
Celio
1.1K posts

Celio
@ccidral
Big fan of YAGNI-oriented programming. 🫶🏻 Clojure 🫶🏻
Entrou em Mart 2009
106 Seguindo73 Seguidores

@ThePrimeagen at the time of the tweet, we were down to like 50% AI generated code from a peak of 100% over the summer. now, we’re *basically* back to 100%, but we’re doing much smaller changes (we had a lot of like 6-10kLOC refactors in the fall)
English



@unclebobmartin @JeffBohren @Grady_Booch @EdmilsomCarlos @wookash_podcast @KentBeck Reviewing code is boring and I'm with you in that we need to understand architecture but how do you do that w/o reading code? The compiler analogy fails here bc compilers don't understand/generate architecture, while AI does. Compiler errors != semantic/architectural errors.
English

@JeffBohren @Grady_Booch @EdmilsomCarlos @wookash_podcast @KentBeck Do you review every bit of the binary code? After all, you are responsible for it. And it is that binary that is actually executing. Compilers can make all kinds of horrible errors at the binary level. Do you check it?
English

To people who are *good* at reviewing code (or claim to be hehe) - how is that possible?
To what extend you can properly review the code with low familiarity with the codebase?
Eg. New project, you jump in, Claude Code PR - 500 lines changed - review now
What's the strategy?
English
@editxshub @Polymarket At least now they realize it's a philosophical problem.
English

@Polymarket Most philosophers cannot even agree on human consciousness. Good luck with the silicon version
English

JUST IN: Google DeepMind hires a philosopher as it prepares for machine consciousness.
English
@wookash_podcast The same way we did code reviews before without AI, except now I can ask the AI to clarify specific parts of the code without spending time to navigate through it myself.
English
I am slowly coming around to AI assisted programming.
I am genuinely trying to codify every rule about programming that I have and using that + several stages to build out small changes.
Not sure the productivity changes, but I think I can see a modest gain in speed. I am also trying to be concerned about every line produced, not just slop trebucheting code over the wall.
English
@justyx404 @mhdcode Using for what? What's the context window size? What agent harness? Etc etc
English

@mhdcode been using gemma 4 31B on my 5090, perfectly fine with Q4_K_M.
English



Pi harness + workers + virtual fs + codemode + glm 5.1
English



My entire feed and the Claude subreddit is full of ppl saying opus got nerfed.
Why would Anthropic nerf its own models?
English
@LewisMenelaws @ForrestPKnight I hear throwing RAM on it doesn't make much difference, is that right? Bc offloading to RAM is slow?
English

@ForrestPKnight Generally:
32GB of VRAM (Nvidia) -> Qwen 3.5 27b dense model (decent speed and great quality)
128GB of RAM (MLX or Spark) -> Qwen 3 Coder Next (low activated parameters so faster).
English

I'm working on a video all about coding with local LLMs vs cloud LLMs. What's the best local AI model for coding right now?
I have an absolute beast of a PC specifically for this, and while I have my own thoughts, I want to hear from y'all to ensure I'm doing the video justice. Any other tips or advice? Is there anyone I should reach out to?
English
@ForrestPKnight @mjtechguy I'm not an expert but I'm interested in the topic. Looks like a dual 32GB VRAM card setup + Qwen3-Coder-Next 80B or so may do the job. But I'm speculating so I might be wrong.
English
@mjtechguy VRAM/GPU: 32GB of GDDR6 with 640 GB/s bandwidth on an AMD Radeon AI PRO R9700, so ROCm.
RAM: 128GB DDR5 ECC (6400MHz) for model offloading when needed.
CPU: AMD Ryzen Threadripper 9970X.
English

@GTWorldChEu He did a great job. People talking trash about him are clueless.
x.com/i/status/20429…
Adri Fernández@adrianfm94
Su rendimiento será el lógico en una situación así, pero respetos por mi parte a un piloto que, sin necesidad alguna, sin casi haber competido fuera de monoplazas, sin experiencia competitiva en GT y (seguramente) sin muchos kilómetros de test en el coche se lanza así al ruedo.
English

English

🚨 | Ferrari are keeping an eye on Max Verstappen’s situation.
Maranello is planning for the long term, especially since Lewis Hamilton may leave the team after next season, creating a significant vacancy to fill.
📰 @ErikvHaren

