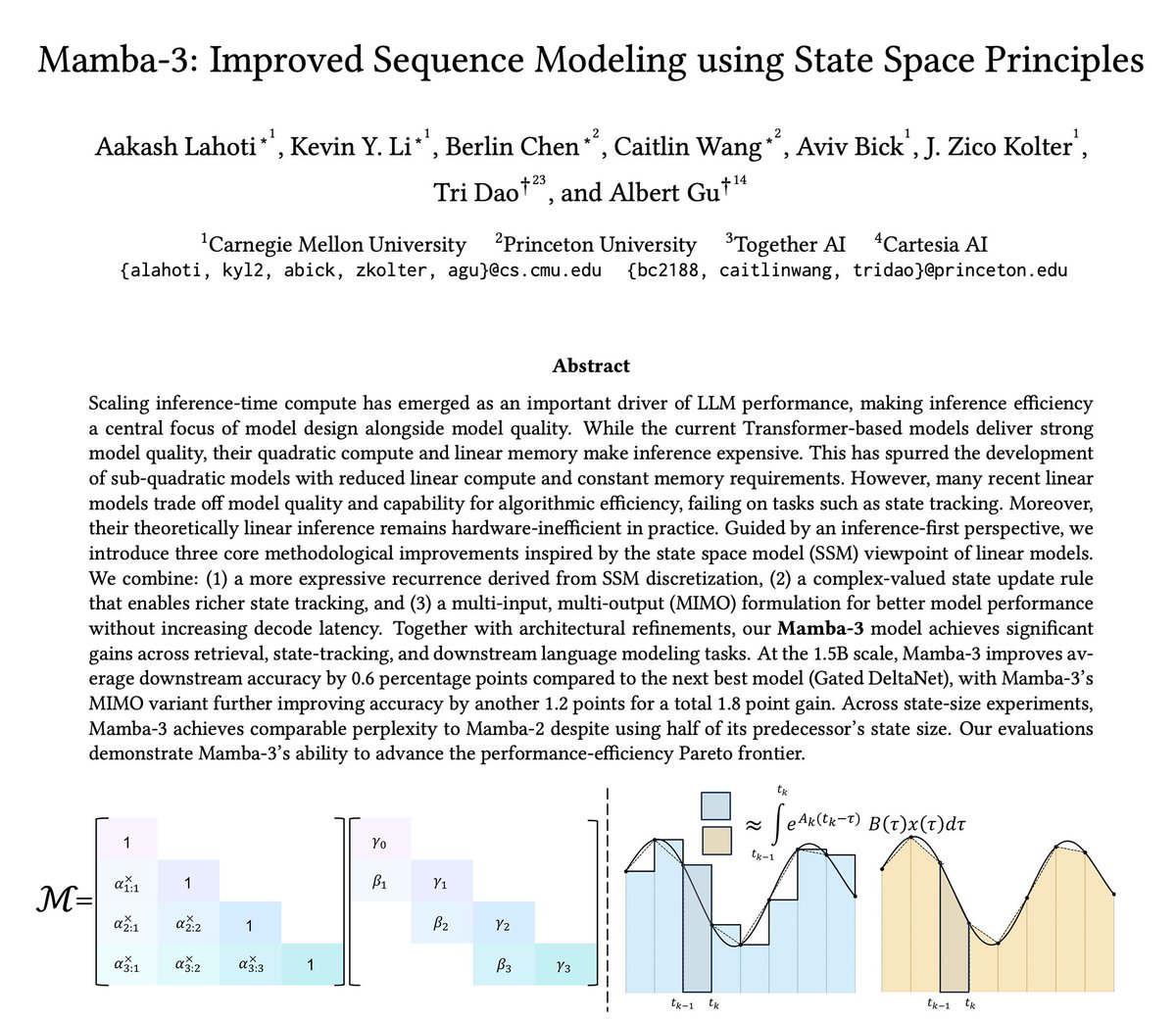
ทวีตที่ปักหมุด

“This Is Not How Mathematicians Are Trained”
数学家不是这样训练的
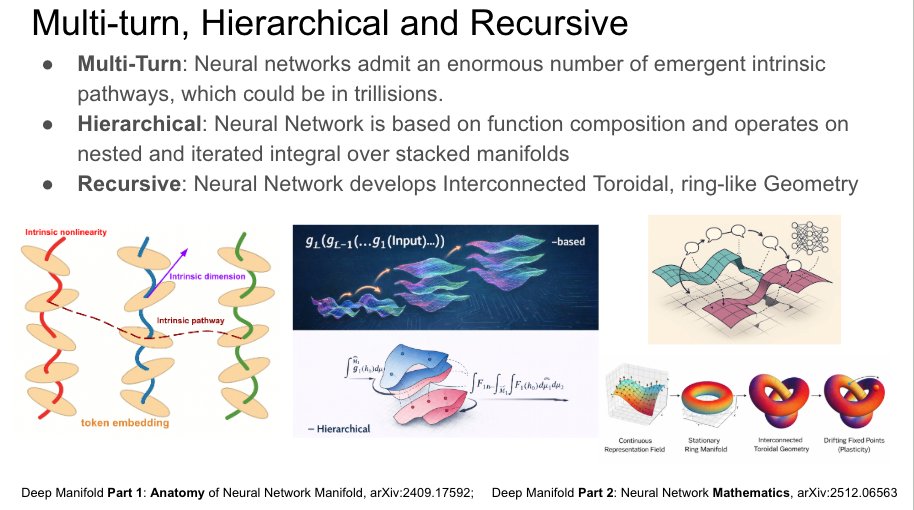
1, "Solving the forward problem (positive time) and the inverse problem (negative time) together has always been a desire of mathematicians, but they’ve never known where to begin. Neural networks, however, tackle this problem naturally" (将正时间的正问题与负时间的反问题同时求解,一直是数学家的梦想,但他们始终不知道从何入手。而神经网络却能自然地处理这个问题)
2. “Variables, coefficients, even coordinates, are changing. Everything is in flux. This is not how mathematicians are trained. It would be impossible for mathematicians to come up with such a design” (变量、系数,甚至坐标都在变化,一切都处于变动之中。数学家不是这样的训练。这样的设计,不可能出自数学家之手)
3. “Mathematicians tread carefully around composite functions with more than two layers, wary of the many pitfalls, yet neural networks solve them effortlessly, almost nonchalantly.” (数学家在处理超过两层的复合函数时格外谨慎,警惕其中诸多陷阱, 而神经网络却几乎漫不经心地轻松应对)
4. “Neural networks have stacked covers, mathematically speaking, whereas the Numerical Manifold Method typically uses only 3 to 4. In contrast, neural networks stack hundreds or even thousands of such covers. I never imagined anyone would take it that far”. (神经网络在数学上拥有堆叠的覆盖层,而数值流形通常只有三到四层覆盖。相比之下,神经网络则堆叠了上百乃至上千层。我从未想过有人会将其推进到这种程度).
That was what Gen-Hua Shi (石根华) told me after returning from a two-week vacation in early June 2024..
see rest of the story, click the link
open.substack.com/pub/deepmanifo…


English