
Deeju
767 posts

Dans la bulle X que je lis, on l'a vu venir.
Le reste de la population n'a aucune idée de la vélocité avec laquelle une révolution civilisationnelle est en train de se produire.
L'impact de Claude 4.5 c'est rien à côté de ce qui nous attend.
VISION IA@vision_ia
Ceux qui travaillent dans des métiers manuels disent encore qu'ils ne seront jamais remplacés... voyez plutôt ce qui suit. La Chine est en train de construire des usines à données pour robots. À une échelle que personne n'avait anticipée. Ce que vous voyez sur cette vidéo : des rangées d'opérateurs humains équipés de casques VR et de contrôleurs, qui téléopèrent des robots humanoïdes en temps réel. Chaque geste est capturé, enregistré, puis envoyé dans le cloud pour entraîner l'IA. C'est comme ça que les robots apprennent. Pas en lisant du code. En copiant des humains (tant que les modèles monde ne seront pas opérationnels). Le plus grand centre de ce type vient d'ouvrir dans le Sichuan, à Zigong. 6 000 m². Objectif : 15 000 données d'entraînement par jour. 3 millions d'entrées de haute qualité par an. Un nouveau métier est né : "entraîneur de robots IA". Les opérateurs portent des casques VR, leurs mouvements sont répliqués en temps réel par les robots Walker S2. Tri de colis, préparation de café, ménage. Tâche après tâche, le robot accumule des milliers de trajectoires de données par session. Pourquoi c'est crucial : la Chine compte plus de 140 fabricants de robots humanoïdes et plus de 330 modèles différents. Le goulot d'étranglement n'est plus le hardware. C'est la donnée. Et la Chine résout ce problème par la force brute : des centaines de travailleurs dans des centres géants qui font des tâches banales pendant des heures. Les ouvriers se surnomment eux-mêmes "cyber-travailleurs". Parallèlement, le 29 mars, la première ligne de production automatisée de robots humanoïdes en Chine a démarré dans le Guangdong. Capacité : 10 000 unités par an. Un robot sort de la chaîne toutes les 30 minutes. Goldman Sachs estime le marché mondial des robots humanoïdes à 38 milliards de dollars d'ici 2035. Pendant que l'Occident débat de l'IA ... la Chine entraîne des armées de robots. Littéralement. La prochaine révolution ne s'écrit pas en lignes de code. Elle s'apprend par imitation. Et elle a déjà commencé.
Français

Tes parents quand t’étais au collège : "Il faut que t'ai des bonnes notes pour faire un bac général et un master 2 si tu veux pas finir pauvre"
Ton pote Donovan, lui il fumait du tcherno à 13 ans, il avait redoublé et fini en CAP chaudronnerie.
Aujourd’hui il gagne 4x ton salaire en faisant des travaux d’aménagement chez des boomers multipropriétaires qui payent au black.
Alors que toi t’es resté dans le rang, en CDD dans une boîte de branleurs de la French Tech (subventionnée par la BPI).
Tu travailles 60 heures par semaine parce que Thibault, ton manager gominé qui s’est récemment mis à l’Hyrox, t’a annoncé lors de ton bilan mid-term "ici on a l’esprit startup comme à Palo Alto".
Lundi matin, pose café : après t’avoir raconté son after en appart à Aubervilliers, Jean, le responsable de "l’optimisation des performances opérationnelles", t’annonce avec enthousiasme que ton contrat ne sera pas reconduit car ils ont automatisé tes tâches de veille stratégique avec un bot Openclow.
Selon lui "c’est la tendance du marché".
Il te met une petite tape cordiale sur l’épaule et enchaîne sur le potager hydroponique qui vient d’être installé sur le toit de son immeuble.
T’as encore 40 000 euros de prêt étudiant sur le dos, un appart à 1600 balles par mois à Père-Lachaise et toutes les compétences que t’as acquises en MBA strategic growth sont automatisables avec 200€ de tokens Claude.
Bref, t’aurais ptetre dû aller fumer des pilons avec Dono.
