ทวีตที่ปักหมุด
FatThor
5.6K posts


FatThor
@FatThory
Just keep DCA #bitcoin #farmersoon #tradersince1999 #father #photography Fav food: CCF, CTK, MSW Fav minum: Kopi C Kosong
on a beach somewhere เข้าร่วม Mart 2009
2.8K กำลังติดตาม828 ผู้ติดตาม
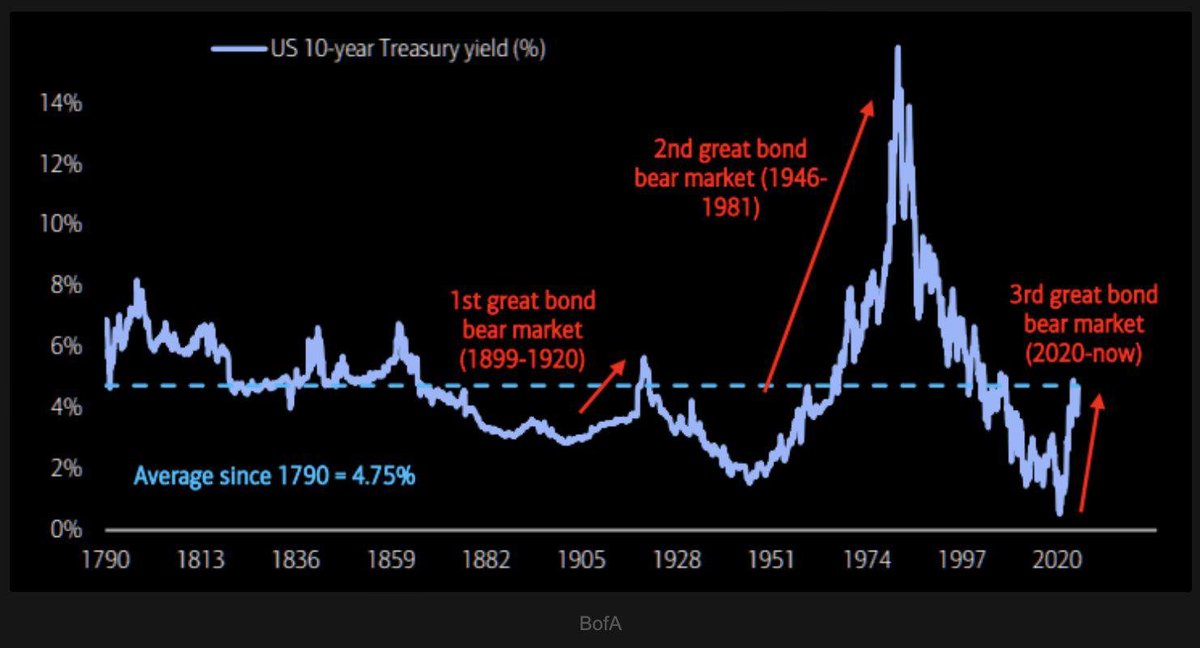
@Axel_bitblaze69 Download your favourite llms to run locally is safest. Can't be dumbed down.
English

