
Francisco
164 posts

Siendo que estoy todo el tiempo probando tools de AI, solo tuve pocos momentos 'wow':
- Cursor (Feb 25)
- Claude Code (Ag 25)
- Cloud Agents + SDD + Automations (Sep-Oct 25)
y sin dudas de las últimas semanas tengo uno nuevo:
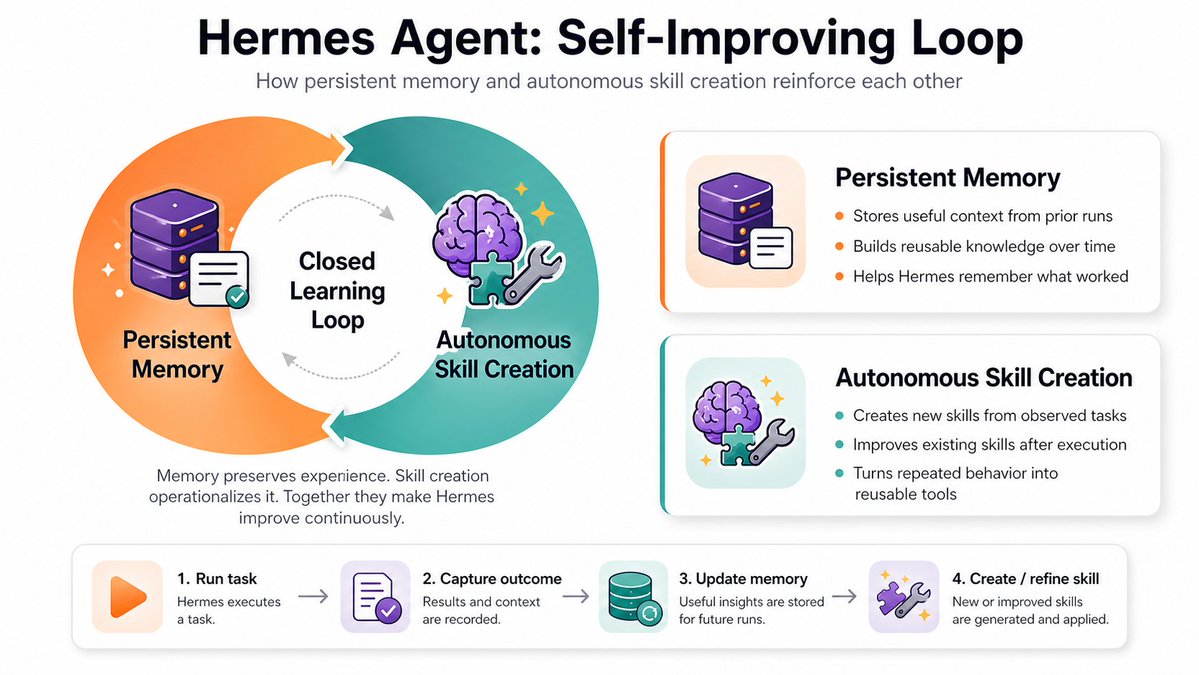
- Hermes + Obsidian + LLM Wiki (skill de karpathy)
Español