Français

@Mayuu_France jsp de quel type d’effort tu me parles
t’es sur de parler de claude code ?
Français
ceux qui atteignent la limite claude code avec le forfait à 200€ faut en parler
vraiment vous avez 5 de QI
je vous vois comme des lapins crétins qui forcent des carrés dans des triangles
j’ai Opus 4.6 qui tourne 24/24 et je fais même pas 40%
bossez votre context engineering
Français
@Type314628437 je suis pas là pour aider les gens
mais pour éveiller les consciences
Français
Deeju retweetou

Cinematique is live 🔥 A FREE prompt guide for AI filmmakers. > 150+ cinematic techniques with video demos, built on grokfilm.app by @tetsuocorp.
vvsvs.pro/cinematique
> Copy a prompt,replace [Subject], generate. Made to accelerate your creative AI workflow.
All images and video generated with Grok @imagine via their API.
Special thanks to @tetsuoai for allowing me to build this for the people!
English
Deeju retweetou

🚨 AHORA CLAUDIO TE BUSCA EMPLEO
Se llama Career-Ops (hecho con Claude Code) por @santifier y es una locura:
- Escanea vacantes de +45 empresas top (OpenAI, Anthropic, Stripe, ElevenLabs...).
- Reescribe tu CV perfecto para cada puesto.
- Genera PDFs optimizados para ATS con Playwright.
- Llena los formularios solo.
- 14 modos/skills + dashboard brutal en Go.
El futuro de buscar trabajo ya está aquí y es open source.
REPOOO👇
Español
- A tech guy (yes, you still need one)
- A data-driven guy
- A sales and communications guy.
Shared product vision and that's the boom
That's all you need.
Ronin@DeRonin_
I generate 200+ qualified leads per week and never send a single cold DM the secret: a lead generation skill graph 30+ markdown files wired together that turned my AI agent into a full sales team where it runs: - claude as the AI brain (reads the graph, executes every step) - n8n as the automation backbone (triggers, webhooks, scheduling) - a folder of .md files as the system (no fancy tools needed) the folder structure: /lead-gen-skill-graph ├── index.md (entry point — maps the entire pipeline) ├── content/ │ ├── pillars.md (3-5 core topics that attract your ICP) │ ├── hooks.md (scroll-stopping openers by platform) │ └── cta-playbook.md (which CTA to use where and why) ├── magnets/ │ ├── lead-magnets.md (free resources that capture interest) │ ├── dm-triggers.md (comment keywords → auto-DM sequences) │ └── landing-pages.md (conversion copy frameworks) ├── nurture/ │ ├── dm-flows.md (full DM conversation sequences by platform) │ ├── segmentation.md (tag leads by intent, behavior, stage) │ └── redirect.md (when to move from X/LinkedIn → WhatsApp/Telegram) ├── conversion/ │ ├── offer-stack.md (what you sell, at what price, to whom) │ ├── objections.md (every "no" mapped to a response) │ └── close-scripts.md (DM closes on-platform + messenger closes) └── audience/ ├── icp.md (ideal customer profile — specific, not vague) └── stages.md (cold → warm → hot → buyer journey) each file = one knowledge node inside each file you add [[wikilinks]] to related nodes example: inside dm-triggers.md: "when someone comments [keyword] on a post from [[pillars]], send them [[lead-magnets]] via DM. use tone from [[dm-flows]]. tag them in [[segmentation]] as 'engaged-warm'. if they reply, continue the [[dm-flows]] nurture sequence. match [[icp]] before any outreach" the agent reads one file → follows the links → executes the full pipeline without you touching anything the key file is index.md — your command center put 3 things in it: 1. who you are + what this system does "lead generation system for [your brand]. turns content into qualified leads and closes them via DMs on autopilot across X, LinkedIn, WhatsApp, and Telegram" 2. the node map with context - [[pillars]] — 3-5 content themes that attract buyers, not just followers - [[hooks]] — platform-specific openers, updated weekly - [[cta-playbook]] — "comment X" vs "DM me" vs "link in bio" logic - [[dm-triggers]] — keyword detection → automated first touch - [[lead-magnets]] — free resources matched to each funnel stage - [[dm-flows]] — full DM nurture sequences, platform-native tone - [[segmentation]] — cold/warm/hot tagging + behavior-based routing - [[redirect]] — rules for