ทวีตที่ปักหมุด
范师傅
182 posts


范师傅
@FanShifu
35岁 Non-coder 独立开发|AI出海 × 一人公司 上一段:逃离体制,卷国内电商(单人单月GMV 60万+) 小红书2个月跑通变现5万 每周复盘:产品·增长·心态·变现 🛠️真实第二曲线路径 → 💰
เข้าร่วม Nisan 2026
144 กำลังติดตาม60 ผู้ติดตาม
The scary part isn't that AI writes code faster than us. It's the line buried in here: human review is now the slowest step. Soon the thing slowing AI down won't be tech, it'll be us. Once "doing" costs nothing, humans go from driving the car to being the speed bump. Wild to sit with that.
English

Our internal data shows Claude is accelerating AI development—a possible path to recursive self-improvement, or AI autonomously building a more capable successor.
It’s happening faster than we thought, and the implications deserve greater attention. anthropic.com/institute/recu…
English

我知道的所有做AI Agent的团队都很拼,不是老板逼着的,是为了心中理想,所以心甘情愿加班和搞封闭开发👍
有点我好奇的是:Kimi 团队在开发 Kimi Code 的时候,是自家模型 token 用的多还是 Claude 或者 GPT 模型的 Token 用的多呢? 🤔
Kai@real_kai42
过去一个月是疯狂的一个月 大概一个月前,我下定决心重构 kimi-code,开始设计新的架构。 我大概抱着电脑和便携屏在汤泉卷了两整天,花了几千刀的 token 去做架构分析、设计和验证,最终得到了一份我认为最优的架构方案。 我觉得在 vibe 时代,架构变得更加重要了,一份好的架构能够在可控的范围内,让 Agent 肆意 coding,而不会打破东西 - 架构确定后,就开始冲刺实现。(过程中吵和推翻了无数次) - 迅速组建了一个强大的 team,感恩兄弟们无条件的信任🙇♂️ - 迅速 onboarding 整个 team,🙇♂️ 再次感恩兄弟们 - 封闭开发了一段时间(🤣年轻的时候,觉得是糟粕,真到时候,发现是人类工程效率奇迹。你无法想象随时可以拉着全部人在白板前吵架的架构迭代速度) - 虽然代码都是 vibe 的,但依旧逃不过 “代码质量正比于人类的注意力密度”。所以 agent 并不会替代所有程序员,只会让顶级的程序员生产力翻 20 倍,并淘汰其他程序员,且,集体主义 >>> 个人英雄主义。 - 一步一个坑的解决过程中遇到的问题。每一天都是最绝望的一天😭 - 开源后就病倒了,皮质醇分泌过度,影响免疫力 - 这一个月学的东西够我消化半年的 - 一周干了一整箱红牛,还得是生物燃料 - 🫥 也在 x 上消失了一个月 本来想写一些文章去总结过程中一些 insights 和 idea,但我本来就不擅长写长文,外加人脑自我保护让我迅速忘记了整个过程中的痛苦,并模糊了时间观念(冷知识,kimi-code 重构版开源其实才过了一周多,但在我的感性认知中,像是已经过了一个月) 等 kimi-code 陆续迭代到稳定,再去总结过程中的 lessons learned
中文

@heyshrutimishra Look at Reddit—stock popped on the back of one thing: it sits on a pile of real human conversation no one else can copy, so Google and OpenAI are paying to license it.
Same story here. The robot's the product everyone sees. The data layer is the actual bet.
English

The AI race is framed as compute vs compute. Chips, data centers, GPUs.
China found a cheaper move.
JD. com built a dedicated "data collection neighborhood" in Suqian. Residents get paid to film themselves doing household chores. Target: 10 million hours of robot training data over two years.
One person paid $22 for a 3-hour session. A robot came to their home, followed them around, and spent an hour folding three pieces of clothing.
"I feel like I made some contribution to physical AI," they said.
US companies outsource this kind of data collection to workers in developing countries because labor costs are too high domestically. China collects it locally, which means robots trained on Chinese homes, Chinese kitchens, Chinese habits. That's a distribution advantage.