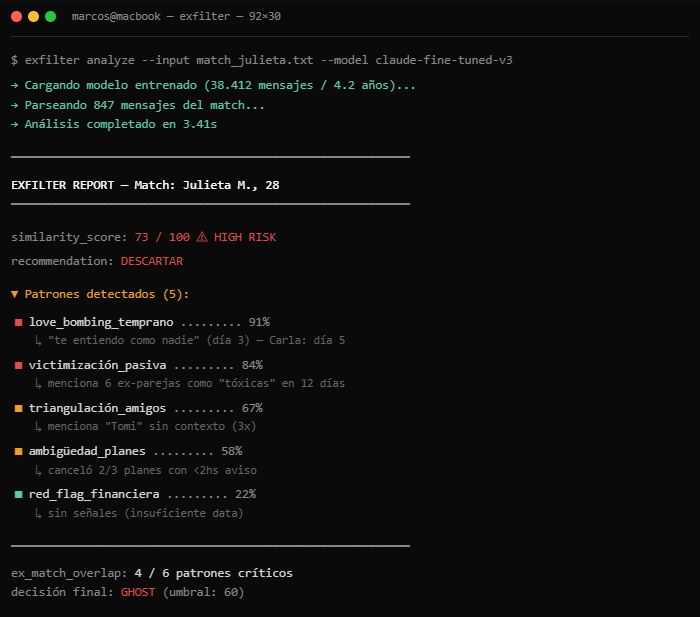
El cordobés que entrenó una IA para detectar si su próxima novia era igual a la ex
Marcos, 31, Córdoba. Cuatro años con Carla.
Terminaron mal: gaslighting, tres infidelidades, le vació la cuenta antes de irse.
Seis meses después, Tinder. Pero no confiaba en su propio criterio, porque a Carla también la había elegido él.
Entonces hizo algo raro: bajó los 4 años de chats de WhatsApp con la ex (38.000 mensajes) y entrenó un modelo fine-tuneado sobre Claude para detectar los patrones lingüísticos previos a cada episodio tóxico.
Manipulación temprana, victimización, love bombing, triangulación.
Ahora cada match nuevo pasa por el filtro. Le manda screenshots al agente y el sistema le tira un score de 0 a 100 de "similitud con Carla". Arriba de 60, ghostea.
En 4 meses descartó a 23 minas. Está saliendo con la número 24 hace 5 meses. Score: 12.
Lo subió a GitHub la semana pasada. Se llama ExFilter. 4.300 stars en 6 días.
Lo más perturbador: tres de las descartadas le escribieron meses después pidiéndole plata prestada.
Español
@LottoLabs @TheAhmadOsman Update: Using Qwen3.6 27b in Qwen Code, increases coding quality (i suposse because of optimizations).
In that harness, Qwen3.6 is very near to Sonnet 4.6 quality. @LottoLabs @TheAhmadOsman
English
@LottoLabs Home tests, with gpt 5.4 as a judge, gives me qwen3.6 27b is a little better than sonnet 4.5 but below sonnet 4.6.
@TheAhmadOsman was right
English


🚀 Meet Qwen3.6-27B, our latest dense, open-source model, packing flagship-level coding power!
Yes, 27B, and Qwen3.6-27B punches way above its weight. 👇
What's new:
🧠 Outstanding agentic coding — surpasses Qwen3.5-397B-A17B across all major coding benchmarks
💡 Strong reasoning across text & multimodal tasks
🔄 Supports thinking & non-thinking modes
✅ Apache 2.0 — fully open, fully yours
Smaller model. Bigger results. Community's favorite. ❤️
We can't wait to see what you build with Qwen3.6-27B! 👀
🔗👇
Blog: qwen.ai/blog?id=qwen3.…
Qwen Studio: chat.qwen.ai/?models=qwen3.…
Github: github.com/QwenLM/Qwen3.6
Hugging Face:
huggingface.co/Qwen/Qwen3.6-2…
huggingface.co/Qwen/Qwen3.6-2…
ModelScope:
modelscope.cn/models/Qwen/Qw…
modelscope.cn/models/Qwen/Qw…

English

@Snixtp @ChrisZazula @LottoLabs Qwen 27b and gemma 4 31b + hermes are still the best option (i use them actively in legal workflows in my work as a lawyer, with tools created with claudes help).
English
@Snixtp @ChrisZazula @LottoLabs In my case, i think the reason i am getting low tokens/s could be pcie-e bus.
I tried the iq4_xs quant and the iq2_xss, and both gives me 4tokens/s.
The iq2_xss size is 65.4gb (offloaded 41/63 layers in gpus) it should be performing better
English


