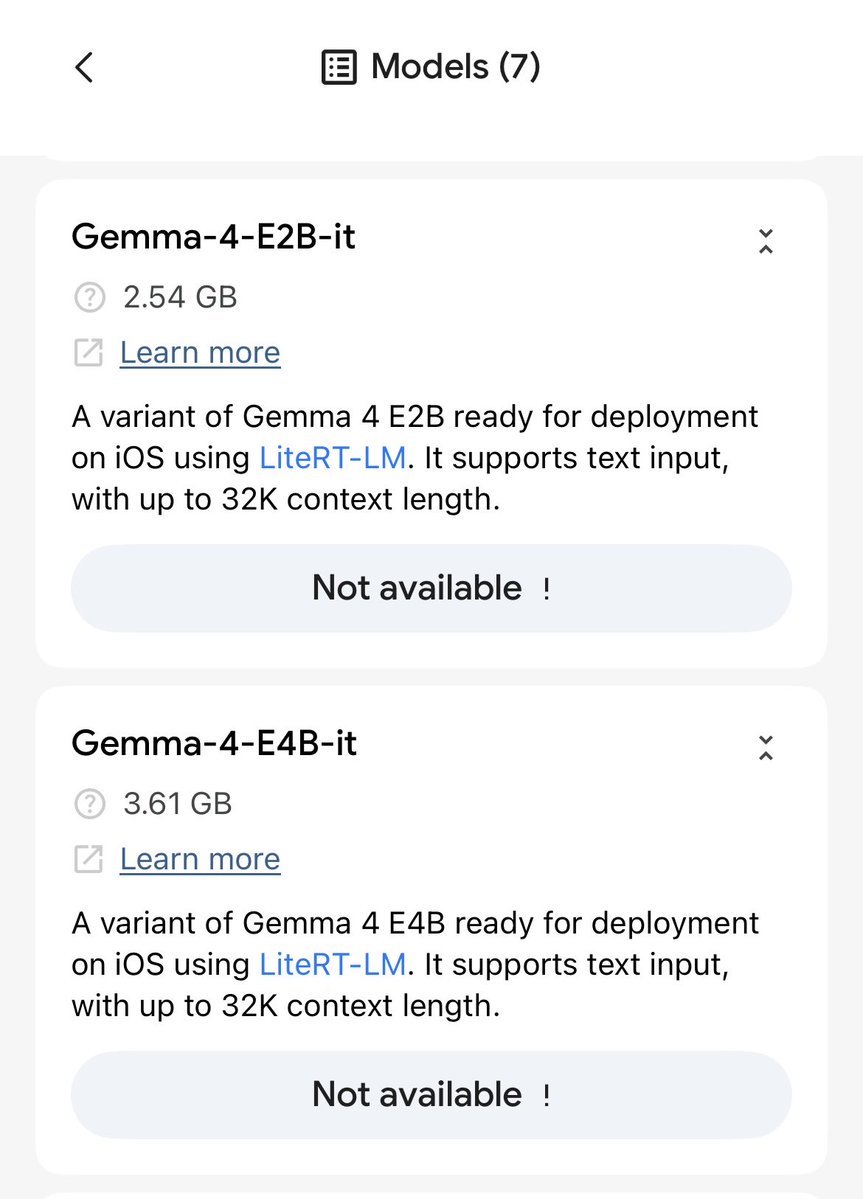


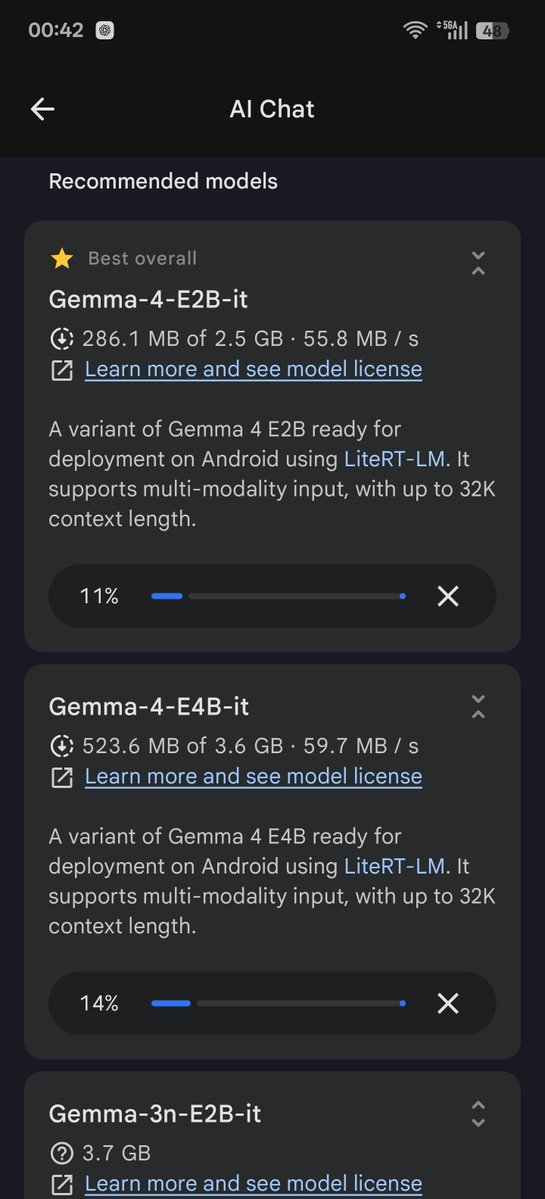





Meet Gemma 4: our new family of open models you can run on your own hardware. Built for advanced reasoning and agentic workflows, we’re releasing them under an Apache 2.0 license. Here’s what’s new 🧵




Introducing Gemma 4, our series of open weight (Apache 2.0 licensed) models, which are byte for byte the most capable open models in the world! Gemma 4 is build to run on your hardware: phones, laptops, and desktops. Frontier intelligence with a 26B MOE and a 31B Dense model!