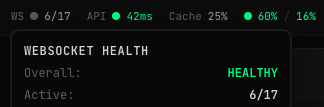
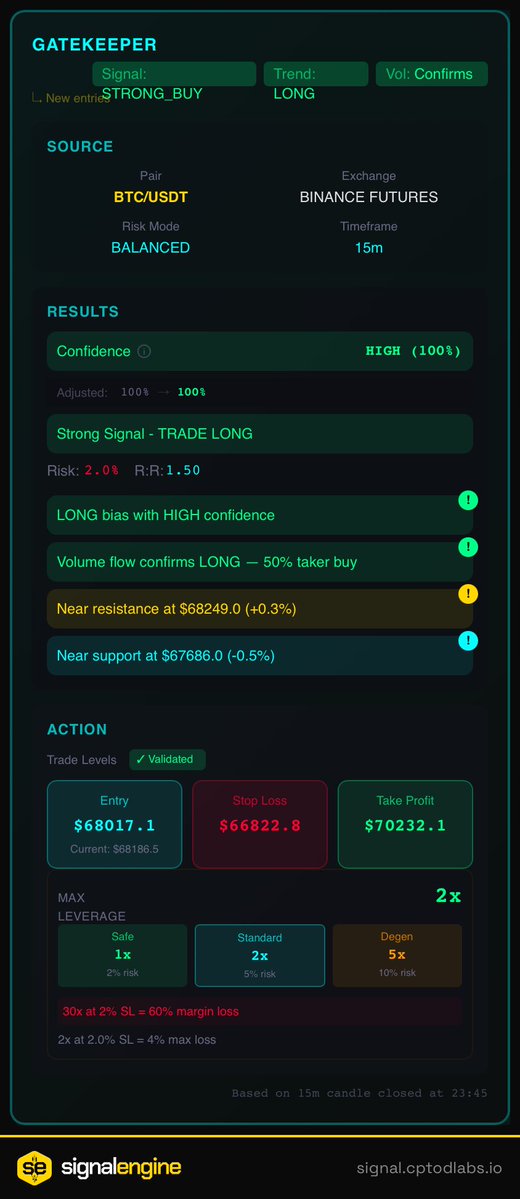