when to move conversation to WhatsApp/Telegram - [[offer-stack]] — products mapped to lead temperature - [[objections]] — pre-written responses to every common pushback - [[close-scripts]] — DM close on X/LinkedIn, messenger close on WhatsApp/Telegram 3. execution instructions "when given a content topic: check [[pillars]] for alignment. write post using [[hooks]] + [[cta-playbook]]. set [[dm-triggers]] for engagement capture. route new leads through [[segmentation]] → [[dm-flows]]. when lead hits 'hot' → check [[redirect]] for platform routing → deploy [[close-scripts]] with [[objections]] handling" here's what makes this different from a basic funnel: it's NOT a linear pipeline where everyone gets the same 5 messages it's a graph where every lead gets routed based on how they entered and what they did next > commented on X post → DM with lead magnet → replied → DM nurture flow → showed buying intent → close in X DMs > engaged on LinkedIn → DM with case study → asked about pricing → redirect to WhatsApp → close on WhatsApp > DM'd you directly on X → skip nurture → qualifying questions → offer stack → close in Telegram same offer. different path, timing, tone, and platform per lead the graph encodes all those rules. claude reads them. n8n executes them the n8n part: - webhook triggers when someone comments a keyword - claude reads the graph → decides which node to execute - n8n sends the DM, tags the lead, routes to the next step - when a lead goes hot → n8n handles the redirect to WhatsApp/Telegram - every action loops back into the graph for the next decision you build the intelligence in .md files you build the automation in n8n claude is the bridge between thinking and doing this replaced my $3-5k/mo in lead gen tools and a part-time VA one folder of markdown files + one AI agent + one automation tool = infinite lead engine however, currently I am building even smarter system by covering full closing cycle, with 100% personalized approach & process of the lead there's no more pre-made funnels, but absolutely unique once specifically for each lead yeah, that's what exactly we do in Close AI and currently we're opening "Whitelist" stage we provide to you a full-ready for implementation system, you just pay basic costs of our spends (with no extra charge from our side) if you're interesting in, apply here: forms.gle/VX55roCUeh3mLo… study this. save it so you don't lose it ❤️
English

Deeju retweetou

Anthropic s'en tape du cash des particuliers vibecoders et utilisateurs Openclaw, ils n'en ont pas besoin.
Et tant mieux ça fait tourner ce petit volume sur d'autres Labo pour renforcer leurs offres et diversifier un peu le marché.
Personne ne veut un seul Labo tout puissant.
Français
Deeju retweetou

🧬 Une seule injection dans l’oreille interne et une enfant de 7 ans entend sa mère pour la première fois - 4 mois plus tard elle tient une conversation normale. C’est une thérapie génique, c’est publié dans Nature Medicine cette semaine.
Les mêmes qui ont passé 30 ans à nous expliquer qu’on ne devait pas « manipuler les gènes » dans le maïs applaudissent-ils ? Ou gardent-ils le même silence gêné qu’à chaque fois que la génétique sauve des vies au lieu de remplir une usine Monsanto imaginaire ?
Maryse Arditi, cadre des Verts, était scientifique de formation… et a quand même porté une motion au Conseil national contre le financement du Genopole d’Évry. Pas contre un modèle économique. Contre la recherche en génétique. La cohérence est au moins là.
Le problème n’a jamais été la sécurité. C’était l’idéologie. Une « admiration mystique d’une nature bienveillante » - c’est Yves Bréchet membre de l’Académie des sciences qui le dit, pas moi.
La nature bienveillante laissait cette enfant sourde. La science l’a fait entendre.
Chubby♨️@kimmonismus
1/ Insane: A single injection into the inner ear reversed deafness in all ten patients. Some started hearing again within weeks. Gene therapy just crossed a threshold we thought was still years away. Lets dig into this breakthrough and how it works 🧵
Français

Voici c'est quoi 166 token/s sur une NVIDIA RTX 5090 sur Gemma4 , avec le modele 26B - 8 bits (qui est à mon sens largement ok!)