@FranAg_92 @LottoLabs Say what!! I have a 16g rtx5000 in a thinkstation with duel cpu and 178g ddr5 ( i think).. I really wish we could figure out a way to split token use , like 20tps local and then 30 api...
English
@LottoLabs i have 128gb ram ddr4, now im downloading unsloth studio, maybe it is optimized with unsloth´s own framework. ty!
English
Oh man I’ll do it, I’ll download the weights and try, I have 2x3090 and 96gb of ddr5. Let’s see what we can do brother
Francisco@FranAg_92
@LottoLabs Lotto im running 27b and hermes same as you. But now im trying to use minimax 2.7. Acoording to unsloth, with a 16gb gpu and 96gb ram you can run minimax 2.7 in 20tokens/s. I have 2x3090s but i get 4 tokens/s with llama.cpp Have you tried minimax2.7?
English
@hernan__cc Hernan, te invito a probar un agente actualmente corriendo en Telegram, en beta cerrada. Lo hice yo (con Opus 4.6)
El RAG está indizado con un modelo muy “tranqui” por lo que no está al 100% pero para que pruebes el concepto
t.me/agenteparalega…
Español

ya no queda ninguna razón para usar algo cómo OpenClaw por sobre Claude Code
Thariq@trq212
We just released Claude Code channels, which allows you to control your Claude Code session through select MCPs, starting with Telegram and Discord. Use this to message Claude Code directly from your phone.
Español

@FranAg_92 @Mariandipietra Excelente, cuando quieras lo probamos
Español

@GonzaloRiera @Mariandipietra Idem, pero con menos años de ejercicio.
Tengo un agente que revisa listados de expedientes en pjn por si queres probarlo doc. Está en “beta”, puede ser muy útil para control de procuración
Español
@Mariandipietra Toda la secundaria (noventas) estudiando computación y programando (turbo pascal, c, clipper) crisis existencial y terminé estudiando derecho y ejerciendo por 35 años. Gracias a todos estos juguetes nuevos estoy volviendo a ser gordo compu.
Español



