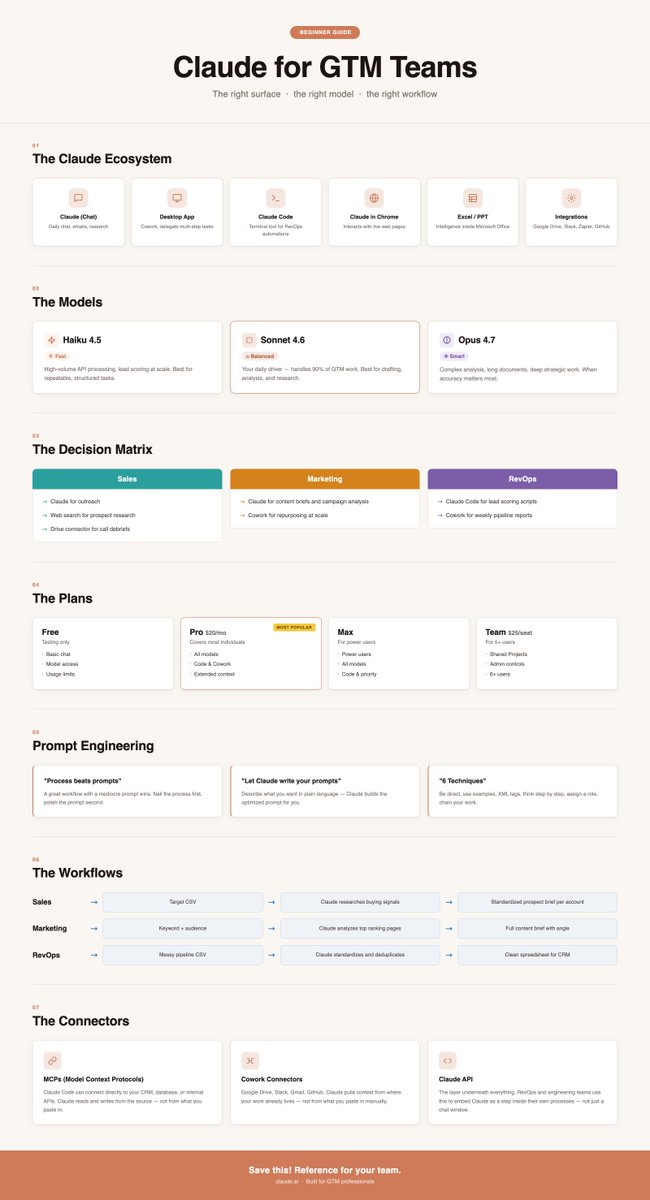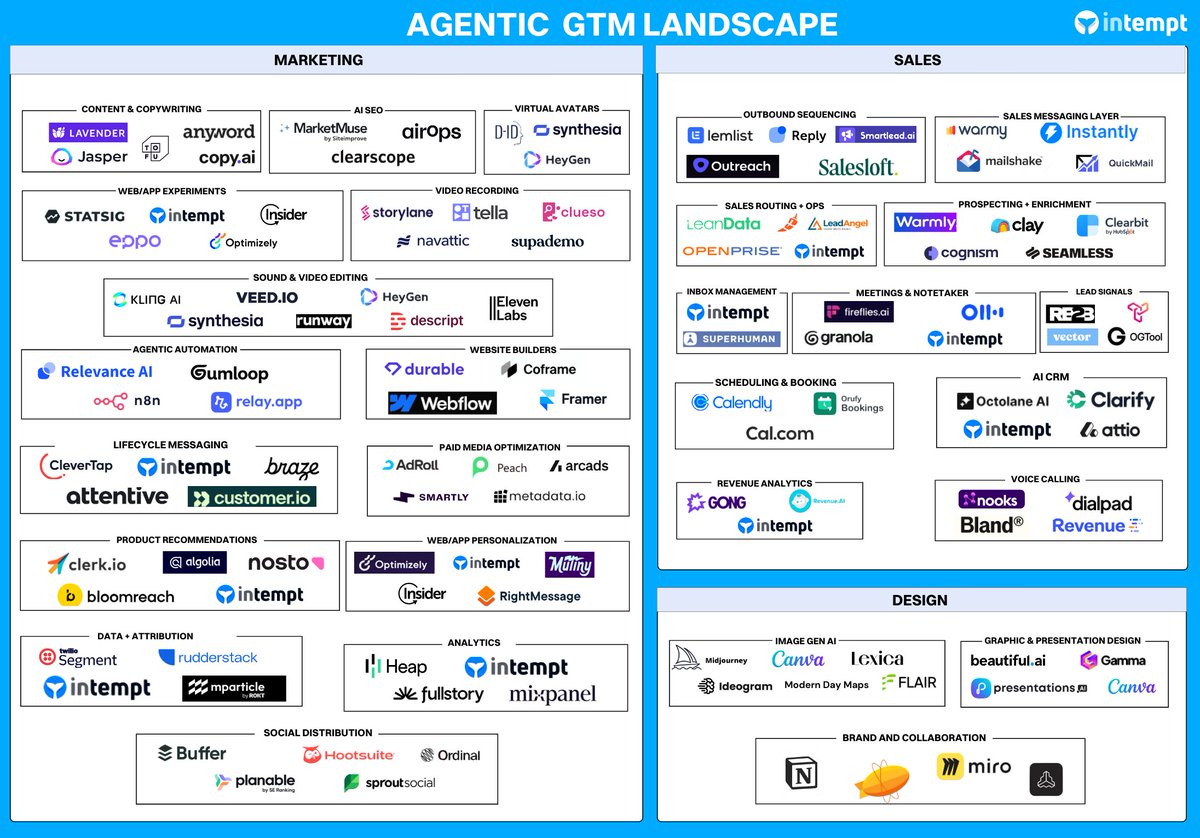

The internet can't decide if Opus 4.7 is an upgrade or a regression.
I think both sides are right. Just about different things.
For creative writing and narrative work, it's more mechanical than 4.6. Writers on r/ClaudeAI noticed immediately. The backlash was real.
For GTM teams running structured workflows, it's kind of a different release entirely.
Here's what actually changed:
1. It does exactly what you ask. Instruction following took a big step forward. Not what it assumed you meant. Not a softened version of your brief. Exactly what you wrote. For outreach copy and account research prompts, that matters a lot.
2. Agentic workflows finally hold up. Multi-step reasoning improved 14%. Tool errors dropped by a third. Multi-session memory is significantly better than 4.6.
This is the first release where the overnight agent work shifts from experiment to something we can trust.
3. Structured GTM tasks outperform creative ones. Across head-to-head tests (account research, GTM planning, outreach qualification, exec summaries), 4.7 beat 4.6 in 4 out of 5 structured deliverables.
What this means practically for your team:
→ Lead discovery, research, and outreach qualification can now run as a coordinated workflow. Not one prompt at a time.
→ You stop babysitting outputs. The model respects your context instead of filling gaps.
→ Overnight agent runs are no longer an experiment. They're a real option.
That's kind of what my team and I are obsessed with at @Intempt. Not which model you use. Whether the data and context going into it are actually clean. Unified customer data, account signals, and clean orchestration logic.
Opus 4.7 rewards precision. You can't be precise with scattered data.
The teams I keep seeing move fastest on this aren't prompting better. They built workflows on a unified context.

English