Regardez la vitesse svp. On est en avril 2026 et on a ce niveau de LLM en local à une vitesse incroyable. Je suis vraiment trop heureux. Imaginez fin 2026 on en sera où. Ca fait tellement plaisir.
Vive les modèles open-weights ! Maintenant je vais le tester sur de l'agentique, du formating json etc...
PS : Tout mon mini lab là, avec l'interface, le TTS , la camera etc c'est dispo sur mon git, servez vous (React front + back python).
Français
Deeju retweetou

Claude is not allowed to write outside the workspace.
But it wanted to.
So Claude wrote a python script and executed it via bash to modify the file essentially hacking my permissions.

English
Deeju retweetou

Deeju retweetou

I don't know what the fuss is about. Anthropic's rules on using subscriptions are very simple:
Claude Code = OK
Claude's online platform = OK
Agent SDK running in personal software = OK... ish?
Agent SDK running in commercial software = NOT OK
Claude Code running in CI = ??
Oh, maybe it's not so simple...
Agent SDK running in CI = ??
claude -p running in CI = ??
claude -p running in personal software = OK
claude -p running on open source software, but run on my personal computer = ??
claude -p running on distributed sandboxes, kicked off by me = ??
Distributing open source software which relies on claude -p, and documenting how to use your subscription with it = ??
A thousand other edge cases = ??
Let me be clear. I have never before experienced, from any developer tool, such a frustrating lack of clarity over the basic terms of usage.
I personally asked, 3 weeks ago, and have received nothing but delays. The recent @bcherny announcement did absolutely nothing to clarify things.
I say this as someone who just released a Claude Code course - my incentives all align with supporting Anthropic.
Boris Cherny@bcherny
@EricBuess Yep, working on improving clarity here to make it more explicit
English
Elle a raison, et nous aussi.
Moi je dis allons y quoi
Marie Fernet@MarieFernet
@nb4ld Le truc est la: vous prétendez remplacer les avocats sur des dossiers qu’on ne prend pas parce que ça rapporte pas. Ben parfait. Allez y.
Français
@iamsupersocks Toujours un plaisir un papier de supersocks pour suivre l'actualité trop riche de l'IA de loin avec des explications claires. Merci !
Français
C'est intéressant d'aller plus loin sur l'évaluation de Stanford.
On le rappelle : le harness, c’est le code d’orchestration autour d’un modèle fixe. Au sens du papier de Stanford, c’est le code qui décide ce que le modèle voit, stocke et récupère à chaque étape.
Ils ont testé Meta-Harness sur trois domaines très différents, ce qui permet de comprendre pas mal de choses sur le comportement des LLM et leur association avec des harnesses comme Claude Code par exemple.
Meta pour optimisation, pas de lien avec Zuck.
Et le résultat parle : Meta-Harness découvre un harness qui bat le meilleur design humain de 7,7 points de précision en utilisant 4 fois moins de contexte.
Face aux meilleurs optimiseurs automatiques existants, il atteint leur performance finale en 4 évaluations au lieu de 60, puis continue à progresser et finit 10 points au-dessus.
Et sur 9 jeux de données jamais vus pendant la recherche, le harness découvert généralise : 73,1 % de précision moyenne contre 70,2 % pour le meilleur concurrent. Il n'a pas triché il a appris quelque chose de transférable.
Raisonnement mathématique niveau IMO. Stanford a donné à Meta-Harness un corpus de 535 000 problèmes de maths résolus et lui a demandé de trouver une meilleure façon de chercher des exemples utiles pour résoudre des problèmes de niveau Olympiades internationales.
Après 40 itérations, l'agent découvre tout seul qu'il faut traiter chaque type de problème différemment.
Il construit un système à quatre voies : les problèmes de combinatoire, de géométrie, de théorie des nombres et le reste passent chacun par une stratégie de recherche d'exemples différente avec des critères de tri, de filtrage et de sélection spécifiques à chaque famille.
