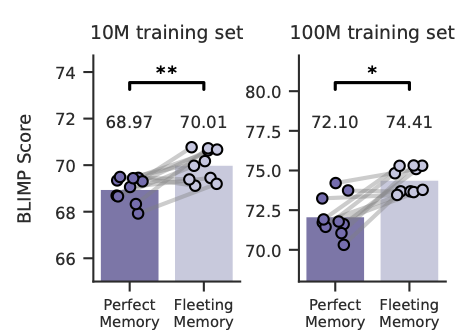
ทวีตที่ปักหมุด

New result! A theory of @AdrianDu_'s data, where we model distributions of tuning curves.
-Random connection brings symmetry 🌈
-SVD revealed the distribution of Fourier coefficients 🥳
-The model is a null-hypothesis usable anywhere in the brain
With @apeyrache and @AdrianDu_
English