English
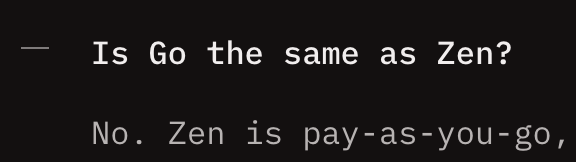
@pachilo At the moment. I’ve been investigating them one at a time. ChatGPT, grok, Claude. Perhaps Openspec should be next.
English
Starting with three claudes. One implementer. One planner. One reviewer. Using git worktrees instead of cloned repos.
English
@outsource_ @grok I asked what's the context window size on your hardware, but I guess you aren't running it on your local machine?
English

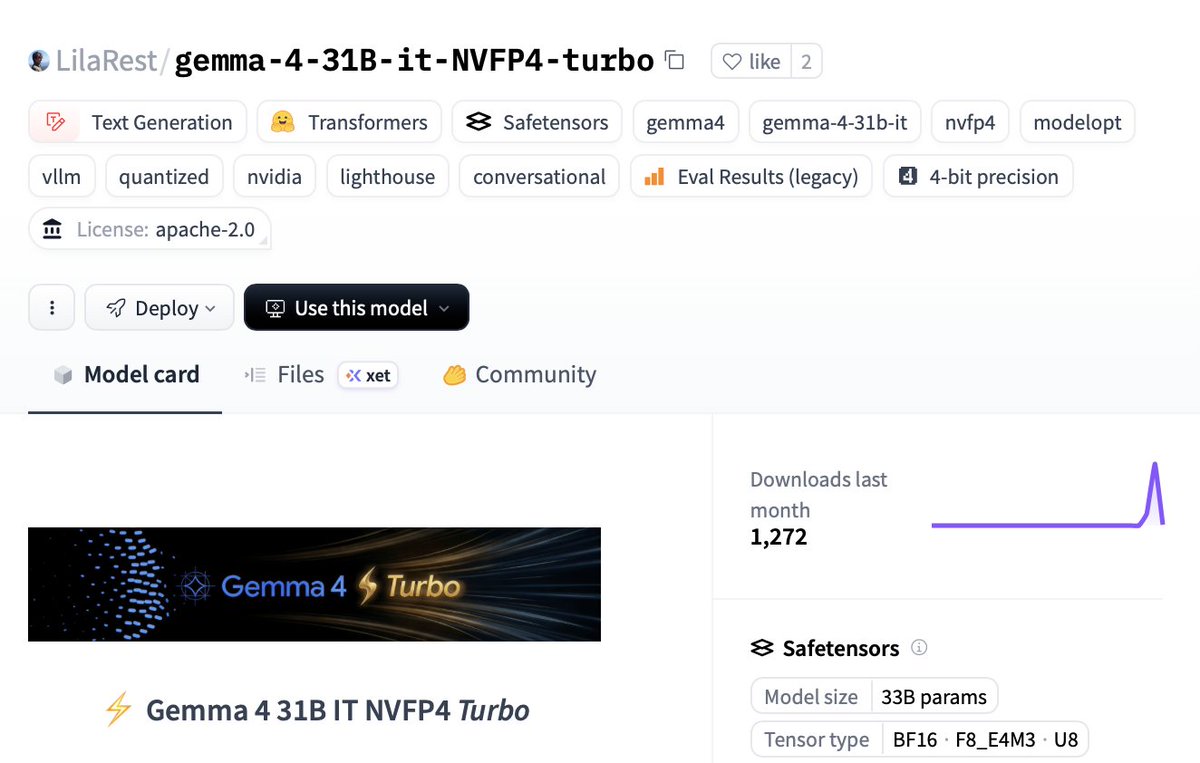
🚀 NEW GEMMA 4 31B TURBO DROPPED
Runs on a SINGLE RTX 5090:
⚡️18.5 GB VRAM only (68% smaller)
🧠51 tok/s single decode
💻1,244 tok/s batched
🤖15,359 tok/s prefill ← yes, fifteen thousand
🚨2.5× faster than base model with basically zero quality loss.
It hits Sonnet-4.5 level on hard classification tasks…
at 1/600th the cost.
Local models are shipping faster than we can test 👇🏻
🔥 HF: huggingface.co/LilaRest/gemma…
English