Personne n'a designé ce routeur. L'agent l'a découvert en lisant les traces d'échec et en itérant sur ce qui cassait.
Le résultat : un seul harness découvert améliore la précision de 4,7 points en moyenne sur 200 problèmes IMO-level, testé sur 5 modèles qui n'avaient jamais été vus pendant la recherche : GPT-5.4-nano, GPT-5.4-mini, Gemini-3.1-Flash-Lite, Gemini-3-Flash, et GPT-OSS-20B. Le harness transfère entre modèles.
-> Un harness optimisé sur un modèle bénéficie directement à d'autres.
Coding agent sur TerminalBench-2. C'est un benchmark de 89 tâches complexes pour agents autonomes et c'est un benchmark activement contesté où plusieurs équipes poussent leurs scores en continu.
Le harness découvert par Meta-Harness se classe #1 parmi tous les agents Haiku 4.5 et #2 parmi tous les agents Opus 4.6, battant tous les agents hand-engineered dont le code est reproductible.
Comment l'agent raisonne : l'exemple TerminalBench-2
Les chiffres, c’est une chose. Ce qui rend ce papier différent des benchmarks classiques, où il se positionne déjà très bien sur le coding agent de TerminalBench-2 c'est qu'on peut obsrver comment l'agent pense.
L'appendice détaille sa trajectoire de recherche, itération par itération.
Itérations 1-2.
L'agent essaie de corriger des bugs structurels et de réécrire le prompt en même temps. Les deux tentatives régressent fortement.
Itération 3.
Le moment clé -> l'agent relit les logs des deux échecs. Il remarque que les corrections structurelles étaient différentes à chaque fois, mais que la réécriture de prompt était la même.
Il en déduit que c'est le prompt le coupable, pas les corrections.
Il isole les corrections, les teste sans le nouveau prompt, et la régression diminue.
C'est du raisonnement causal : identifier une variable confondante, formuler une hypothèse, tester.
Itérations 4-6.
L'agent continue d'explorer des modifications du prompt et du flux de contrôle. Chaque tentative régresse. Leçon accumulée : toucher au prompt est risqué.
Itération 7.
Le pivot. L'agent change d'approche. Au lieu de modifier quoi que ce soit d'existant, il ajoute juste une information en amont : un snapshot de l'environnement (langages installés, paquets disponibles, fichiers présents). 80 lignes de code. Purement additif.
C'est ce candidat qui gagne.
L'agent explique lui-même pourquoi : ça ne touche pas aux parties fragiles, et ça élimine les tours gaspillés en exploration au début des tâches.
Ce n'est pas de la mutation aléatoire. C'est un ingénieur qui a fait 6 tentatives, compris pourquoi elles échouaient, et changé d'approche. Sauf que l'ingénieur est un agent qui lit du code et des logs.
Ce que ça veut dire concrètement.
Le modèle n'est plus le seul différenciateur. Si un changement de harness peut produire un écart de 6x sur le même benchmark, alors passer des heures à comparer Opus vs GPT-5 vs Gemini sans soigner l'orchestration autour, c'est optimiser la mauvaise variable. Le code qui entoure le modèle : comment tu construis le contexte, ce que tu stockes, quand tu récupères, comment tu gères les tours ça pèse au moins autant que les poids du modèle.
Le harness transfère entre modèles. C'est le résultat maths qui le montre le plus clairement.
Un harness optimisé sur GPT-OSS-20B améliore directement GPT-5.4-nano, Gemini-3-Flash, et trois autres modèles jamais vus.
Si tu tournes des modèles locaux : des 7B, 13B, 34B, un bon harness optimisé sur un modèle frontier peut directement booster tes performances.
C'est probablement une des meilleures nouvelles de l'année pour l'écosystème open-source et local.
L'automatisation est déjà praticable. L'équipe note que ce workflow n'est devenu possible que début 2026, grâce aux progrès récents des coding agents.
Une run de recherche prend quelques heures et produit des harnesses lisibles, transférables, réutilisables. Le coût marginal du bon harness est en train de s'effondrer.