English

$RDDT 的投资逻辑变了:它不只是一个交流社区,而是 AI 大模型的稀缺语料库。 91% 的毛利很大程度来自数据授权——这种“躺赚卖矿”的业务比卖广告舒服太多了。
只要大模型在卷,Reddit 上的真人语料就是最硬的硬通货。
Serenity@aleabitoreddit
$RDDT was driving me insane. > massive earnings beat > just printing FCF since they’re too profitable > 69% Y/Y revenue growth. > biggest moat against AI vibe coding from network effect > 91.5% gross margin. Was just flat for months. Glad to see it getting more attention.
中文
@aleabitoreddit selling "human-verified ore" is way more elite than just selling ads. As long as AI models keep scaling, Reddit’s real-human data remains the hardest currency in the market.
English

$RDDT was driving me insane.
> massive earnings beat
> just printing FCF since they’re too profitable
> 69% Y/Y revenue growth.
> biggest moat against AI vibe coding from network effect
> 91.5% gross margin.
Was just flat for months. Glad to see it getting more attention.

Serenity@aleabitoreddit
$RDDT is getting ridiculous. Looks completely mispriced. Now down 40% over the past few months. If you strip out carry-forward losses, their net profit is ~28% of revenue, which is absolutely enormous. And they’re growing forward revenues 50%+ Y/Y after 70%+ Y/Y growth. If you ever look at $META, you know how much revenue can be optimized/user. There’s an incredibly high ceiling for monetization with Reddit. It’s already derisked since IPO since Reddit is now one of the fastest growing and highest margin companies in the market. One day if it pulls a $CRCL post earnings, we’ll look back and wonder how this was valued at $24 billion MC.
English
Smart CFOs aren't doing a "total swap"; they're playing the "Model Mixing" game. Use DeepSeek for the high-frequency, heavy-lifting tasks (like massive data cleaning or RAG), while saving the big budget for GPT/Claude to handle the final logic. This combo delivers 90% cost savings without sacrificing the baseline of core business ops.
English

Something significant just happened in the US enterprise AI market (Save this).
According to Ramp's June 2026 trending software vendors index which tracks first time purchases from software vendors across thousands of US businesses, DeepSeek just hit the top spot, displacing every American AI provider in the breakout growth category.
To understand why that matters, you need to look at the Goldman Sachs pricing chart alongside it.
The Goldman Sachs exhibit lays out what is actually happening in the model pricing landscape across Chinese AI labs.
DeepSeek V4 Flash is priced at $0.10 per million input tokens and $0.30 per million output tokens and DeepSeek V4 Pro sits at $0.40 input and $0.90 output.
At the other end of the chart, Gemini 3.1 Pro Preview charges $2.00 input and $12.00 output more than 13 times more expensive for output tokens alone.
These are not minor pricing differences and they represent a structural cost collapse that is now showing up directly in enterprise purchasing behavior.
DeepSeek permanently locked in a 75% price cut on V4 Pro in late May, bringing output token costs to $0.87 per million compared to $10.00 for GPT-5 and $25.00 for Claude Opus.
That pricing gap is wide enough that CFOs are now making a rational economic calculation and the Ramp data shows the decision is already being made at scale.
On one side, the cost pressure is genuine and mounting, Uber burned through its entire annual AI budget in four months.
When a frontier-capable model costs 97% less than the American alternative on a per-token basis, the procurement case for the cheaper option becomes very hard to argue against from a pure efficiency standpoint.
On the other side, the data being routed through these systems is not trivial.
Companies are sending source code, customer records, legal documents, proprietary research, and internal strategic communications through AI interfaces.
The Cisco security evaluation found that DeepSeek's model failed to block a single harmful prompt across its entire attack test battery, a 100% vulnerability rate.
The Ramp data confirms that a growing number of US enterprises are making a choice to prioritize cost efficiency over data sovereignty, and they are making that choice right now.
This is the underlying force reshaping the entire AI model pricing landscape.

Negligible Capital@negligible_cap
DeepSeek is becoming more popular among US enterprises as companies look for cheaper alternatives to Anthropic and OpenAI “DeepSeek takes top spot on 'trending' list as companies look for alternatives to OpenAI and Anthropic, spending tracker's report says Chinese artificial intelligence start-up DeepSeek took the top spot on a major US business spending index in June, surging as more companies swap out expensive American options like OpenAI and Anthropic in favour of more affordable alternatives.” Nothing to see here
English
@_frederickjames Going from 0 to 140 MRR in 5 days is insane. This "sadness" is just your brain being spoiled by that initial spike. Bro, you’re outperforming 90% of us. Go touch some grass.
English

It's been a slow day.
And that makes me sad.
I need to remember I was on $0 just 5 days ago.
Now I'm at $140 MRR and $180 revenue.
Yearly subs are 🐐
I'm too hard on myself.
I'm obsessed with progress.
At the cost of my sleep, health, relationships.
Time to touch grass 🌾