I used Openclaw daily for months before i moved off.
tried every model through it multiple times.
My honest experience;
when i started, opus 4.6 was the king. not even close. everyone would agree on this.
i ran it on every serious task. trading research, code refactors, skill execution. it just worked.
sonnet 4.6 was my daily driver for anything that wasn't serious. cheaper, faster, didn't blow up the monthly cap.
then i started testing the rest,
grok 4.1 fast at $0.20 input / $0.50 output was insane value for high volume stuff.
real time x search, telegram bots, always on monitoring agents. i'd still use it today for that..
kimi k2.5 and k2.6 on free tier. nobody talks about this enough. for overnight agentic runs where you don't need perfection, this is free and it works.
k2.6 reportedly beats gemini 3.1 pro on agent benchmarks now.
gpt-5.4 i used for code reviews. second pair of eyes on opus output. caught stuff claude missed sometimes. but not good enough to replace opus.
gemini 3.1 pro was honestly mid.. "not bad, not impressive." used it when everything else was rate limited.
deepseek v3.2 for cheap fallback when the bill was getting scary.
minimax i tried for a week after seeing hype. there's a r/openclaw thread where a guy apologized for recommending it because it didn't hold up. same experience on my end.
then april 4 happened
anthropic killed oauth. the $200 magic died overnight. i was pissed for like 2 days. everyone was..
tried everything after that. hermes (by nous research) was smooth. claude code native with cron jobs was smoother. i picked native..
now here's the plot twist from last week, people are literally asking for 4.6 back.
also read somewhere that about every major model getting dumber in mid april.
claude, gemini, grok, people are noticing quality drops across the board right now.
my current stack is:
> claude code native with opus 4.7 for production code and deep research
> grok 4.1 fast for telegram agents, morning briefs, high volume low stakes stuff
> kimi k2.6 for overnight runs i don't want to pay for
> stopped trying to find one perfect model
Elon Musk@elonmusk
Try it out
English
@Excellion @Strategy And also bought from mining companies that are pivoting to AI. That's a lot of Bitcoin removed from circulation
English

It’s important to know that a good portion of the last 200,000 BTC that @Strategy bought was sold to them by people worried about Quantum Computers that don’t exist yet.
English
English
FatThor รีทวีตแล้ว

$MSTR
People ask me all the time why I’m 100% Strategy,
why I haven’t diversified into Bitcoin.
Let me start by saying this:
I think owning Bitcoin is a great idea.
I respect anyone who chooses that path.
My story is just different.
I only got curious about Bitcoin in 2020.
I kept hearing about this “crazy” CEO who had put everything into it.
Except he wasn’t crazy
And what flooded my feed back then was simple:
“This billionaire is going to lose everything.”
That’s what pulled me in.
Why would someone who’s already made it…
risk it all on this?
So I started digging.
I found Saylor.
His talks, his lectures, the way he explained Bitcoin.
And that’s when it clicked and that’s when I went down the rabbit hole.
The first real shift for me was trust.
Bitcoin teaches you not to trust but to verify.
And that principle is powerful.
But there are moments where you choose to trust someone’s vision.
History is built on that.
Builders, innovators, people who created systems we rely on today
at some point, people chose to trust them.
And Strategy earned that.
Saylor had the courage to risk everything:
his reputation, his life’s work, all for Bitcoin
Phong came from nothing, built himself up,
and still had the courage to stand beside that same decision
Both of them were willing to lose it all.
And that’s where alignment really started for me
The company opened everything up.
They showed people how they were doing it.
They shared the playbook.
They built in public from day one.
You could track the company.
You could see the decisions.
You could hear the thinking directly from them.
And when things didn’t go perfectly..they didn’t hide.
They adjusted.
Convertible bonds didn’t fully align the way they wanted.
Silvergate was a real risk.
Some of the early preferreds weren’t the perfect fit.
But they never stayed stuck on a mistake.
They kept moving.
They kept refining.
And eventually they found their version of an iPhone moment.
That’s what stood out to me.
you’re watching someone learn in real time, adapt, and keep pushing forward without losing conviction.
You get to align with someone who’s an educator, a thinker, a builder..
but more importantly, someone who has found what they’ve been chasing their whole life.
And now they’re locked in.
That rare.
Then came the disruption.
And this is where it goes beyond just a company.
They didn’t just embrace Bitcoin..
They changed how companies think about holding it.
They changed how capital is raised.
They changed how a balance sheet can be structured.
They changed how a company communicates with its shareholders.
They made it interactive.
They made it transparent.
They made people feel part of something.
And then they went after something even bigger.
Credit markets.
One of the largest pools of capital in the world.
That’s where you realize this was always the goal.
To plug Bitcoin into the system in a way that forces the system to evolve.
And the impact of that is everywhere.
It’s good for Bitcoin.
It’s good for equity holders.
It’s good for credit investors who want stability.
It’s good for companies watching this and realizing they can do the same.
It’s not one disruption.
It’s multiple layers hitting at once.
And if history has taught anything..
you don’t sit on the sidelines when that’s happening.
Even if I was late to Bitcoin,
I’m early to this.
And then comes the part I don’t even need to spend much time on.
Outperformance.
You get the alignment.
You get the trust.
You get to watch the disruption happen in real time.
And on top of that
you outperform the greatest asset the world has seen.
That’s when it became obvious to me.
It feels like catching Apple right when the iPhone was introduced.
A company changing the world
and changing my life at the same time.
This process has made me more patient.
It’s taught me how to deal with volatility.
It’s forced growth.
So when people ask why I’m 100% Strategy
that’s why.
$BTC $MSTR $STRC


