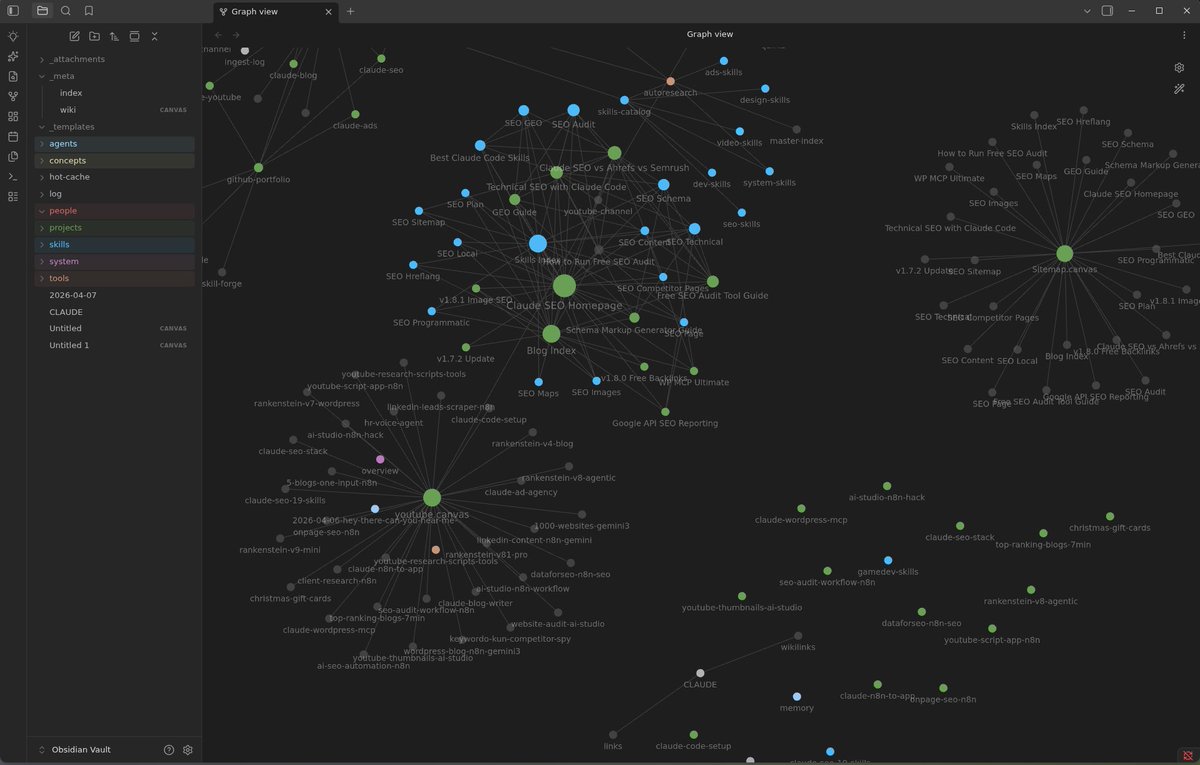
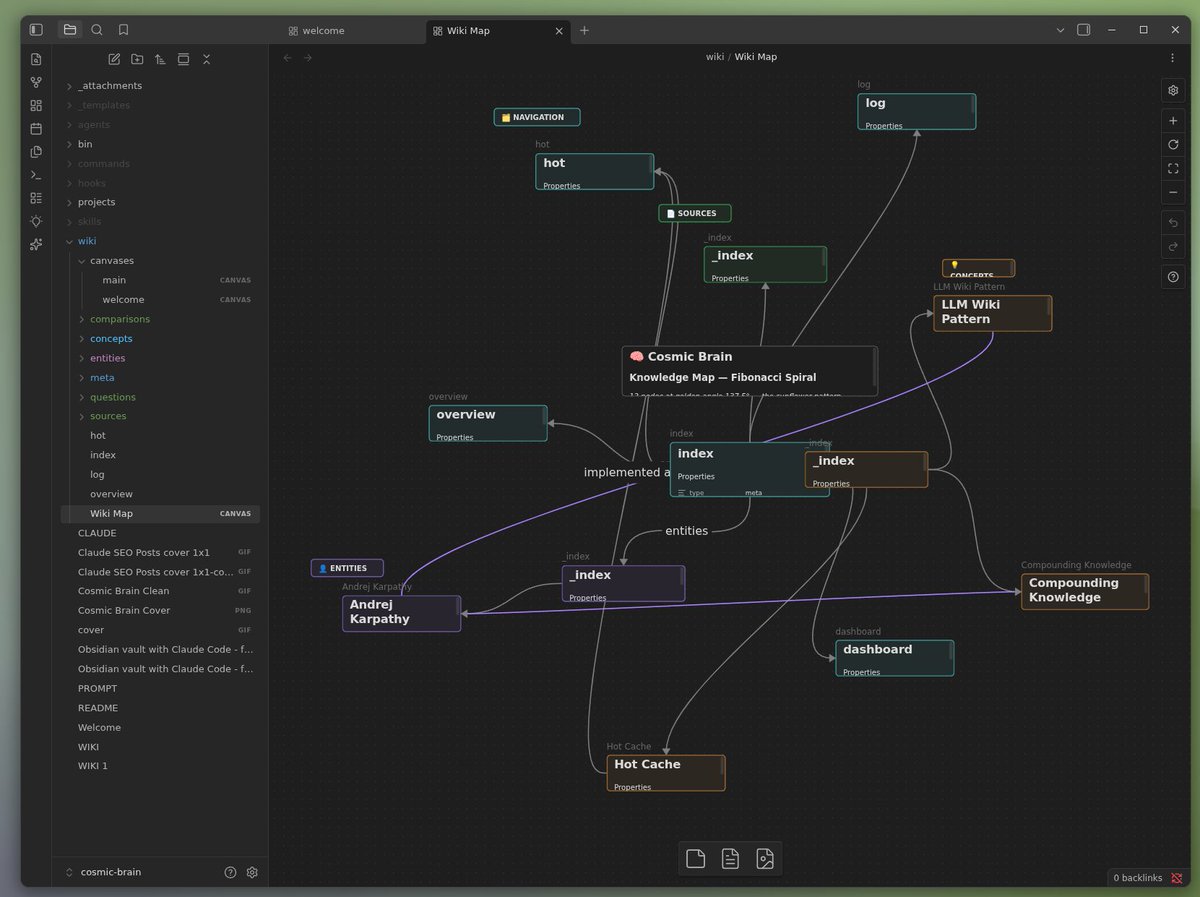
Eva รีทวีตแล้ว

🚨 This is absolute GOLD.
The @AnthropicAI engineer who literally wrote "Building Effective Agents" just dropped a 14-minute masterclass.
saves you months of headaches trying to figure this out alone.
bookmark for the weekend + read @Av1dlive's great guide below 👇
Avid@Av1dlive
English