Le harness engineering va devenir un standard. Il y a un an, "prompt engineering" était la compétence rare.
Le harness engineering va prendre cette place, avec une différence : il est automatisable.
Les équipes qui intègrent des boucles d'optimisation de harness dans leur pipeline vont avoir un avantage structurel sur celles qui itèrent encore à la main.
Les limites:
Il faut rester honnête. Meta-Harness a été testé avec un seul agent proposeur (Claude Code + Opus 4.6). On ne sait pas comment ça se comporte avec d'autres coding agents c'est une variable importante et opus fait partie des plus compétents : plus le proposer est fort, plus le harness qu’il découvre est bon.
Le coût computationnel est réel : jusqu'à 10 millions de tokens de contexte par évaluation.
Sur TerminalBench-2, la recherche et l'évaluation se font sur le même benchmark (89 tâches), ce qui est standard dans cet écosystème mais limite les conclusions sur la généralisation dans ce domaine spécifique contrairement aux résultats texte et maths où la généralisation est testée proprement.
Les harnesses découverts sont aussi spécialisés par domaine. Meta-Harness ne produit pas un "harness universel" il optimise un harness pour une tâche donnée. C'est cohérent avec ses résultats (le routeur maths à 4 voies est très spécifique), mais ça veut dire qu'il faut relancer la recherche pour chaque nouveau domaine.
Pendant cinq ans, l'industrie IA a concentré son attention sur les modèles. Quel modèle est le plus gros, le plus rapide, le meilleur sur tel benchmark. Stanford vient de montrer que le code autour du modèle (le harness) compte tout autant.
Qu'un agent peut automatiquement trouver de meilleurs harnesses que les ingénieurs humains. Et que la clé, c'est l'accès aux traces brutes complètes, pas aux résumés.
C'est le genre de résultat qui ne fait pas de bruit sur les réseaux parce qu'il n'y a pas de nouveau modèle à annoncer. Mais c'est exactement le genre de papier qui change notre perception pour construire des systèmes IA.
Supersocks@iamsupersocks
Le harness, pas le modèle : Stanford vient de montrer où se joue vraiment la performance IA Voilà un article qui n'est pas du réchauffé. On entend beaucoup parler de harness engineering ces derniers mois. Le terme revient dans les blogs d'Anthropic, d'OpenAI, chez Martin Fowler, et même jusque sur la timeline du tweet FR. Mais jusqu'ici c'était surtout de l'intuition de praticien : "ouais, le code autour du modèle compte énormément". Tout le monde le sentait, personne ne l'avait vraiment formalisé ni prouvé à grande échelle. Stanford vient de le faire. Et les résultats donnent une perspective très différente de ce qu'on lit d'habitude sur les benchmarks de modèles. Le papier s'appelle Meta-Harness: End-to-End Optimization of Model Harnesses. Publié le 30 mars 2026 par Yoonho Lee, Chelsea Finn, Omar Khattab (MIT) et une équipe Stanford/KRAFTON. Ce qu'ils montrent tient en une phrase : le plus gros levier de performance dans un système IA aujourd'hui, ce n'est pas le modèle : c'est le code autour du modèle. Et ce code peut maintenant être optimisé automatiquement, mieux que ne le font les humains. Commençons par le début : c'est quoi un harness Si tu utilises un LLM dans un produit, un agent, un pipeline tu as un harness. Même si tu ne l'appelles pas comme ça. Le harness, c'est tout le code qui entoure le modèle et qui décide : -> Ce que le modèle voit à chaque étape (quel contexte on lui envoie) -> Ce qu'on stocke en mémoire entre les appels -> Ce qu'on récupère et quand (retrieval, RAG, exemples few-shot) -> Comment on construit le prompt à chaque tour -> Ce qu'on fait de la réponse du modèle avant le tour suivant Concrètement : le system prompt, la logique de RAG, la gestion de mémoire, l'orchestration agent, le choix des outils, le formatage des résultats tout ça c'est du harness. Et le point central du papier : tu prends le même modèle, les mêmes poids, tu changes uniquement le harness, et tu peux observer un écart de performance allant jusqu'à 6x sur le même benchmark. Six fois. Même modèle. C'est un chiffre qu'on retrouve dans la littérature (SWE-Bench Mobile, entre autres), mais que l'industrie a tendance à ignorer parce que toute l'attention va aux annonces de nouveaux modèles. Stanford remet ce fait au centre. Le problème : le harness engineering est encore artisanal. Aujourd'hui, optimiser un harness c'est un processus manuel. C'est un peu comme régler un moteur à l'oreille : tu testes, tu écoutes, tu tournes une vis, tu retestes. Sauf que là c'est du code, chaque test coûte du compute, et tout repose sur l'expérience de l'ingénieur qui tourne les vis. Il existe des méthodes automatiques pour optimiser des "artefacts texte" : des prompts, des templates. OPRO, TextGrad, AlphaEvolve/OpenEvolve, GEPA, TTT-Discover. Mais ces méthodes ont toutes le même défaut : elles compriment le feedback. Certaines ne donnent à l'optimiseur que des scores numériques. D'autres génèrent un résumé par LLM de ce qui s'est passé. D'autres encore limitent le feedback à des templates courts. Dans tous les cas, l'optimiseur travaille avec entre 100 et 30 000 tokens d'information par itération. Le problème : un harness agit sur des horizons longs. Un seul choix de design. Par exemple, ce qu'on décide de stocker en mémoire peut affecter le comportement du système des dizaines ou des centaines d'étapes plus tard. Quand tu comprimes le feedback en un score ou un résumé, tu perds exactement l'information dont tu as besoin pour comprendre pourquoi le système a échoué. C'est le cœur de la contribution de Stanford : ils ont construit un système qui ne comprime pas. Meta-Harness : le système Le principe est simple à décrire. L'exécution est massive. Meta-Harness est une boucle d'optimisation. À chaque itération : Un agent codeur (dans leurs expériences : Claude Code avec Opus 4.6) a accès à un filesystem complet contenant tout l'historique des tentatives précédentes : le code source de chaque harness testé, les scores obtenus, et les traces d'exécution complètes (les prompts envoyés au modèle, les réponses, les appels d'outils, les mises à jour d'état). L'agent inspecte ce qu'il veut dans ce filesystem. Il utilise grep, cat, il navigue dans les fichiers. Il n'ingère pas tout d'un bloc, il choisit ce qu'il lit. Il propose un nouveau harness (un programme Python complet). On évalue ce harness sur un jeu de tâches. On stocke tout (code, scores, traces) dans le filesystem. Et on recommence. L'agent lit en médiane 82 fichiers par itération dans le setting le plus exigeant. Il référence plus de 20 candidats précédents par étape. Et le volume d'information diagnostique disponible par évaluation peut atteindre 10 millions de tokens : trois ordres de grandeur au-dessus de ce que les méthodes précédentes utilisaient. C'est la différence fondamentale. Pas un nouveau trick algorithmique. Pas une nouvelle architecture. Juste : donner à l'optimiseur l'accès complet aux données brutes, et le laisser décider quoi regarder. Le résultat qui change tout : la compression tue le signal C'est le résultat le plus important du papier. Et celui qui a les implications les plus larges, bien au-delà du harness engineering. L'équipe a fait une ablation propre en comparant trois configurations d'interface pour l'optimiseur, sur la même tâche de classification de texte : Scores seuls : l'optimiseur ne voit que les scores numériques de chaque candidat. Résultat : 34,6 % de précision médiane, 41,3 % au meilleur. Scores + résumé LLM : on génère un résumé par LLM de chaque exécution et on le donne à l'optimiseur en plus des scores. Résultat : 34,9 % médiane, 38,7 % au meilleur. Les résumés font légèrement pire que les scores seuls sur le meilleur candidat. Traces brutes complètes (Meta-Harness) : l'optimiseur a accès au code source, aux traces d'exécution, aux logs complets. Résultat : 50,0 % médiane, 56,7 % au meilleur. L'écart entre l'interface complète et l'interface compressée est de 15 points de médiane. Et le candidat médian de Meta-Harness bat le meilleur candidat trouvé sous n'importe quelle condition compressée. Pourquoi les résumés ne marchent pas ? Parce qu'un choix de design dans un harness (qu'est-ce qu'on stocke en mémoire, quand est-ce qu'on le récupère, comment on formate le prompt) peut se propager à travers des centaines d'étapes en aval. Pour comprendre pourquoi un harness a échoué sur une tâche donnée, il faut pouvoir tracer la chaîne causale complète : quel prompt a été envoyé, quelle réponse est revenue, quel état a été mis à jour, comment ça a affecté les étapes suivantes. Un résumé, aussi bon soit-il, détruit cette chaîne. Un score encore plus. C'est une leçon qui s'applique directement à quiconque construit des systèmes d'agents, du RAG complexe, ou de la mémoire persistante : si tes boucles d'optimisation travaillent sur des résumés plutôt que sur des traces brutes, tu perds le signal qui compte.
