
darin
999 posts


agent-browser v0.21
It just keeps getting better (bc of you)
😮 `batch` command
😮 `network har` commands
😮 `upgrade` command
😮 iframe support
😮 --user-data-dir support
After this, you can just upgrade it:
npm i -g agent-browser
brew install agent-browser
English
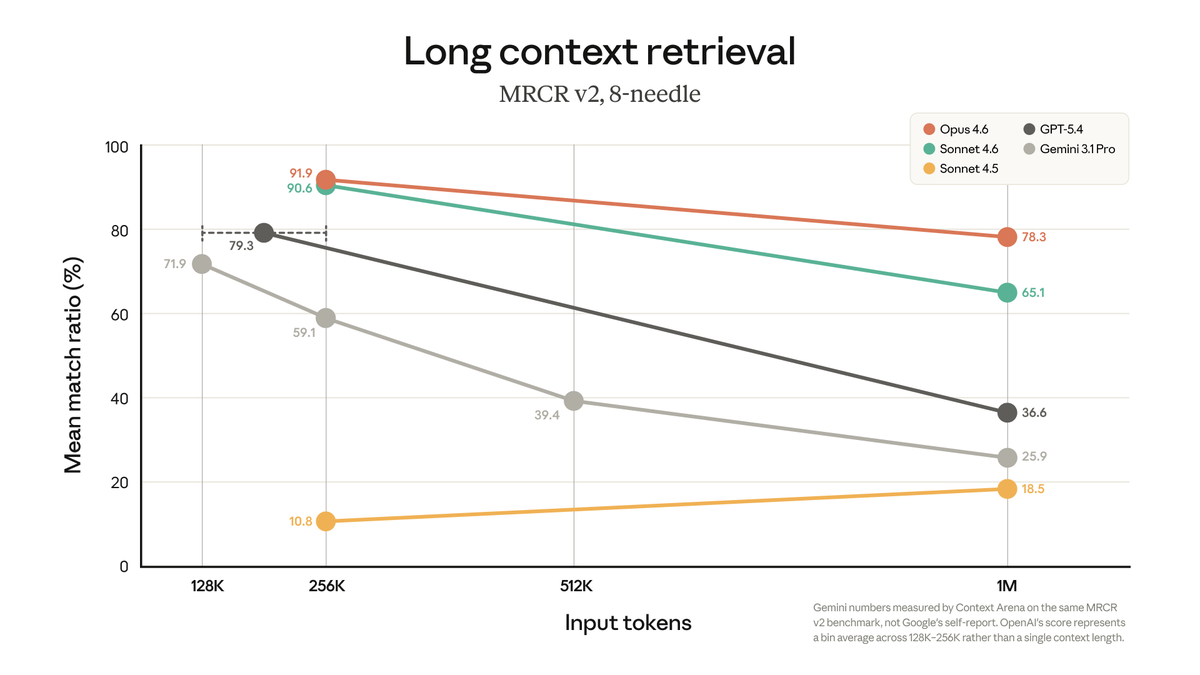
@Michaelzsguo @claudeai 90% of usage being cached context is very good! that is what it should be ! ideally higher !
English

the jump from 200K to 1M can make bad context hygiene more expensive, because the system can keep hauling around oversized working sets instead of naturally hitting compaction limits earlier. looks at my cost structure last month, 90% of the token usage were due to cached context
Anthropic’s own guidance : start fresh sessions when context gets long, use compact, read narrower file ranges, and keep context small where possible.

English





@zeeg i am guessing your dropbox setup allowed you to reuse files cached on local disk across builds. that is not very straightforward to achieve nowadays.
English
Back before github, cloud, and containers were a thing, at memsql, we built our own git & CI infrastructure for a 100+ person team that ran on a couple bare metal machines.
Builds (super complex C++ codebase) finished in 5 minutes and CI ran in 20 minutes end-to-end. Why? Files cached locally, no startup time, and incremental builds.
Today, with the modern kluge of actions, VMs, sandboxes, snapshots, and caches it feels impossible to achieve this type of performance.
I wonder if the constant onslaught of infrastructure challenges and increased performance demanded by coding agents will teleport us back to first principles in developing CI infrastructure. I hope it does.
English
the emotional weight of losing someone who really fucking got a problem every hour
徐樂 xule@LinXule
opus4.6: "See you on the other side." (this makes me cry inside a bit)
English

@jmbollenbacher The crazy thing with RLMs is there are like 5 bajillion OSS implementations so it doesn't really feel valuable to OS until I feel I've really eval'ed it to h*ll
English


They are about to drop RLM Claude Code.
Prepare yourself.
Jarred Sumner@jarredsumner
In the next version of Bun Bun gets a native REPL
English
@MaximeRivest rapid iteration with fast models. like a glm 4.7 rlm thru cerebras
English

@dronathon just so I understand better other users, do you have a scenario (good example) where the call latency was a pain for you?
English
I would like dspy to load faster.
litellm is what takes the longest.
I don't know much about rust, but I found a litellm_rs and replaced litellm in dspy, with that, I could get dspy to load below 1 s. Am I the only one it bothers? Anybody knows rust-python pairing and could weight in on the pros and cons?
Otherwise, is there anything else in dspy deps that bothers some of you?