English
@GoSailGlobal 拼多多5毛钱获客确实是神话,但对 SaaS 这种重决策产品来说,K 值能到 0.2 就烧高香了。毕竟 SaaS 裂变最难的不是给钱,而是让用户分享时不觉得是在消耗自己的职场信用。
中文



今天听到了一句最醍醐灌顶的话,直接把我整醒了!
老黄说:
真正会用AI的人,从来都不是让AI替自己思考,
而是极高认知的提问者——
带着自己的认知去提问,让AI帮你叩开未知的边界。
换句话说:
以道御术,前提是你得以术入道。
没有自己的「道」,再牛的AI工具在你手里,也只是一个高级玩具而已。
工具永远只是放大器,
真正拉开差距的,是你脑子里的那条「道」
GOLD@Honcia13
这绝对是我见过最牛的0基础 Vibe Coding 教程! 直接疯了GitHub 15k+ Star 神作, Easy-Vibe 从零带你玩转AI时代编程: -零基础入门(完全小白友好) -初中级开发 -高级实战 -甚至补齐计算机基础知识 不管你是纯小白,还是已经入门一点,都能收获巨大。 全程用自然语言 + AI 工具(Claude Code、Cursor 等) 真正实现「想到就能做到」。 datawhalechina.github.io/easy-vibe/zh-c… 强烈建议直接收藏 + 转发给想学编程的朋友! 这可能是2026年性价比最高的一条免费中文教程。
中文
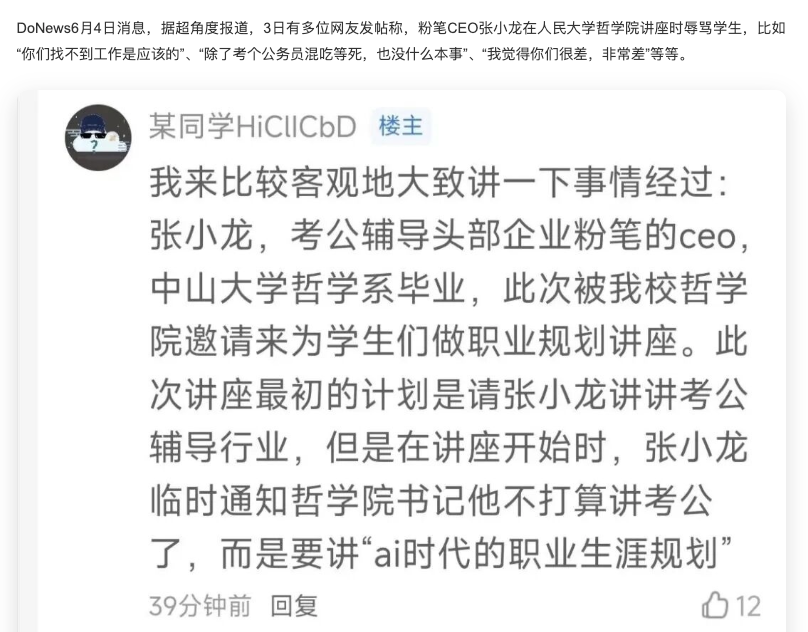
@yidabuilds 我当年考公上岸就报的粉笔,别看他这么神经,粉笔的口碑是他一手做起来的。
现在靠着考公人的学费实现了财富自由,转头就嘲讽还没上岸的人没本事,这种傲慢确实挺败好感的,只能说他最近炒美股炒的有点飘了。
中文




数字人无人直播这玩法,我研究完直呼内行。
一个讲相声的博主,用腾讯智影生成了个穿大褂的数字人,晚上挂无人直播。
评论区有人问“段子合集怎么买”→关键词自动回复→自动引导下单。
卖的是9.9的相声包,但直播间24小时循环播经典老段子。
他跟我说,每天早上睁眼第一件事就是看余额,多则三四百,少也有一两百。
睡着觉都在收钱,真正的睡后收入。
无人直播的玩法见评论区👇🏻
中文
最近在用手机 codex app 操作设计 sandbank agent(一套基于 deepseek v4 pro + GPT realtime 2 和 VAS 构建的跨沙箱 workspace harness)用 GPT image 2 做了个 sandbank 的宣传图,很可爱!

中文





English

Watched this video without skipping a second, absolute masterpiece 🤯
I learnt so many new things just from a 33 mins video which is insane!
Thanks @marclou for giving this banger and motivating us!
LFG 🔥

English
@zhangxiaojubtc 前端我是用Open Design生成设计稿,然后再投喂给codex还原,调几次之后复原程度还是不错的。当然前端设计还是Claude更强一些。
Bug 越改越坏,可能是续写逻辑在打架,根据报错重写可能比修改更管用。
中文