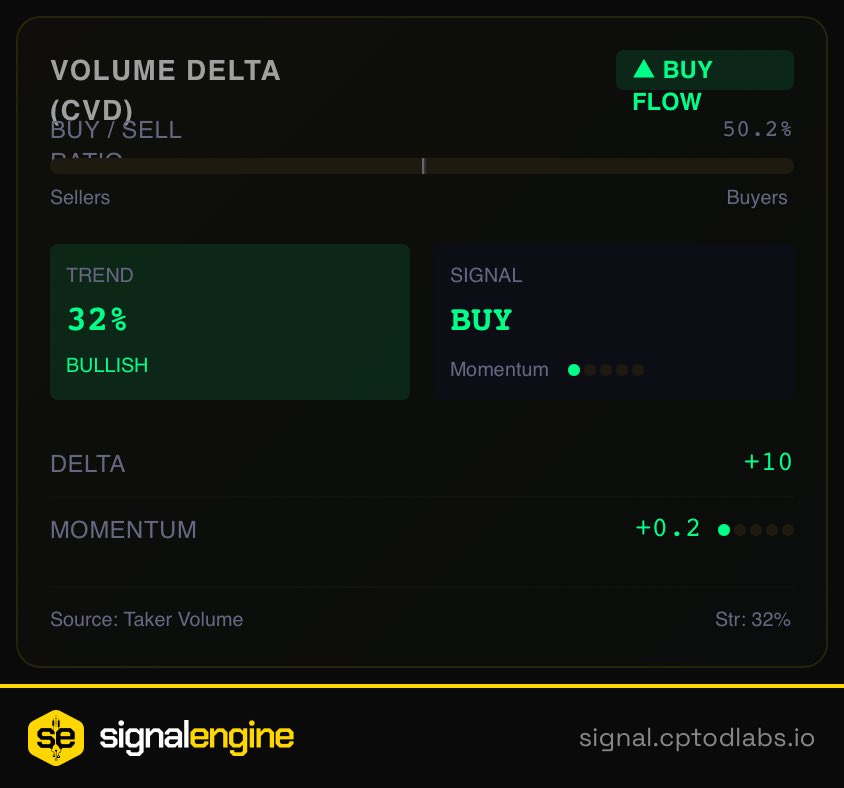
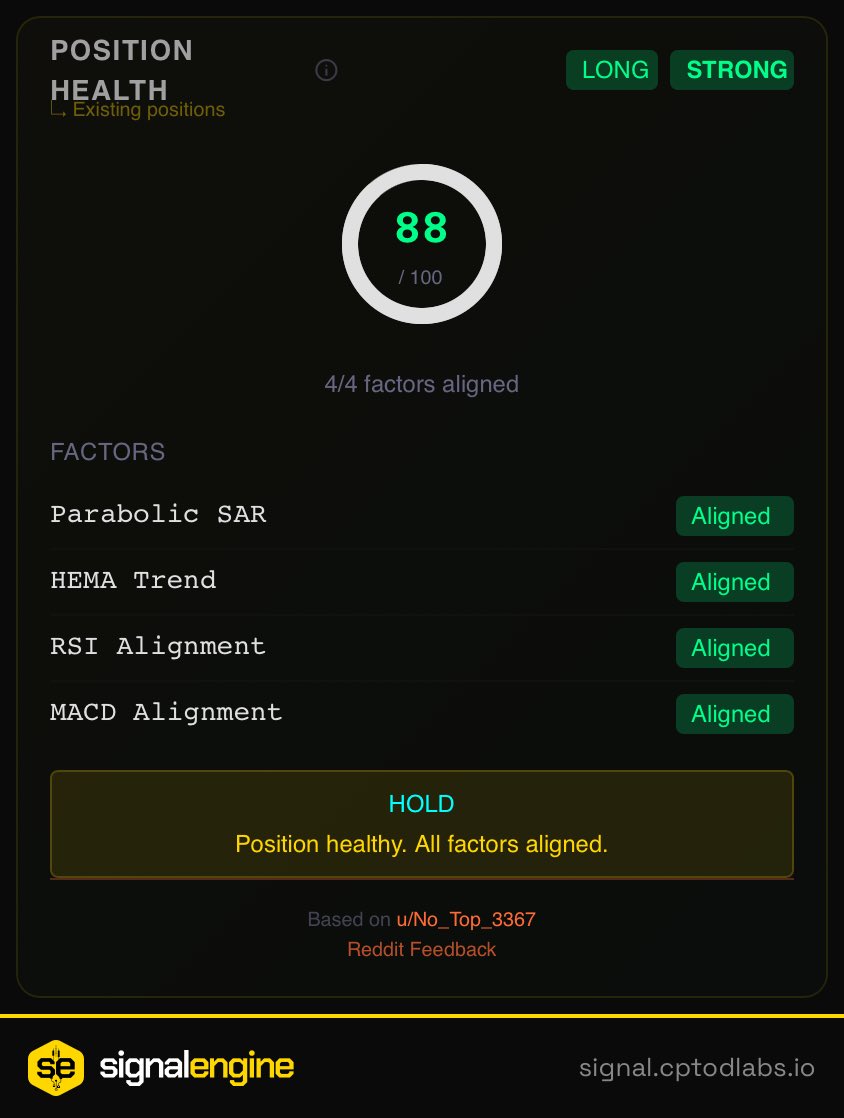