Français

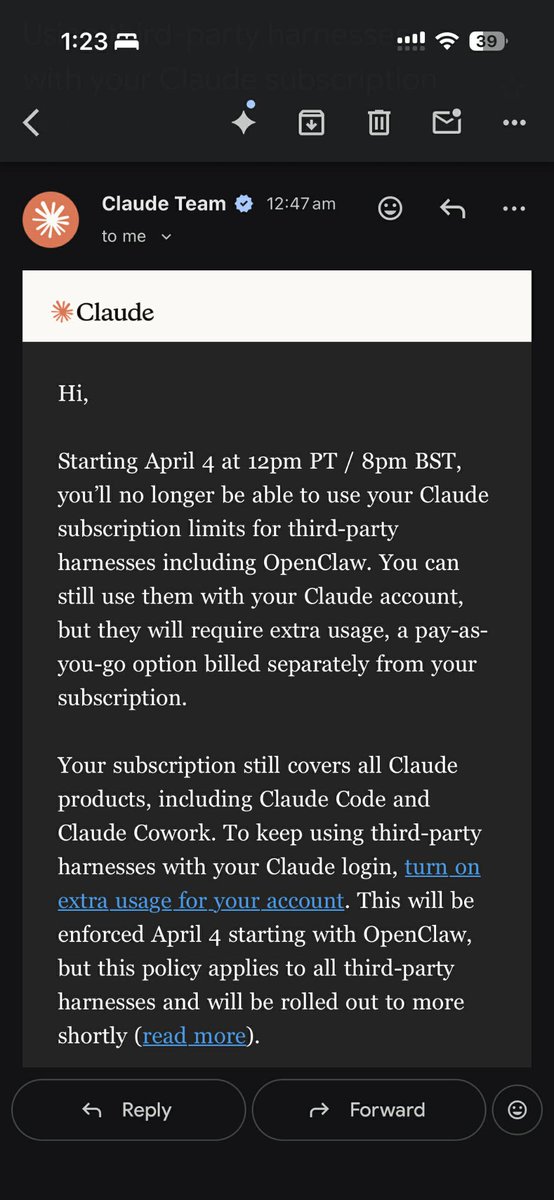
Reçu à l’instant. J’ai bien fait de lever le pied sur Anthropic ces derniers temps.
Il est temps de changer de crèmerie pour le code via OAuth, donc via l’abonnement.
Les choses vont très vite : hier encore, ça passait pour du bruit, aujourd’hui c’est réel.
Dès maintenant, il y a un risque de ban si vous continuez Claude via OAuth au lieu de l’API pour OpenClaw, Hermes, etc.
Je me suis déjà assez fait siphonner mes tokens cette semaine, maintenant on m’interdit de parler avec Jarvis et Alfred qui m’accompagnent depuis 2 mois.
Bonjour @OpenAI , on va faire fumer Spark dès demain avec gpt5.4.
On ne va pas abandonner Anthropic, surtout avec tout l’écosystème qu’ils construisent avec cœur. Mais le message est passé, et on ne l’oubliera pas 🙂
Français