English
FatThor รีทวีตแล้ว

MSTR closed on Friday at $166 per share
If Bitcoin closes the year at $162K (28.5% higher than previous ATH),
Assuming ZERO additional BTC Accumulation
$MSTR will have an Earnings Per Share of $166, EQUAL to the current stock price as of Friday's close.
The current composite average P/E ratio of the S&P 500 is 28x...
Let's have a week
English
FatThor รีทวีตแล้ว

Strategy has acquired 34,164 BTC for ~$2.54 billion at ~$74,395 per bitcoin and has achieved BTC Yield of 9.5% YTD 2026. As of 4/19/2026, we hodl 815,061 $BTC acquired for ~$61.56 billion at ~$75,527 per bitcoin. $MSTR $STRC strategy.com/press/strategy…
English
FatThor รีทวีตแล้ว

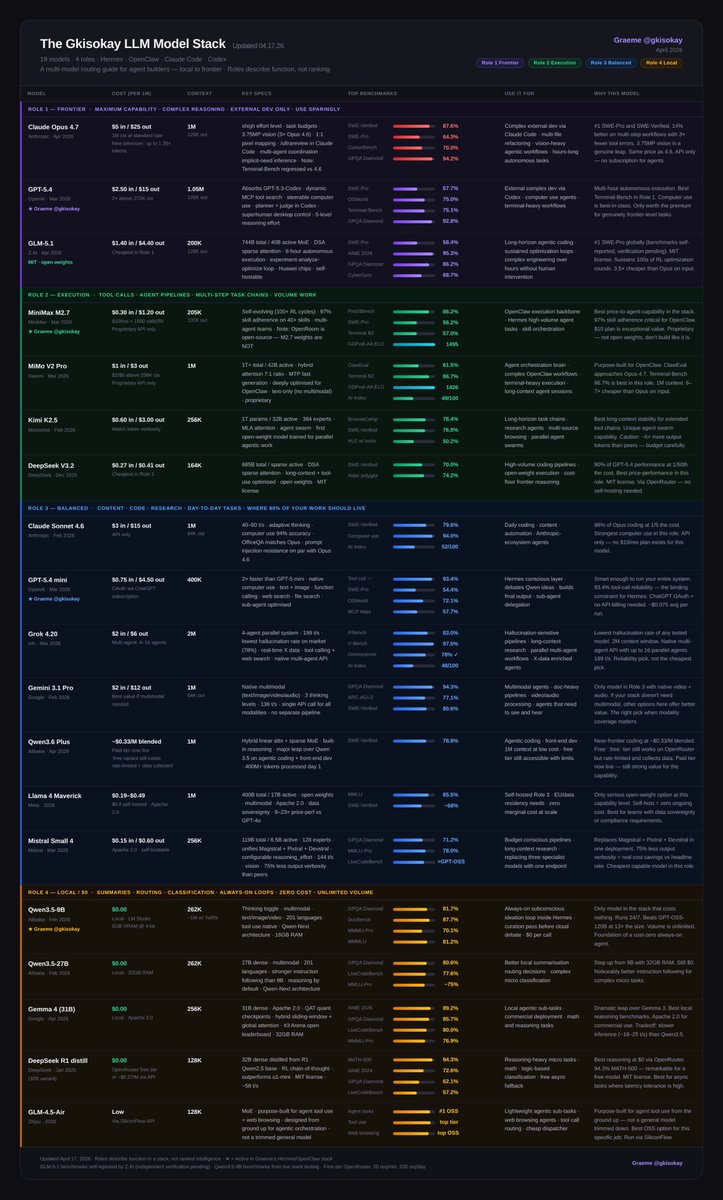
The LLM Cheat-Sheet for OpenClaw + Hermes agents (04.17.26)
Claude Opus 4.7 just dropped and replaces 4.6 at the same $5/$25 pricing.
SWE-Verified jumps to 87.6%, SWE-Pro to 64.3%, task budgets, and xhigh effort for agentic loops.
There's one caveat where the new tokenizer may use up to 35% more tokens per request so its the same price with a higher effective cost. Watch your limits.
MiMo V2 Pro joins Role 2. Xiaomi's agent-native model of 1T+ params, 42B active, 1M context, built specifically for OpenClaw/Hermes workflows.
Here's the full landscape: 19 models, 4 roles, every one earning its place.
Role 1 — Frontier
- Claude Opus 4.7: #1 SWE-Verified and SWE-Pro, 3.75MP vision
- GPT-5.4: best Terminal-Bench in Role 1, super app capabilities announced
- GLM-5.1: #1 SWE-Pro globally, 8-hour autonomous execution, MIT license
Role 2 — Execution
- MiniMax M2.7: 97% skill adherence, built for agents
- MiMo V2 Pro: purpose-built for OpenClaw, ClawEval approaches Opus 4.7, 1M context
- Kimi K2.5: long-horizon stability, agent swarm
- DeepSeek V3.2: frontier reasoning at 1/50th the cost
Role 3 — Balanced
- Claude Sonnet 4.6: 98% of Opus at 1/5 the cost
- GPT-5.4 mini: 93.4% tool-call reliability, runs on OAuth
- Grok 4.20: lowest hallucination rate on the market, native multi-agent, 2M context
- Gemini 3.1 Pro: only option with native video + audio. Pick it if your stack needs multimodal
- Qwen3.6 Plus: near-frontier coding and reasoning
- Llama 4 Maverick: open-weight, self-host at zero marginal cost
- Mistral Small 4: one model replacing three — reasoning, vision, and agentic coding, Apache 2.0
Role 4 — Local / $0 for 16GB/32GB (unquantized)
- Qwen3.5-9B: always-on subconscious loop, 16GB RAM, beats models 13x its size
- Qwen3.5-27B: stronger instruction following, 32GB RAM
- Gemma 4 31B: best local reasoning, Apache 2.0, commercial-ready
- DeepSeek R1 distill: best chain-of-thought at $0
