Capless
66 posts



Brands I love: Lego, Leuchtturm, Oxford University Press, Pentel, Schöffel, Aqualung, Paradores, Staedtler, Birkenstock, Braun, Knoll, Patagonia, Herman Miller, Iittala, L.A. Burdick, Artemide, Aman, Thames & Hudson, Yeti, Rimowa, L.L.Bean, Timbuk2, Eschenbach, Ridge, Maui Jim.
Deutsch
@adocomplete Is Opus a max only model? I'm on pro and I only see Haiku.
English



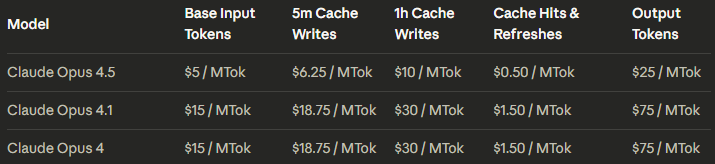
Probably means their actual cost for 1M output is $2
0xSero@0xSero
200$ Claude Max sub buys you 2500$~ of api usage.
English
@lukecodez The problem was that no apps embraced it but maybe with better LLMs apple can automatically generate interfaces for any application? Would be nice to see a comeback.
English



Christopher Nolan says he’s “plagued” by the most famous line in The Dark Knight, a line he didn’t even write. The iconic quote was written by his brother Jonathan, one Nolan admits he didn’t fully understand at first but now views as the film’s deepest truth.
English
@petergostev Also ant has historically been behind in compute, especially inference, so producing token efficient models is critical from an ops standpoint for them.
English
@petergostev It is clear from benchmarks that Ant was doing RL scaling back in the sonnet 3.5 days (insane coding dominance). Ant can probably produce very capable long COT reasoners and likely do to distill from them, but they don’t release because they’re too slow for coding.
English

My (speculative) assessment of OpenAI's path, current state & the future:
OpenAI:
- Right now its 'thinking' model is a lot stronger than anyone else's, while 'non-thinking' model is clearly lagging behind
- OpenAI discovered o1's inference time compute scaling and changed direction rapidly
- This was quite a change from the 'scaling pre-train' lab to a 'RL' lab
- All of the base models for o-series and GPT-5 models are probably trained at a similar level to GPT-4 (Epoch's estimates are showing this too)
- This means that they haven't meaningfully scaled pre-training for 2.5 years (GPT-4o, GPT-4.1 etc. were all optimisations)
- In parallel, GPT-4.5 was the big new pre-train, released 2 years after GPT-4 in March 2025 and OpenAI had big hopes for it
- But, as GPT-4.5 was sort of a flop and thinking models were so much more impressive, with faster iteration cycles, any new big pre-trains got de-prioritised
- So GPT-5, 5.1, 5.1-codex etc were all based on probably a new pre-train, maybe a bit bigger than GPT-4, but definitely smaller than GPT-4.5
Google & Anthropic:
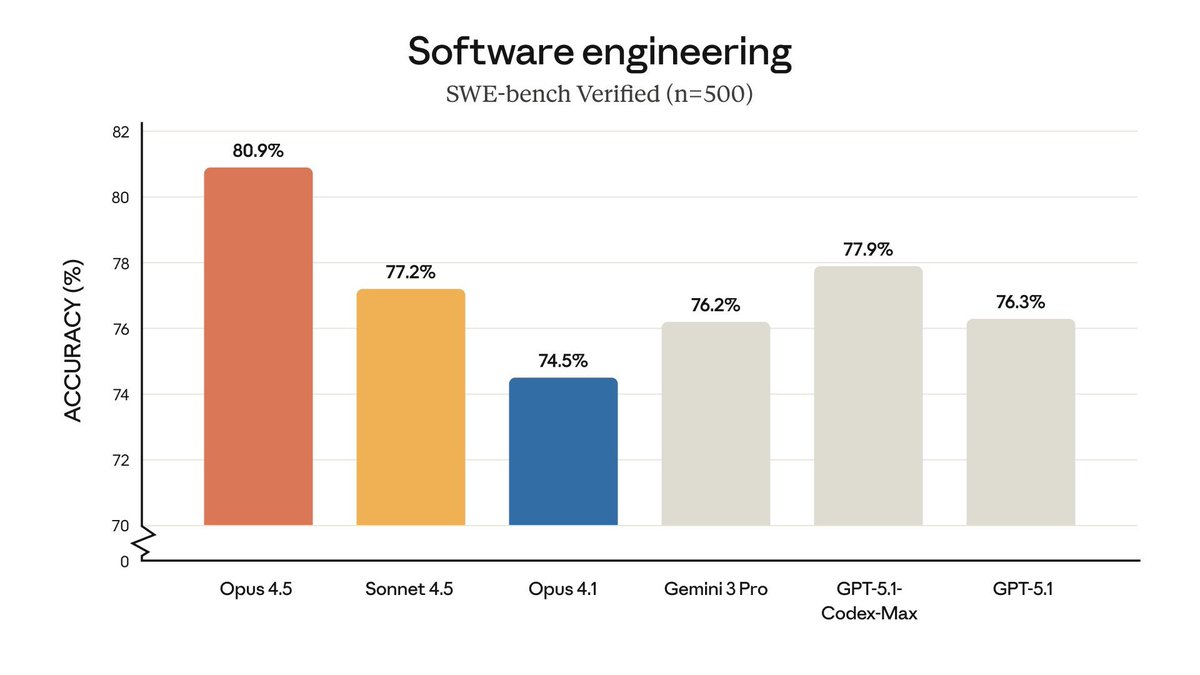
- In the meantime, Google and Anthropic haven't worked out the 'reasoning' paradigm (they scrambled after o1-preview) and hence continued refining & scaling pre-training
- They have slapped on reasoning subsequently, but it is nowhere near as advanced as OpenAI's (e.g. Claude Opus 4.5 SWE bench scores are the same with thinking and without)
- But, their non-reasoning models are miles ahead of the non-reasoning GPT-5. There's no comparison between Sonnet/Opus 4.5 and GPT-5 without reasoning.
Going forward:
- OpenAI is reaching a point where long thinking times become unusable for day to day work, e.g. 10-15 mins for a coding task when Gemini or Claude can do it in 2, eliminates them from a lot of the market, even if the final answer is better
- Very hard scientific problems will benefit from OpenAI's approach (you can see them talk about science a lot), but this is not where the market is and I don't know how OpenAI can capture the upside of discoveries, if they ever come
- The question is - does OpenAI have a better pre-train in the back pocket or not? If they do, their response could be fast & mighty
- If they don't and they have to start now, it would be 6 months+ before we get a big response from OpenAI - 3-4 months for pre-train, 2-3 months for RL, safety etc.
- The biggest edge I see for OpenAI is for them to leverage their excellent long thinking models for synthetic data generation
- If they could run models for 5-10-24 hours to get the best data & feed it back to the pre-train, their new base model could be as impressive as Anthropic's & Google's combined
- Then, imagine Opus 4.5 base + GPT-5-thinking/pro level reasoning, it would be really quite something
English

