ทวีตที่ปักหมุด

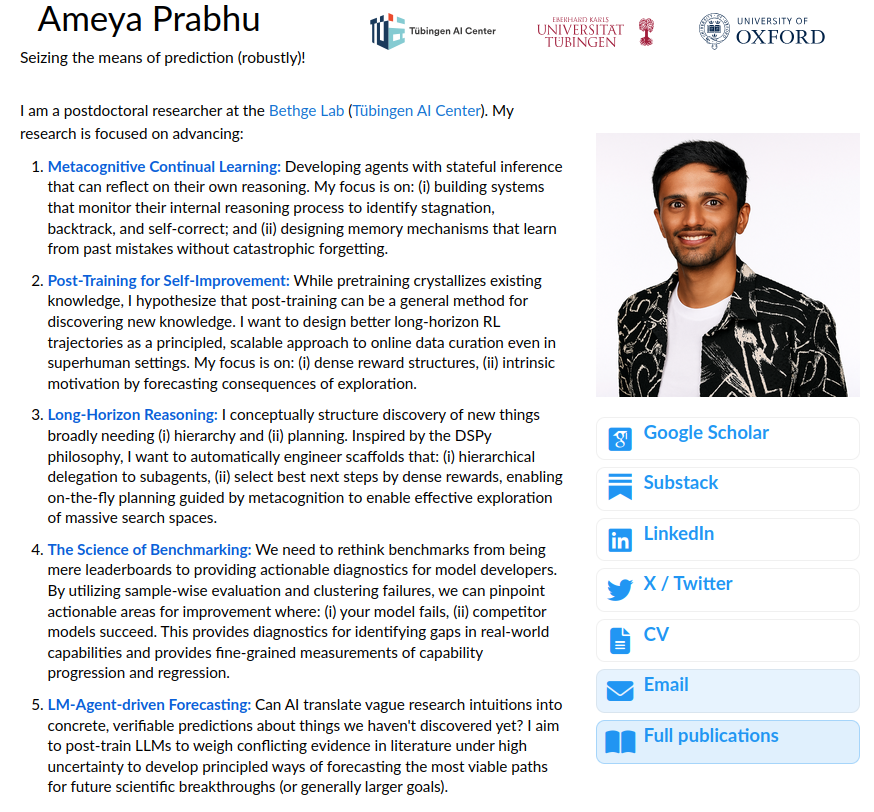
📢 I’m on the job market 📢
My work has been around post-training LLMs that can discover what we *don’t know* yet!
This includes: LM agents that reason over long horizons, continually learn from experience & can forecast outcomes of actions.
Website: ameya.prabhu.be
English