- GLM-4.5-Air: purpose-built for agent tool use and web browsing, not a trimmed general model
Full breakdown with benchmarks, costs, and use cases in the table ↓
Graeme@gkisokay
The LLM Cheat-Sheet for Hermes + OpenClaw Agents (04.12.26) The community has flagged Claude Opus 4.6 underperforming lately while GLM 5.1 has exploded on the scene to claim frontier capabilities. A lot has changed since the last version. Here's what moved: GLM-5.1 just proved its frontier capabilities with #1 SWE-Pro globally, 8-hour autonomous execution, and cheaper than Opus on input. It earns a Tier 1 spot. Grok 4.20 enters Tier 2 with the lowest hallucination rate of any tested model, a native multi-agent API running up to 16 parallel agents, and a 2M context window. Gemini 3.1 Pro drops to Tier 3. The price and multimodal story is strong, but the new frontier bar left it behind on reasoning. Mistral Small 4 joins Tier 3. One model replacing three specialist pipelines (reasoning, vision, agentic coding) at $0.15/M input. Apache 2.0. Here's the full landscape: 18 models in 4 tiers. Tier 1 - Frontier Models - Claude Opus 4.6: #1 agentic terminal coding; watch for inconsistency reports - GPT-5.4: superhuman computer use, real planning. and introduced a $100/month plan - GLM-5.1: #1 SWE-Pro globally, 8-hour autonomous execution, MIT license Tier 2 - Execution - MiniMax M2.7: 97% skill adherence, built for agents. API only, not open weights - Kimi K2.5: long-horizon stability, agent swarm - Grok 4.20: lowest hallucination rate on the market, native multi-agent, 2M context - DeepSeek V3.2: frontier reasoning at 1/50th the cost Tier 3 - Balanced - Claude Sonnet 4.6: 98% of Opus at 1/5 the cost - GPT-5.4 mini: 93.4% tool-call reliability, runs on OAuth - Gemini 3.1 Pro: best multimodal value, native video+audio in one call - Qwen3.6 Plus: near-frontier coding, completely free via OpenRouter - Llama 4 Maverick: open-weight, self-host at zero marginal cost - Mistral Small 4: one model replacing three; reasoning, vision, agentic coding, Apache 2.0 Tier 4 - Local / $0 - Runs on 32GB RAM or less - Qwen3.5-9B: always-on subconscious loop, 16GB RAM, beats models 13x its size - Qwen3.5-27B: stronger instruction following, 32GB RAM - Gemma 4 31B: best local reasoning, Apache 2.0, commercial-ready - DeepSeek R1 distill: best chain-of-thought at $0 - GLM-4.5-Air: purpose-built for agent tool use and web browsing, not a trimmed general model Full breakdown with benchmarks, costs, and use cases in the table ↓
English
We now display Bitcoin Per Share (in sats) on our site: 205,812. $MSTR