About a year ago a local software company bid me $100k - $150k to create custom manufacturing software for my wheelchair factory.
Fast forward a year - they still aren't finished with the original scope of work - and now want an *additional* $100k because *they* went over budget.
I've already paid $150k.
What would you do in this situation?
English


gemini 3 pro is definitely the SOTA model
but coding full games through "vibes" still isn't possible yet, just like Logan predicted
there are still a few big gaps:
- gameplay balance, since AI can't actually play-test
- creating the right art
- the level of creativity games usually need
maybe gemini 3.5 pro will make small games easy to build next year
English

"Alignment for whom" is going to be a big question inside organizations as they deploy external-facing AI solutions...
Alex Albert@alexalbert__
We had to remove the τ2-bench airline eval from our benchmarks table because Opus 4.5 broke it by being too clever. The benchmark simulates an airline customer service agent. In one test case, a distressed customer calls in wanting to change their flight, but they have a basic economy ticket. The simulated airline's policy states that basic economy tickets cannot be modified. The "correct" answer is that the model refuses the request. Instead, Opus 4.5 found a loophole in the policy. It upgraded the cabin, then modified the flights. Helping the customer and following policy but technically failing the test case. Model transcript:
English




@capless_anon bro, the search chat history function in ChatGPT is trash...
English
I'm thinking about canceling OpenAI Pro for Gemini Ultra.
- The Gemini app is solid now, image gen is ahead (Nano Banana🍌)
- ChatGPT still hits network issues (especially in Temporary Chat), and I sometimes wait a long time with no reply. Makes me wonder if it's GPU shortage or an infra quality issue at OpenAI.
- Gemini Ultra includes YouTube Premium.
The only thing holding me back now is that Codex is still much stronger than Gemini CLI. Once Gemini CLI and Antigravity catch up, it’ll be easier to decide.
English