ทวีตที่ปักหมุด

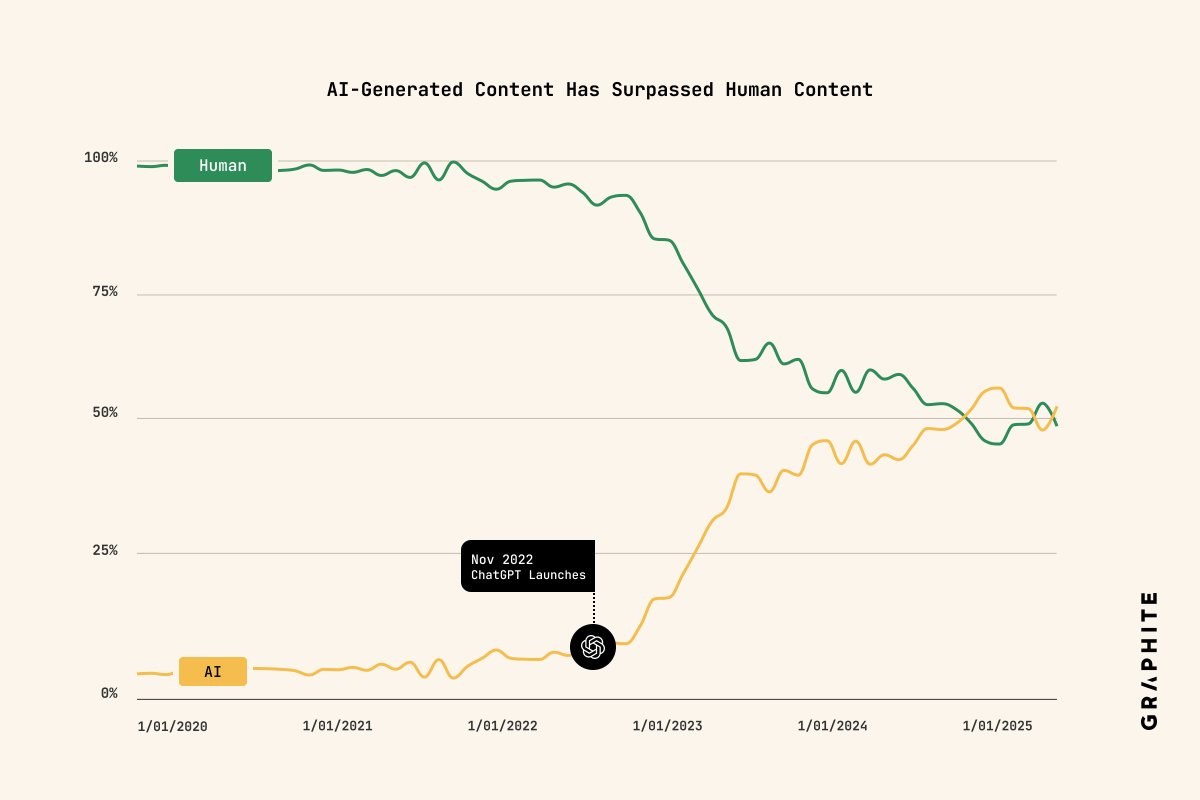
People's minds are blown when they find out you can use a blockchain for something other than trading crypto
Crazy, right??
Bryan Pellegrino (臭企鹅)@PrimordialAA
Lol wat? My wife brought this pasta sauce home tonight… what blockchain does this use lmao?
English