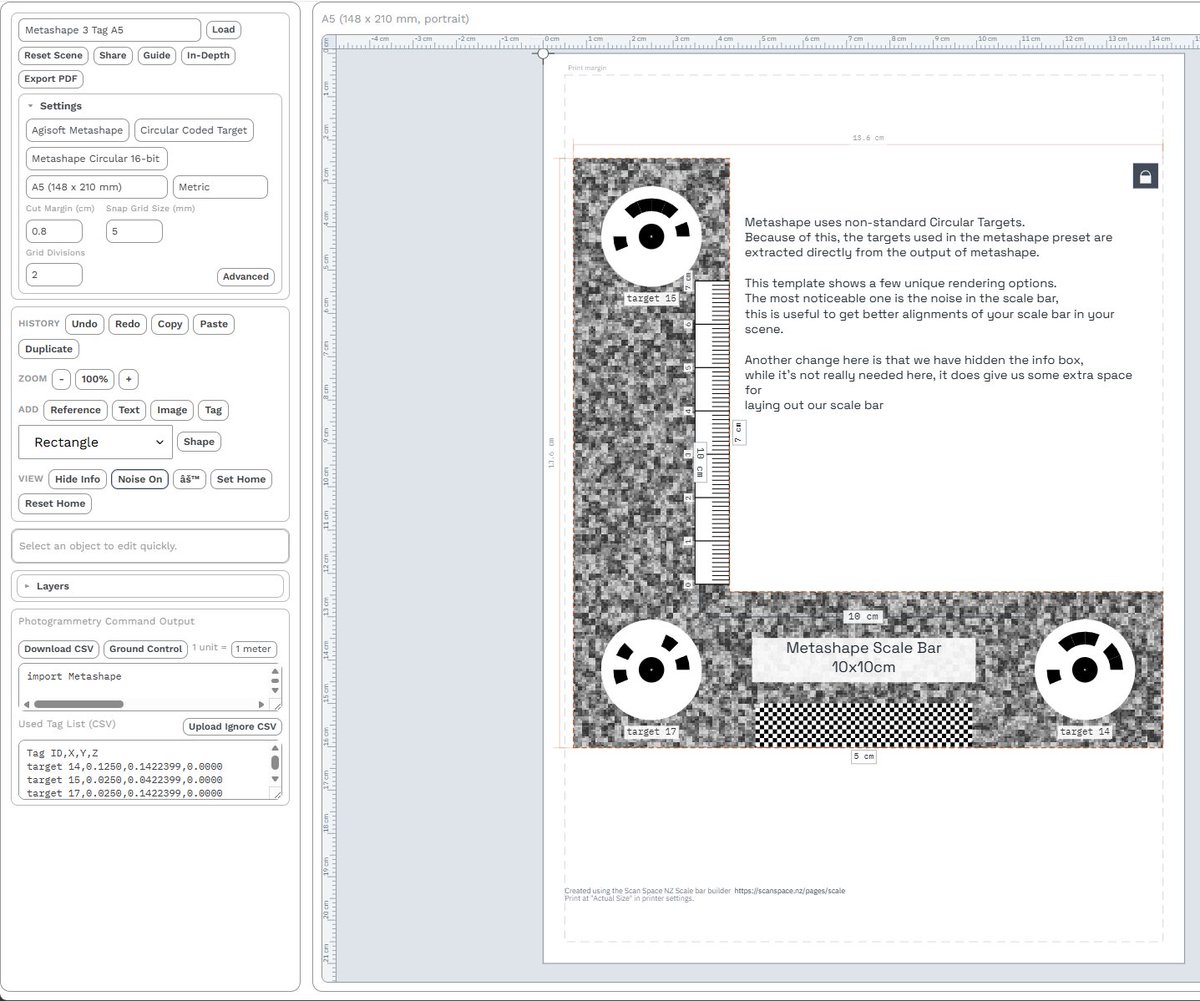
It only took 4 years to get this out, but its here. A video on how to design, build and use Scale bars in your photogrammetry!
Please share it around!
youtube.com/watch?v=mMyV_F…
From Blobs to Spokes: High-Fidelity Surface Reconstruction via Oriented Gaussians
TL;DR: Gaussian Wrapping interprets 3D Gaussians as stochastic, oriented surface elements and derives closed-form vacancy and normal fields, enabling fast, watertight, and compact mesh extraction of full 3D scenes.
