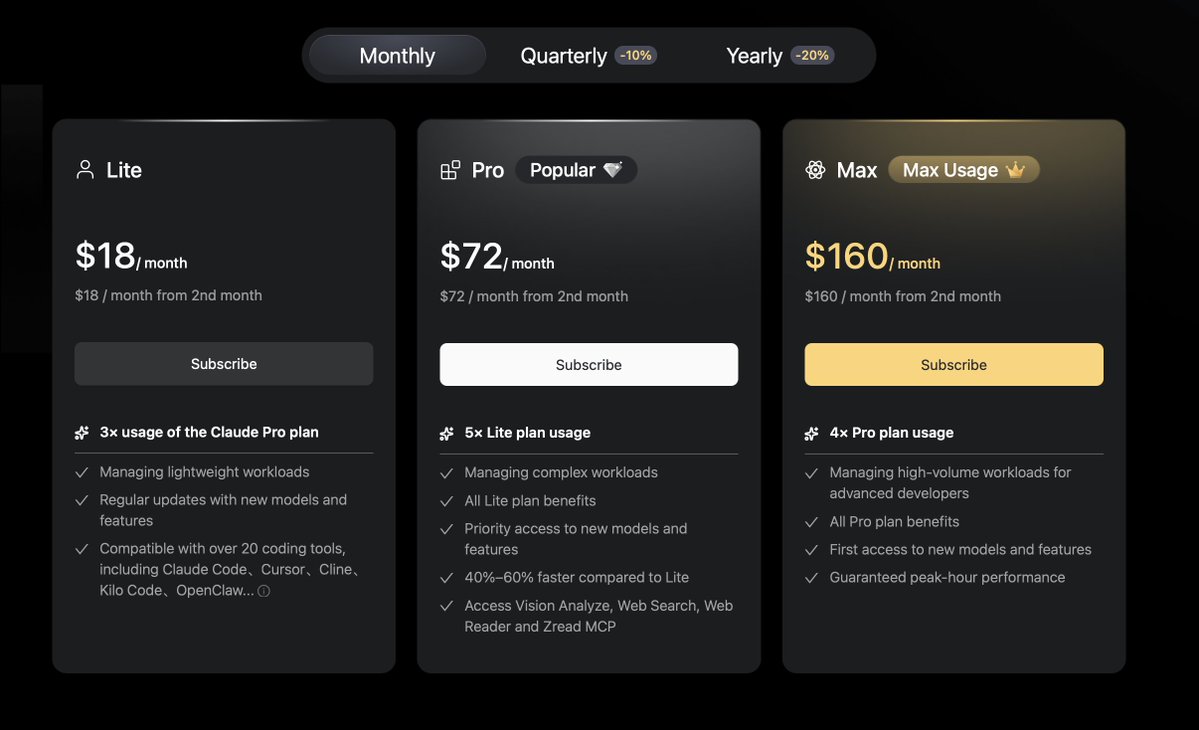
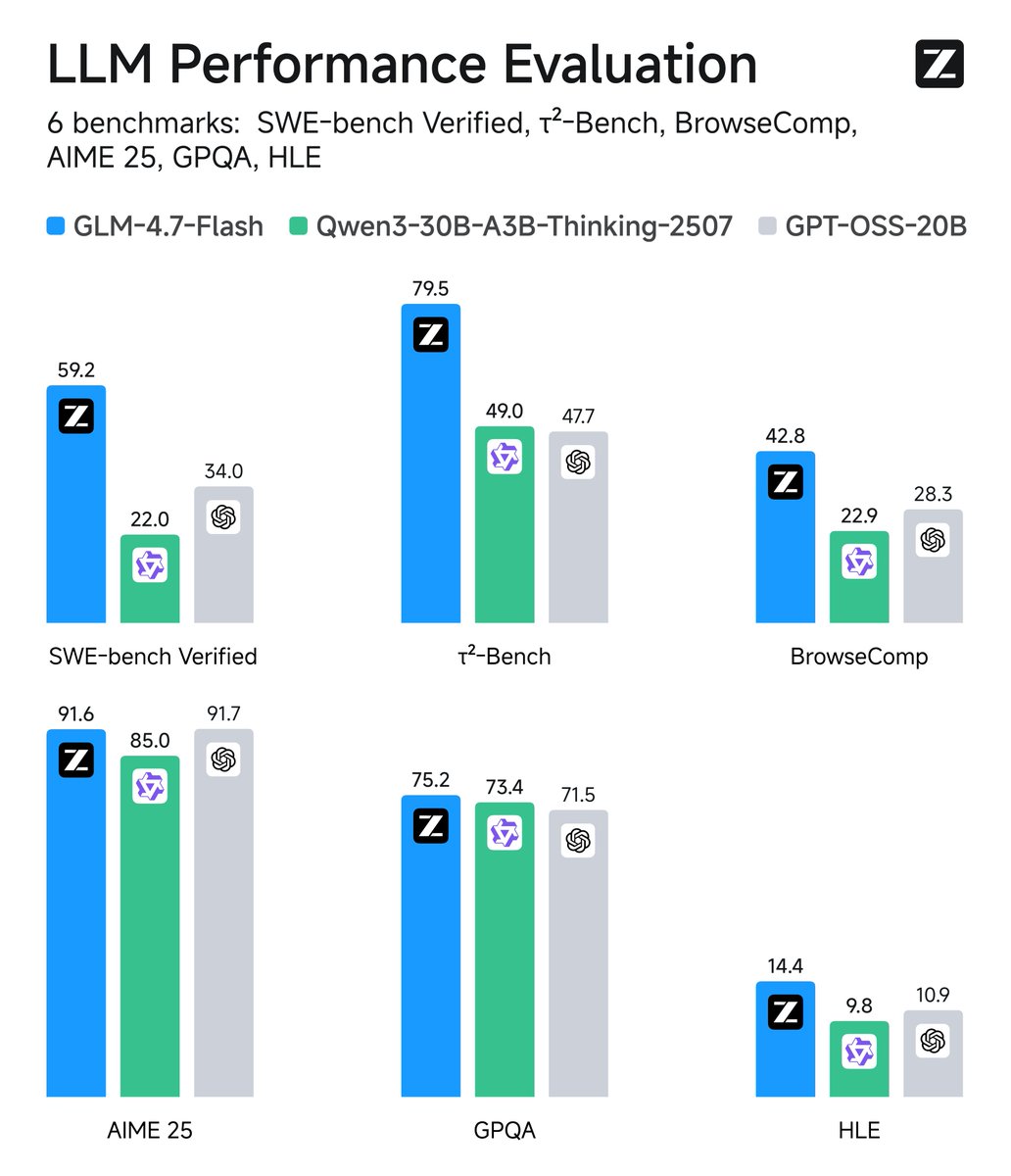
Tweet fixado

Sometimes it takes years for an idea to work out.
I own my product's domain since 2013! Chased and failed multiple times. It was beyond what a solo founder could do.
Then came LLMs, they got better at code. I restarted my product. Fresh perspective and a decade of attempts.
English