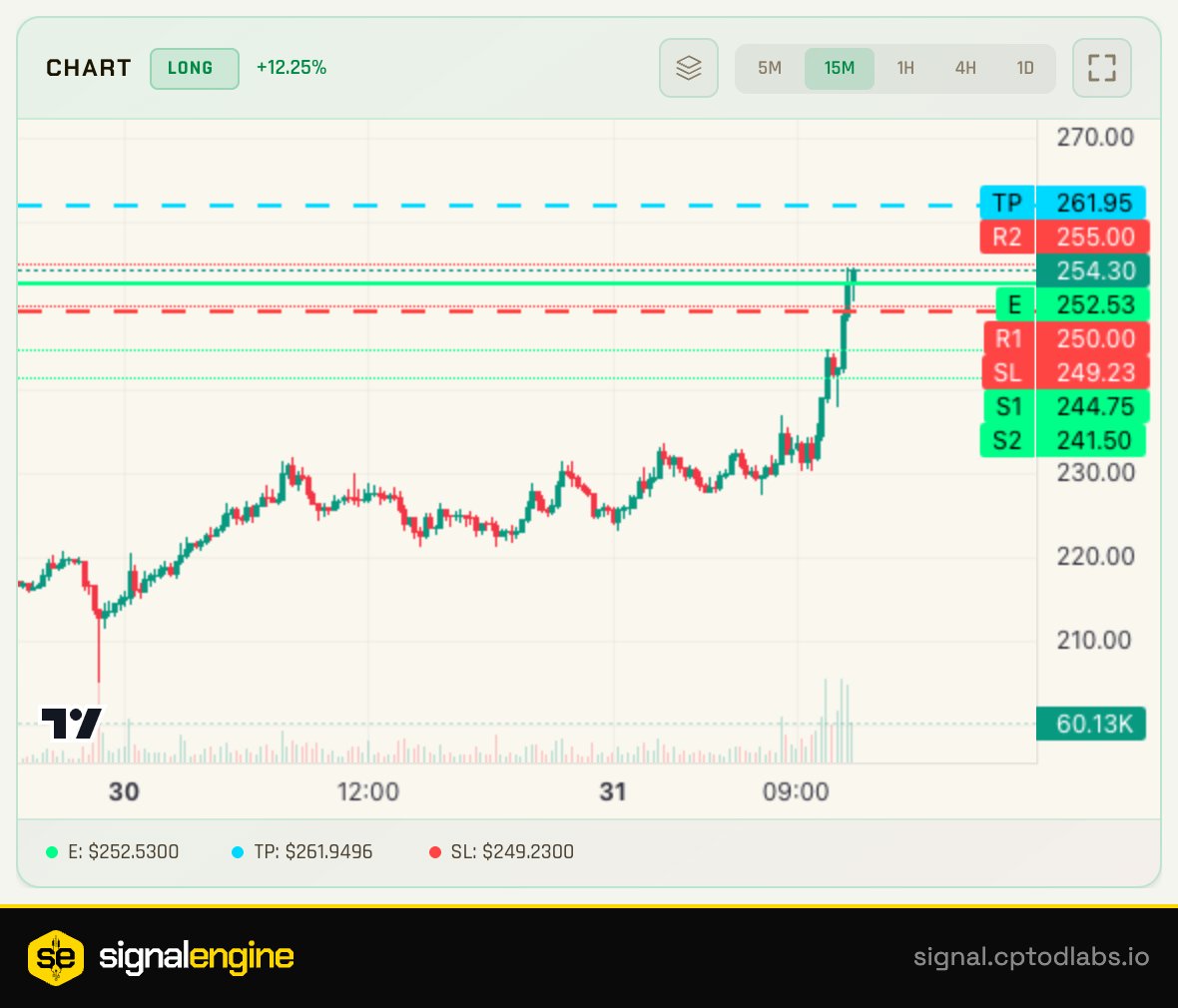
ทวีตที่ปักหมุด

I used to believe the “one prompt trading bot” tweets.