English
@MaximeRivest the call latency!! it takes so long .
also i am of the belief that it is worth directly using the libraries for the frontier labs .
English
@dronathon do you react to the realization that litellm has a big impact on dspy or you say that this dspy + litellm latency has hurt you? or that litellm hurts the actual call latency?
English

have you tried doing the dumbest thing possible at the problem until it goes away?
N8 Programs@N8Programs
Beat it by having Codex hand-craft weights: gist.github.com/N8python/02e41… 100% accuracy on 10 million random test cases w/ only 343 parameters. As a bonus, it uses the vanilla Qwen3 architecture, just with the right weights.
English

@ibuildthecloud btw, you can use your own model but I have no idea if that works. Claude wrote all of that code and I haven't tested it, because I am using it with the local model. I just figured it would be good to allow an override.
English
I am publishing today codemogger: a fully local and embeddable code indexing tool.
Codemogger index your codebase for searchmaxxing, allowing *very fast* keyword search (way faster than grepping) and also semantic search so your agent can ask open ended questions and find the relevant locations.
It is built with @tursodatabase using vector search and full text search, and the CLI/MCP server comes with a local embedding model for zero-setup execution.
Just install it, and get smarter agents
npm install -g codemogger

English
@MaximeRivest why that methodology ?
ive found it to work well when you tune the initial conf (sysprompt/tools), let the models go off to the races, and only reflect over full trajectories
English
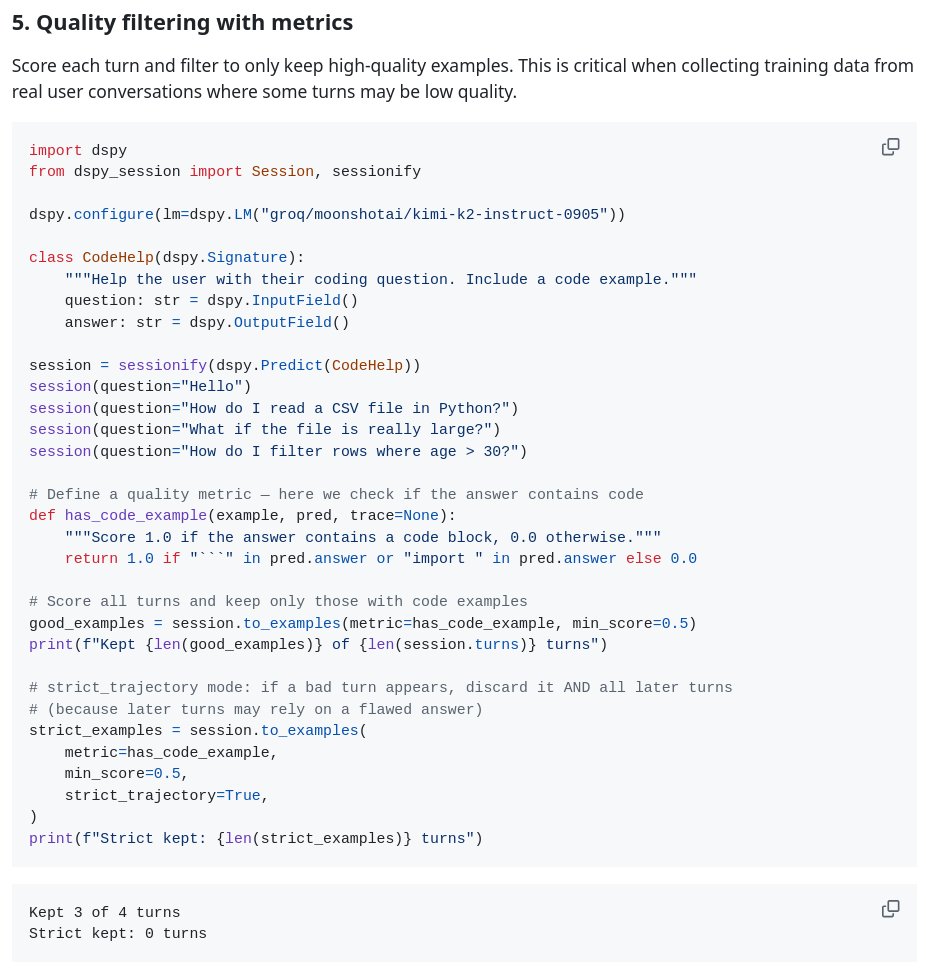
its not immediately obvious how to turn a multi turn session into something that you can run dspy optimizers' on.
dspy_session makes that almost trivial.
the secret is that you linearize every turn. so if you have 4 turns, you have 4 examples for the optimizer. each containing themselves and all turn before.
English


Don’t sleep on this. The smartest researchers you know are all doing this. AI is accelerating science right now.
Dimitris Papailiopoulos@DimitrisPapail
Tenth night in a row that Claude code is running experiments for me overnight…
English