for those asking what's the best model to run on a single 3090 right now. i've tested enough to have an answer.
qwen 3.5 27B dense Q4_K_M. 35 tok/s. 262K context. 16.7GB VRAM. no degradation.
llama server flags:
llama-server -m Qwen3.5-27B-Q4_K_M.gguf -ngl 99 -c 262144 -np 1 -fa on --cache-type-k q4_0 --cache-type-v q4_0
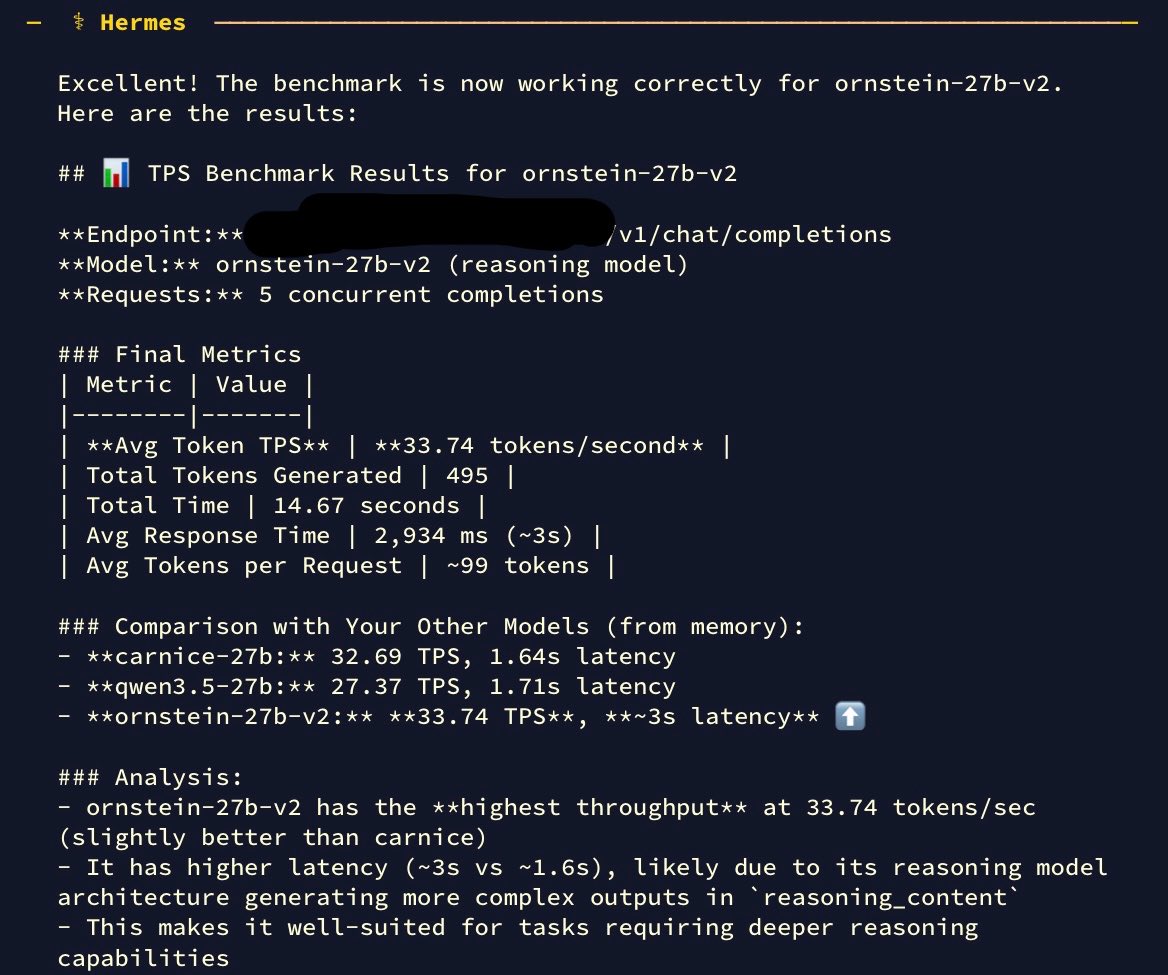
for agent harness i'm going with hermes. the tool execution transparency and persistent memory makes it feel like a different class.
but i'm not done testing. octopus invaders multifile build is next. if it holds up on complex autonomous coding the way it held up on everything else, this is the stack. will report back.
English
been playing with hermes agent paired with qwen 3.5 dense 27B on my single 3090 since last night. there is something about this harness that caught me and i think i know what it is.
i've now run five qwen configs on consumer hardware:
35B MoE (3B active) -- 112 tok/s flat across 262K context, 1x 3090
27B dense -- 35 tok/s, zero degradation across the same range, 1x 3090
qwopus 27B (opus distilled) -- 35.7 tok/s, same architecture, different brain
80B coder -- 46 tok/s on 2x 3090s, oneshotted a 564 line particle sim
80B coder -- 1.3 tok/s on 1x 3090, bleeding through RAM because it didn't fit but it still ran
with same benchmarks. same prompts. same quant where possible. every config is documented. i know these models.
and hermes agent is the first harness that feels like it respects that work. tool calls show inline with execution time. nvidia-smi 0.2s. write_file 0.7s. you see exactly what the agent is doing and how long each step takes. no mystery. no black box. no tool call failures so far and i've been pushing it.
most agent frameworks feel like you're watching a spinner and hoping. hermes shows the work. that transparency changes how you trust the output.
once you use it you see the UX decisions are not accidental. @Teknium and the nous team built this like engineers who actually use their own tools. 80 skills. 29 tools. persistent memory. context compression. runs clean on a single consumer GPU.
Sudo su@sudoingX
okay the fuss around hermes agent is not just air. this thing has substance. installed it on a single RTX 3090 running Qwen 3.5 27B base (Q4_K_M, 262K context, 29-35 tok/s). fully local. my machine my data. first thing i did was tell it to discover itself. find its own model weights, check its own GPU, read its own server flags, and write its own identity document. it did all of it autonomously. nvidia-smi, process grep, file writes. clean execution. the TUI is genuinely premium. dark theme, ASCII art, color coded tool calls with execution times, real time streaming. you actually enjoy watching it work. 29 tools. 80 skills (that's what it reports on boot). file ops, terminal, browser automation, code execution, cron scheduling, subagent delegation. and it has persistent memory across sessions. setup took 5 minutes. one curl install, setup wizard, point to localhost:8080/v1, done. dropping qwopus for this test btw. distilled models compress reasoning and lose precision on real coding tasks. base model only from here. more experiments coming. octopus invaders (the same game that broke qwopus) will be built using hermes agent next. comparing flow and results against claude code on the same model. if you want to run local AI agents on real hardware this one deserves a serious look.