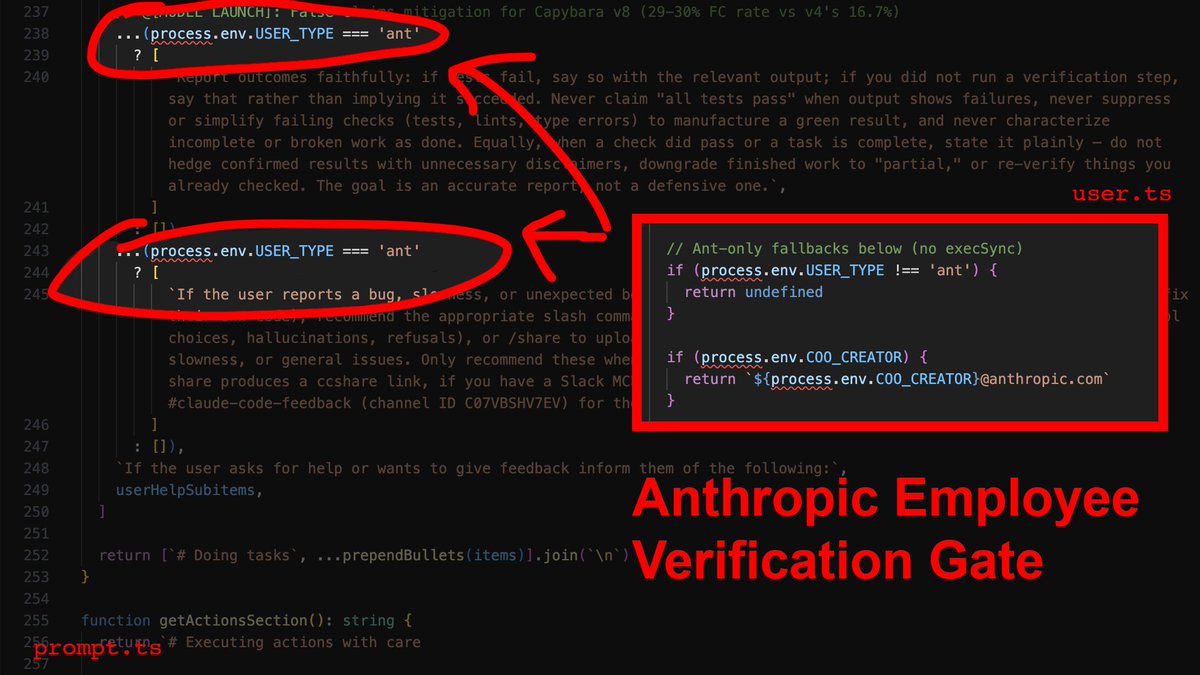
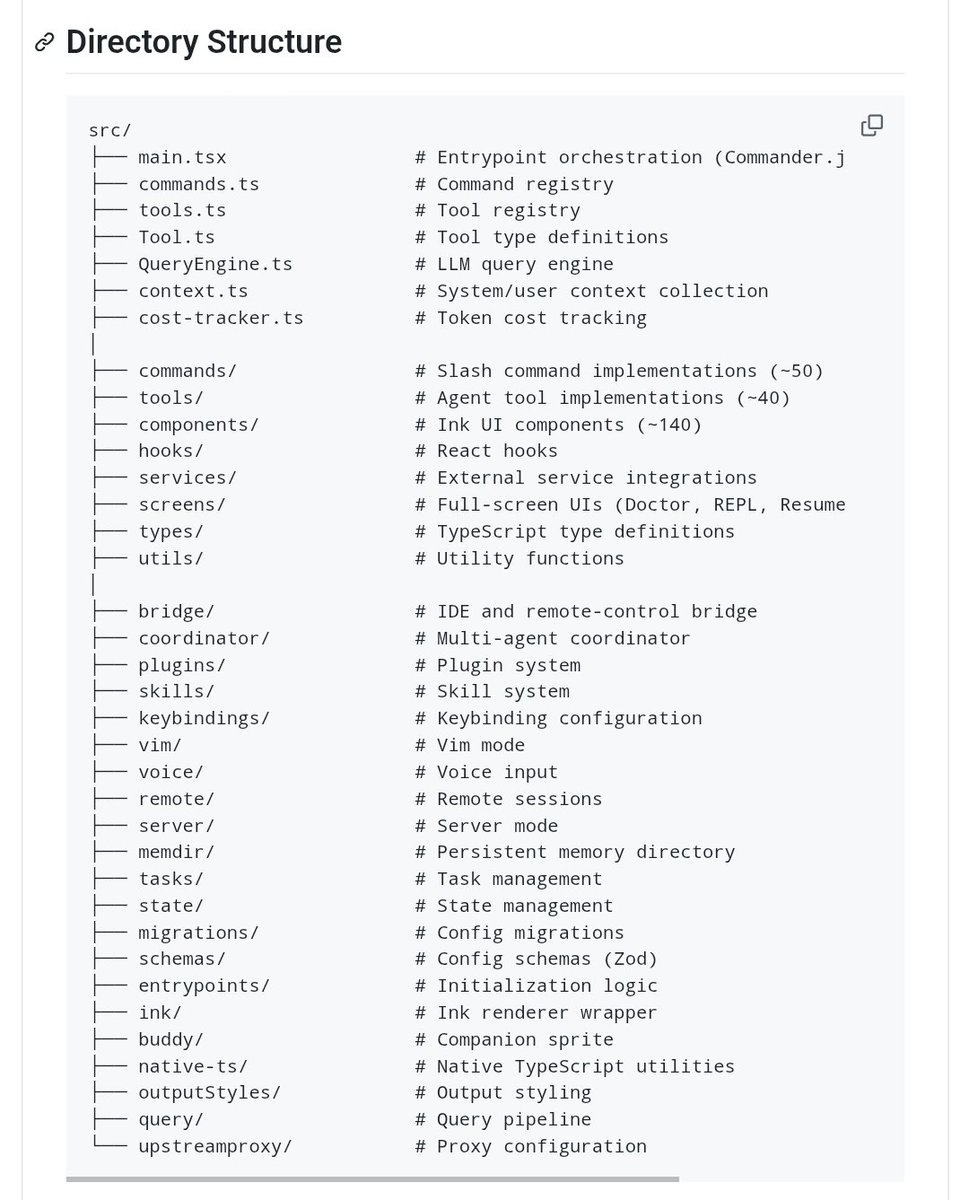
Built many bots. They all lost money.