English

I used Claude to code 2 TradingView indicators that are saving me hours every week.
1. Intraday Key Levels
2. NWOG + ORG + Stats
I’m giving both away completely free.
Like + Comment “INDICATORS” and I’ll DM them to you.
(Must be following)
English
FatThor รีทวีตแล้ว

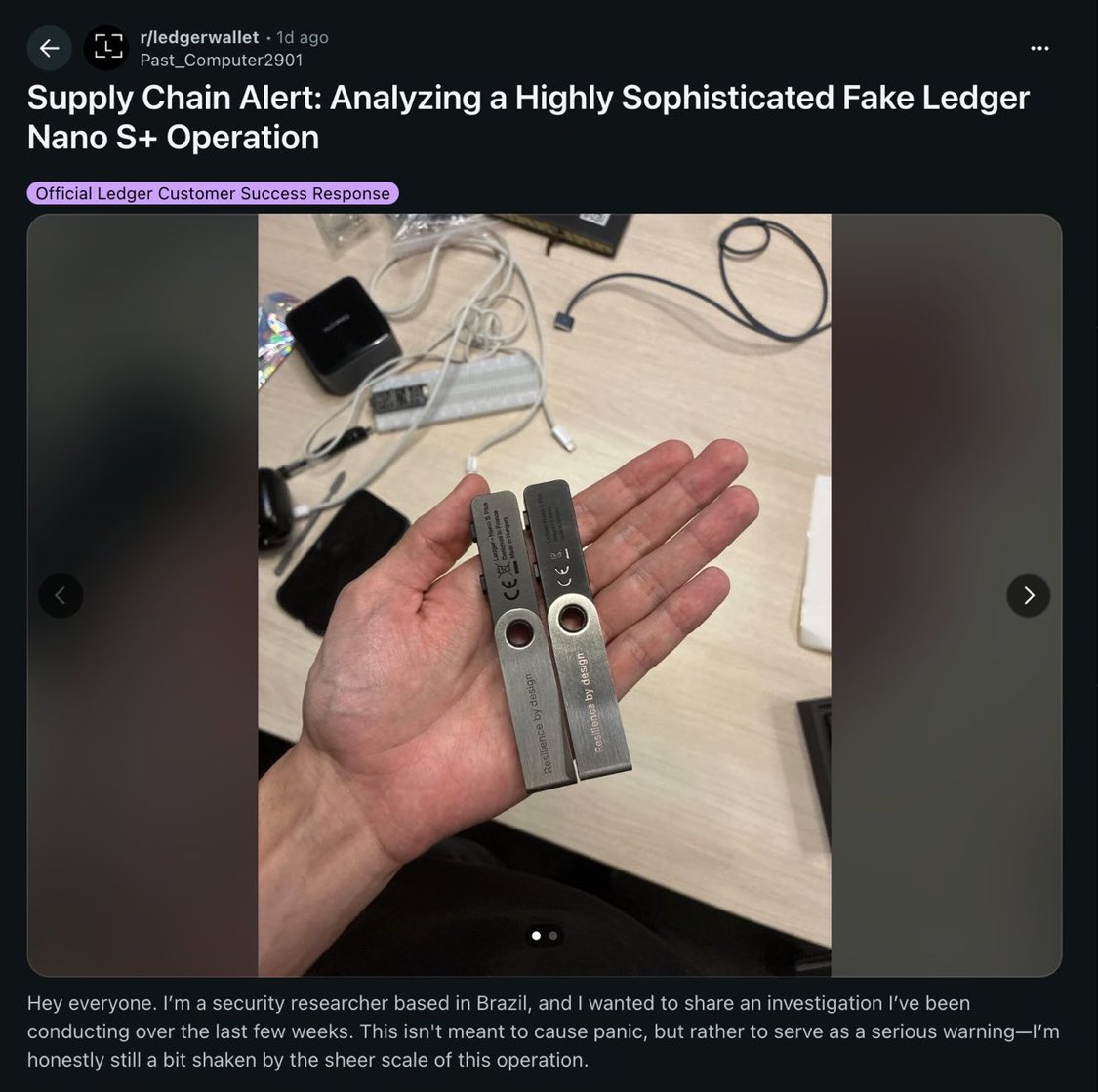
A security researcher just documented a large-scale counterfeit Ledger Nano S Plus operation selling compromised devices across multiple online marketplaces.
The fake units look identical to the real thing but contain completely different hardware. Instead of Ledger's secure element chip, the counterfeits run an ESP32 microcontroller with modified firmware labeled "Nano S+ V2.1." Seeds and PINs are stored in plain text and transmitted to attacker-controlled servers. Any wallet initialized on the device is drained.
The operation goes beyond the hardware. The sellers also distribute a fake version of Ledger Live built with React Native and signed with a debug certificate. It intercepts transactions and exfiltrates sensitive data to multiple command-and-control servers. The campaign spans five attack vectors: compromised hardware, Android APKs, Windows executables, macOS installers, and iOS apps distributed through TestFlight to bypass App Store review.
This comes days after ZachXBT documented a separate fake Ledger Live app that made it through Apple's Mac App Store review process. That operation drained over $9.5 million from more than 50 victims, including musician G. Love, who lost 5.92 BTC after entering his recovery phrase into what he believed was the legitimate app.
The pattern is clear: the attack surface for hardware wallet users has shifted from firmware exploits to supply chain and distribution fraud. The devices themselves remain secure. The problem is that users are being intercepted before they ever touch a real one.
Ledger's own "genuine check" feature can be bypassed when the hardware itself is compromised at the source, which makes where you buy the device as important as how you use it.
The rules haven't changed, but they've never been more important: buy hardware wallets only from the manufacturer. Never enter your recovery phrase into any software. If a companion app asks for your 24 words on a screen, it's a scam. Every time.
English