Contributions:
– We introduce Oriented-Gaussians and their associated training strategy in the multi-view setting.
– We derive a theoretical connection between 3DGS and implicit surface reconstruction by formulating Gaussians as oriented surface elements, inspired by Objects as Volumes [39]. Importantly, this leads to closed-form expressions for both normal and occupancy fields at arbitrary locations without any additional learnable parameters.
– We propose Primal Adaptive Meshing, a mesh extraction procedure that leverages the derived Gaussian fields to produce high-quality, water-tight meshes at controllable resolution, enabling recovery of extremely thin structures such as bicycle spokes (Fig. 1).
Building a feature to visually indicate which cams perform worst during training.
Btw, if some cams are misaligned, you can simply select them and disable for training!
For an upcoming project at @active_theory I've been experimenting with a file format i'm calling ActiveFrame.
Like a video format, leveraging H.264 compression, allows random-access to any frame and it's fully hardware accelerated. No runtime depedencies, works eveywhere.
Here is a high resolution Macroscan of a Honeybee - I managed to get sub-pixel registration accuracy with this one so you can easily discern the feather-like structure of the individual hairs.
View on SuperSPlat:
8 million splat version - superspl.at/scene/85dd3c91
I've completely rewritten the script for extracting sharp frames from videos using Python, and I've also implemented a GUI. I'm releasing the code.
github.com/Kotohibi/Extra…
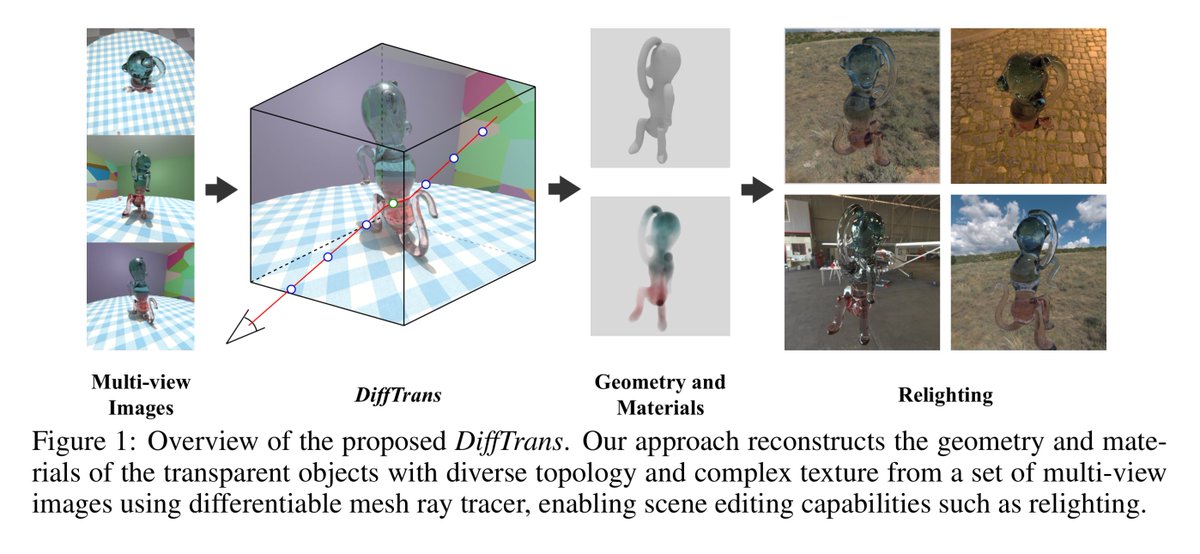
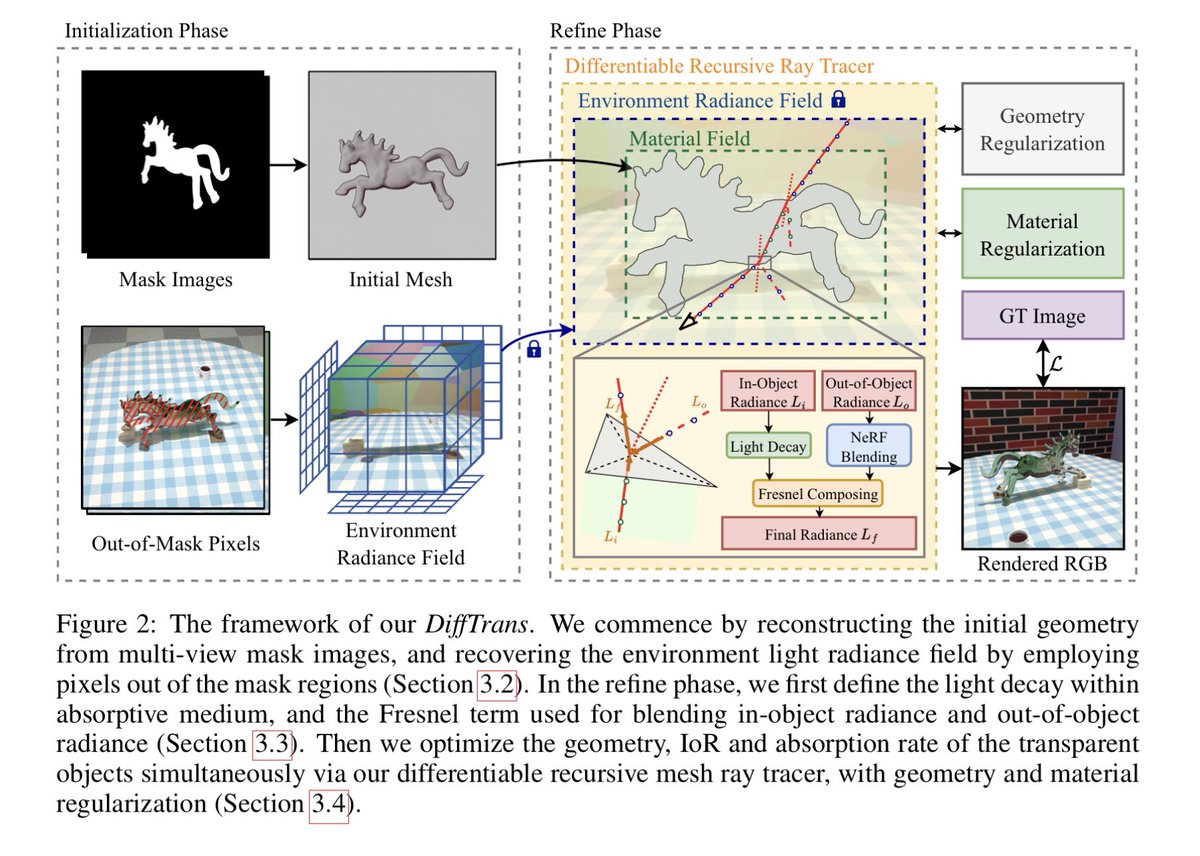
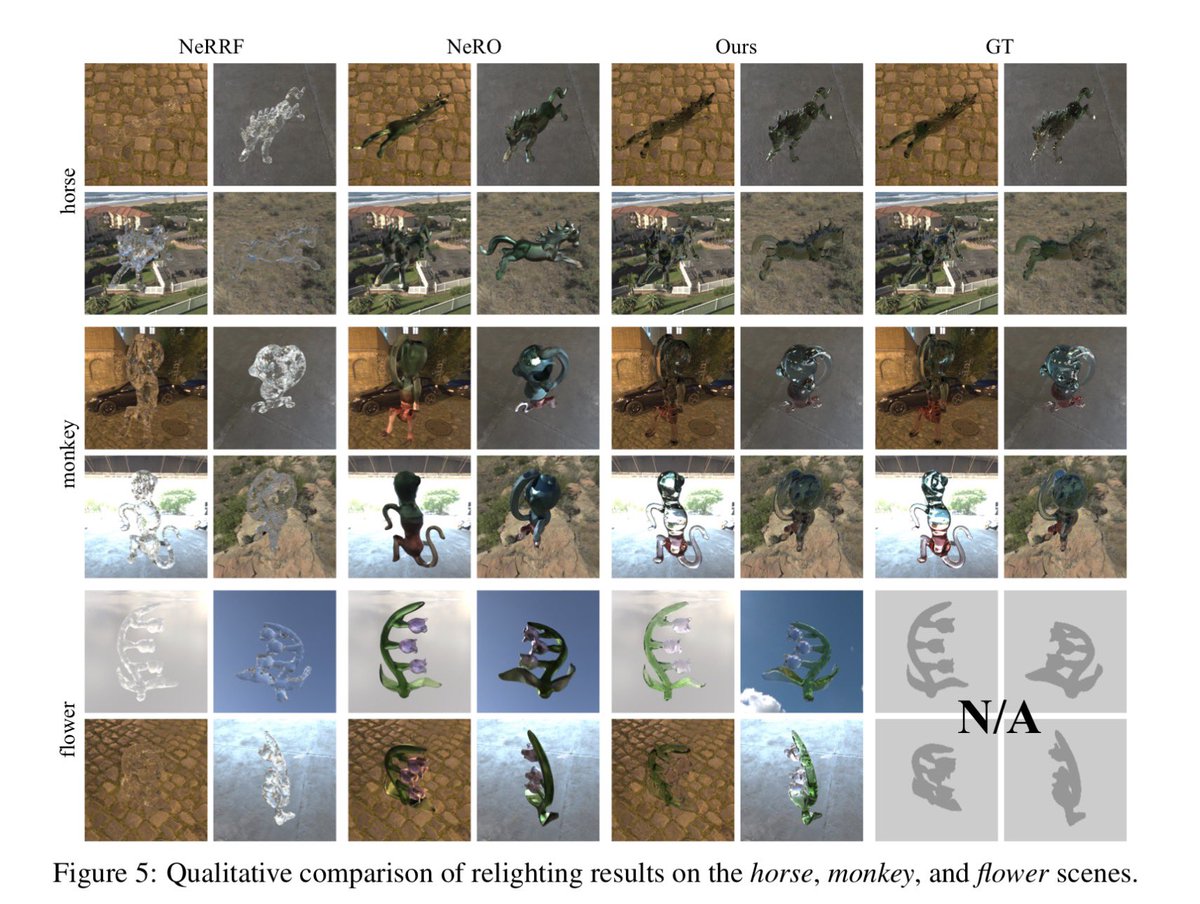
DiffTrans: Differentiable Geometry-Materials Decomposition for Reconstructing Transparent Objects
Changpu Li, Shuang Wu, Songlin Tang, Guangming Lu, Jun Yu, Wenjie Pei
Paper: arxiv.org/abs/2603.00413
Code (soon?): github.com/lcp29/DiffTrans
Abstract:
Reconstructing transparent objects from a set of multi-view images is a challenging task due to the complicated nature and indeterminate behavior of light propagation. Typical methods are primarily tailored to specific scenarios, such as objects following a uniform topology, exhibiting ideal transparency and surface specular reflections, or with only surface materials, which substantially constrains their practical applicability in real-world settings. In this work, we propose a differentiable rendering framework for transparent objects, dubbed DiffTrans, which allows for efficient decomposition and reconstruction of the geometry and materials of transparent objects, thereby reconstructing transparent objects accurately in intricate scenes with diverse topology and complex texture. Specifically, we first utilize FlexiCubes with dilation and smoothness regularization as the iso-surface representation to reconstruct an initial geometry efficiently from the multi-view object silhouette. Meanwhile, we employ the environment light radiance field to recover the environment of the scene. Then we devise a recursive differentiable ray tracer to further optimize the geometry, index of refraction and absorption rate simultaneously in a unified and end-to-end manner, leading to high-quality reconstruction of transparent objects in intricate scenes. A prominent advantage of the designed ray tracer is that it can be implemented in CUDA, enabling a significantly reduced computational cost. Extensive experiments on multiple benchmarks demonstrate the superior reconstruction performance of our DiffTrans compared with other methods, especially in intricate scenes involving transparent objects with diverse topology and complex texture.
I've just released a Free #Photogrammetry Scale bar design tool!
scanspace.nz/pages/Scale
This tool is designed to make the creation of scale bars at home really easy, and accurate enough for most tasks (as long as you print at 100% scale!)
Let me know what you think!
🎉 Our paper is accepted to #CVPR2026!