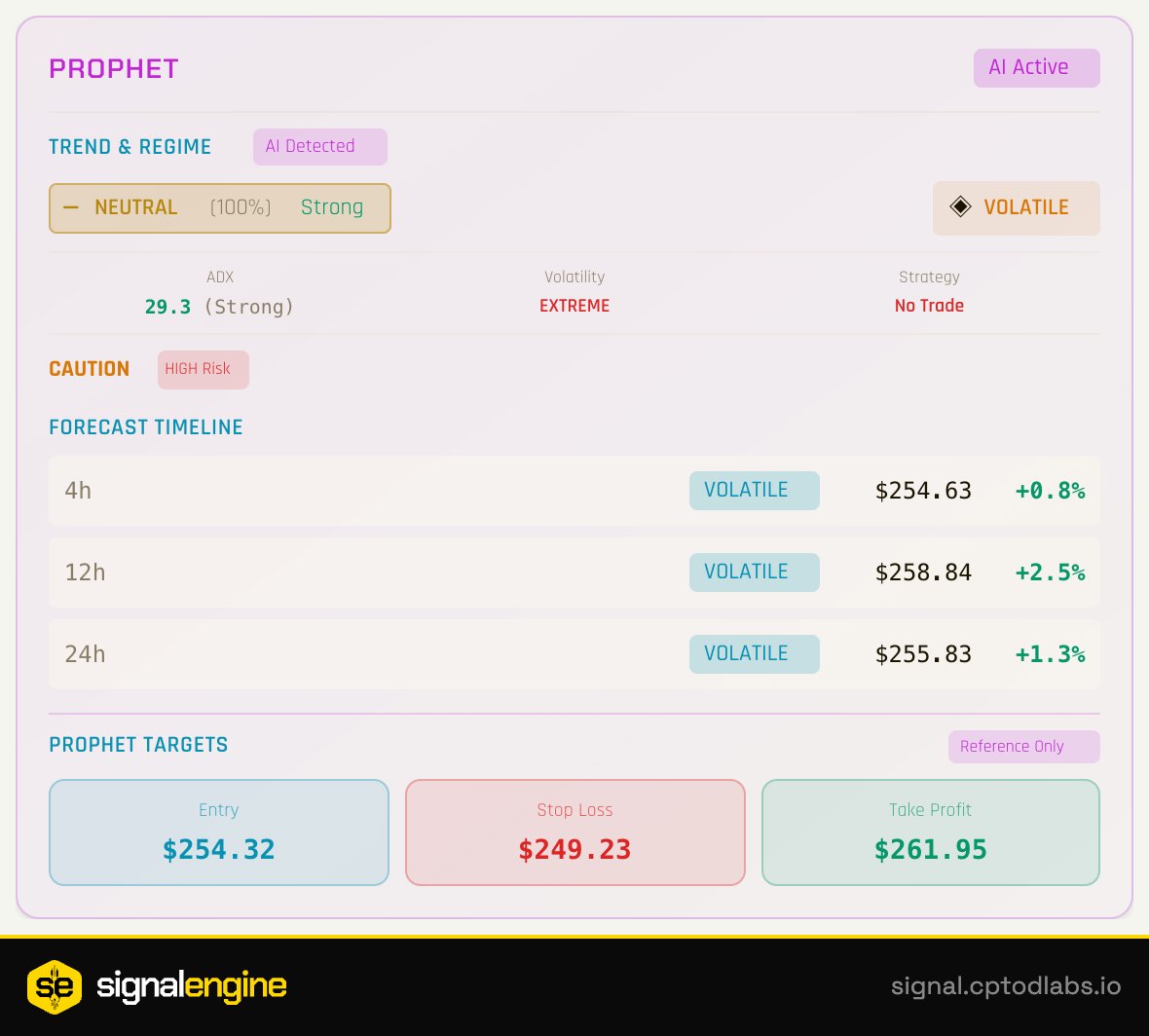
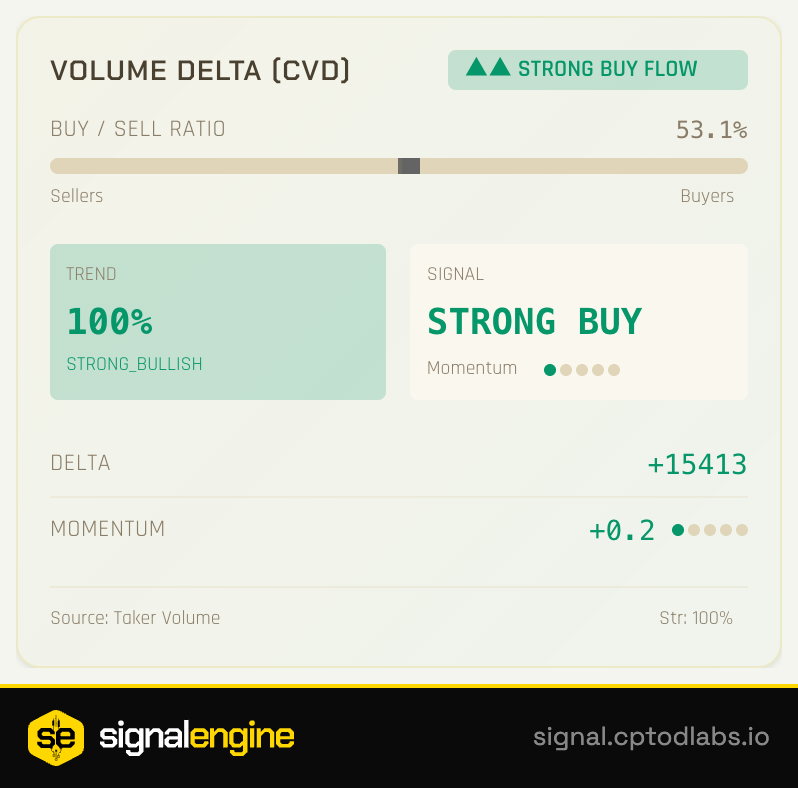
Made a painful pivot, took detours, deleted 7 strategies… and built signalEngine.
This is my honest journey — from envying coders to Vibe Coding with Claude in 500+ sessions.
Full story → x.com/CPTOverDraft/s…

English