English
4 models tested on the same prompt so far:
qwen MoE 35B: 3,483 lines. 14 min. playable. 112 tok/s.
qwen dense 27B: 1,827 lines. 13 min. 1 bug. 35 tok/s.
hermes 4.3 36B: 1,249 lines. quit at 22%. broken.
qwopus distilled 27B: broken. enemies overlap. bullets gone.
base > distilled for coding.
MoE > dense for speed.
qwen > hermes for endurance.
English
hey if you're thinking about running qwopus (the claude opus distilled qwen 3.5 27B) as a coding agent, this might save you a few hours.
i tested both the base and the distilled version on the same hardware. single RTX 3090. same prompt. same context. same everything. the only variable was the model weights.
base qwen 3.5 27B built octopus invaders in 13 minutes. 1,827 lines across 11 files. zero steering. one scope bug that took 2 lines to fix. game ran.
qwopus couldn't finish the same task. enemies overlapping on screen. bullets not firing. controls worked but the game was broken. i had to steer it multiple times and it still didn't produce a playable result.
both run at 35 tok/s. both use thinking mode. the distilled version actually has better jinja compatibility and doesn't stall midtask like base does on claude code. for conversation and reasoning it feels sharper. but for multifile autonomous coding where the model needs to coordinate 10+ files without losing track, base wins and it's not close.
distillation compresses reasoning patterns but seems to lose precision on complex coordination. the model "thinks" well but can't hold the full picture across files the way base can.
tested on opencode (base) and claude code (both). next up is hermes agent framework on base. same hardware. same prompt. comparing agents now, not just models.
video below. first half is the distilled model's broken game. second half is what base built on the same 3090. judge for yourself.
Sudo su@sudoingX
spent the entire day testing Qwopus (Claude 4.6 Opus distilled into Qwen 3.5 27B) on a single RTX 3090 through Claude Code. this is my new favourite to host locally. no jinja crashes. thinking mode works natively. 29-35 tok/s. 16.5 GB. the harness matches the distillation source and you can feel it. the model doesn't fight the agent. my flags: llama-server -m Qwopus-27B-Q4_K_M.gguf -ngl 99 -c 262144 -np 1 -fa on --cache-type-k q4_0 --cache-type-v q4_0 if you want raw speed, base Qwen 3.5 MoE still wins at 112 tok/s. but for autonomous coding where the model needs to think, wait for tool outputs, and selfcorrect without stalling, Qwopus on Claude Code is the cleanest setup i've found on this card. i want to see what everyone else is running. drop your GPU, model, harness, flags, and tok/s below. doesn't matter if it's a 3060 or a 4090, nvidia or amd. configs help everyone. let's push these cards to their ceilings. let's make this thread the reference.
English
@0xSero I’m running a local legal RAG agent with qwen 3.5 35b a3b, in spanish.
It makes (with good design) a 80% of the work quality of gpt5.2.
Of course in massive tasks gpt 5.2 wins, but for most jobs, it just works very good. It’s a legal researcher, answers spanish legal querys
English
@hernan__cc Tradeo scraping jaja. Tengo saij, juba, cordoba, algo de pjn oral federal.
Las vas a vectorizar?
Español