We present a training-free, camera-free method for 3DGS segmentation that runs in seconds, with a Bayesian reformulation for deeper theoretical insight.
Check it out:
sony.github.io/B3-Seg-project/arxiv.org/abs/2602.17134
See you in Denver!
🎉 Built a glTF-GLB importer for Gaussian Splatting in Unity using the new KHR_gaussian_splatting extension from Khronos!
PLY was never the right universal format for 3DGS - it's a point cloud format retrofitted for splats.
glTF -GLB brings:
Standardized attributes
(position, rotation, scale, SH coefficients)
Seamless coexistence with meshes & terrain
Cross-platform interoperability
Extensible compression support
The future of 3D Gaussian Splat delivery is here.
Note : glTF can wrap SPZ as an extension - giving you both interoperability AND compression.
github.com/KhronosGroup/g…#GaussianSplatting#3DGS#glTF#Unity3D#Khronos#gamedev@theworldlabs
Most 3DGS segmentation tools either pre‑train per scene or lock errors into a feature field you can’t undo.
ArtisanGS instead turns a few 2D masks into editable 3D object selections via Cutie tracking + black‑box splat aggregation, then lets you iteratively correct mistakes with consistent 2D/3D selection modes.
📗 #NVIDIAResearch paper: arxiv.org/abs/2602.10173
Introducing SuperSplat Studio 🪄
Build and publish awesome Gaussian Splat experiences
ℹ️ Create hotspots and annotations
🎦 Set up camera viewpoints
🖼️ Add advanced full screen effects
[1 / 2]
Radiance field reconstruction (Gaussian splatting) quality is getting a big step up. @NVIDIAAI just released Physically-Plausible Image Signal Processing (PPISP) for Radiance Field Reconstruction.
Apache 2.0 and coming to both gsplat and 3DGRUT.
Code: github.com/nv-tlabs/ppisp
Article: radiancefields.com/nvidia-announc…
Authors: Isaac Deutsch, Nicolas Möenne-Loccoz, @ZGojcic, @gavrielstate@NVIDIAAIDev
Escape your tiny screens and step into a 500" world with the XREAL 1S
✅ REAL 3D™: The world’s first on‑glasses 3D spatial technology that transforms all your 2D games, movies, and photos into an immersive 3D experience
✅ Your 500" cinematic escape: 1200p HD resolution, 52° FOV, and 120 Hz refresh for a sharp, smooth, big‑screen experience anywhere
✅ All Your Favourite Features from the One Series: Native 3DoF spatial anchoring, electrochromic dimming, and seamless USB‑C plug‑and‑play, all powered by the X1 chip
✅ Cobalt Blue Finish: Radiating bold coolness and timeless presence
Launching at just $449. Tap the link here to order your XREAL 1S today. 🚀
us.shop.xreal.com/products/xreal…#XREAL#1S#ARGlasses#LaunchDay#FutureTech
You can't 3D reconstruct glass from images...
...WRONG! Thanks for video diffusion, now just about anything is possible!
Introducing...Diffusion Knows Transparency (DKT)
Transparent and reflective objects usually break robot vision and photogrammetry pipelines because they don't follow the "solid object" rules standard cameras expect. DKT is a new AI model that repurposes the "internal physics engine" found in video generation models to solve this problem.
Researchers took a massive video diffusion model (WAN) and fine-tuned it using a custom-built synthetic dataset to turn it into a high-precision depth sensor.
To train the AI, they built the first massive synthetic video library of transparent objects, 1.32 million frames of perfectly labeled glass and metal objects in motion.
Without ever seeing a "real" labeled video of glass during training, the model (DKT) outperformed all previous specialized systems on real-world benchmarks (ClearPose, DREDS).
They created a "lightweight" 1.3B parameter version that runs fast enough (0.17s per frame) to be used on actual robot hardware.
Two reasons I find this project important:
1. It further proves that synthetic data will be essential for training the next generation vision models.
2. In real-world robotic tests, using DKT's depth maps nearly doubled the success rate of robot arms trying to pick up objects on tricky reflective or translucent surfaces. At home robots will need to interact with these types of objects on a daily basis.
Check out the project page here: daniellli.github.io/projects/DKT/
Code is LIVE!
#Computervision#Robotics#AI