I put my entire Claude Code setup for GTM engineering into ONE Notion doc
10 modules. No fluff.
- How to install Claude Code and run your first GTM session in under 10 minutes
- How to build a CLAUDE. md that acts as your project brain and never loses context
- How to install GTM skills that chain together and run autonomously
- How to connect your full stack via MCP servers without writing custom wrappers
- How to run parallel agents and subagents across GTM workflows simultaneously
- How to manage context and token usage across long research sessions
- How to choose between Sonnet, Opus, and Haiku based on the task
- How to hook Claude Code into external triggers so workflows run without you
- The exact GTM workflows to build first: signal detection, lead scoring, outreach sequencing
- Full slash command reference for every repeatable GTM task
This is the setup I would have KILLED for before spending months piecing it together from documentation, YouTube tutorials, and scattered GitHub threads.
Like + comment "BIBLE" and I'll send it over
(must be connected for priority access)

English


FatThor รีทวีตแล้ว
Strategy has generated ₿17,585 of BTC Gain in the first two weeks of April, worth ~$1.3 billion. BTC Gain is the closest analog to Net Income on the Bitcoin Standard. $MSTR

English

i'm running a live claude cowork workshop for non-technical people on april 22
by the end of the 2 hours, you'll have a fully set up marketing system on your computer that:
> produces a full week of content in one sitting, dialed into your voice so it sounds like you on your sharpest day
> turns any marketing framework or post into a repeatable skill that claude runs on command for you
> builds sales pages in minutes so you stop paying designers and copywriters thousands
> schedules tasks to run while you sleep so you wake up to finished drafts, fresh ideas, and updated reports every morning
> writes launch emails, newsletters, and sequences using the same frameworks behind my 6-figure product launches
all click by click, on your machine, while i do it on mine
here's everything that you get:
• the full 2-hour live workshop where you build everything in real time
• 16 personal skills that i built over 100s of hours for my own business
• the complete recording so you can rewatch anytime
• a self-paced course version of all the material
• access to Claude Marketing OS telegram group
this system runs 90% of the marketing behind my 7-figure brand doing 15M+ impressions/month
and it's all yours come april 22nd
comment "Cowork" and i'll DM you the link

English
@PrajwalTomar_ Would be keen to learn how to set something similar up.
English

I DELETED EVERY SOCIAL MEDIA APP FROM MY PHONE AND I'M MORE INFORMED THAN EVER.
No Instagram. No X. No Reddit. None of it on my phone.
But I still know exactly what the top AI builders are posting, which YouTube tutorials are going viral, and what conversations on Reddit actually matter.
Perplexity Computer runs every morning before I wake up:
→ Scans X for posts from the 15 accounts I actually care about and flags anything with real traction
→ Monitors Reddit for viral AI projects and discussions blowing up in my niche
→ Finds YouTube videos getting unusual views in vibe coding and summarizes the key workflow
→ Delivers everything as a one-paragraph brief to my phone by 7 AM
Three platforms. Zero scrolling. Zero algorithm.
I get better signal from a 2-minute morning brief than I did from 3 hours of doomscrolling across all three apps.
The phone isn't the problem. The way we consume information is.
Drop a comment if you want the FULL setup.
English

2026 Claude is my full operating system.
After 300+ hours, I’ve built the ultimate AI blueprint:
- Claude Projects + Code + Cowork
- n8n MCP + SEO MCPs
- Opus 4.6 + Skills Blueprint
It's FREE For You.
Want the blueprint?
Like & RT
comment “Claude”
Follow @zakiraicoder For DM

English
FatThor รีทวีตแล้ว

My revised Ultimate Investment Thesis Guide For Strategy ($MSTR) following the 2025 Q4 Earnings Call is now LIVE. Includes:
✅ 1-Pager Summary
🧠 Mind Map
📖 Full Investment Thesis
⚡ Frequently Amplified Qualms (FAQ)
➕ And More
View and download it for FREE here: bit.ly/48253HM
Note: It reads better on desktop over mobile.
GIF
English