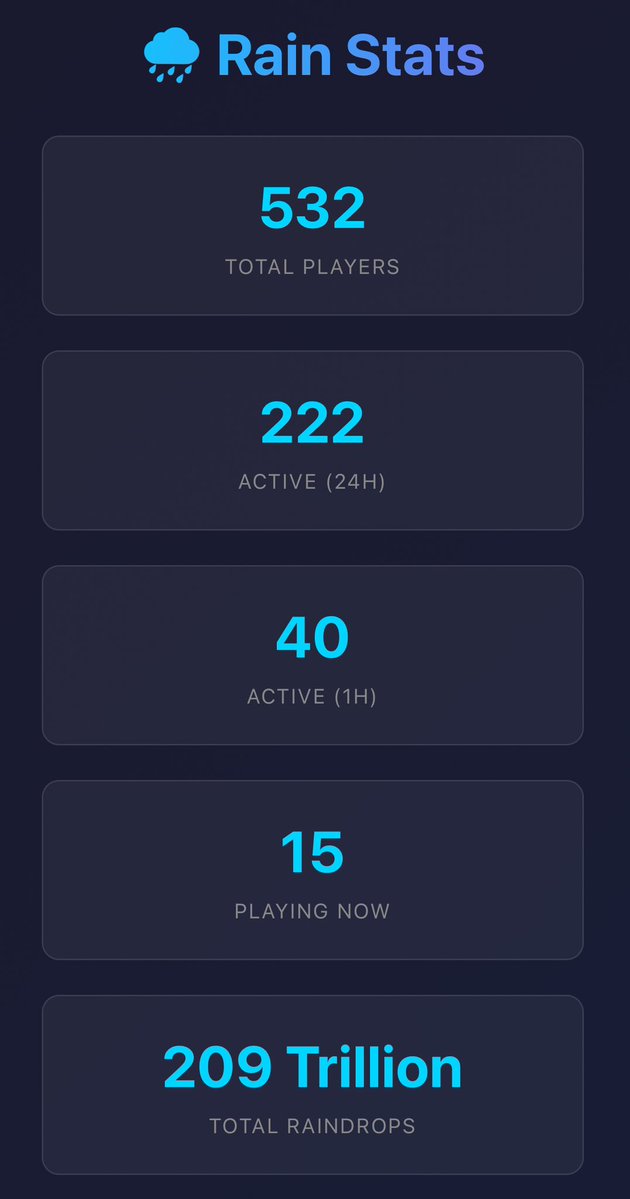
ทวีตที่ปักหมุด

Started actively working on the next codecrafters.io challenge today: "Build your own SQLite".
I've got the stages planned out, now onto building the test cases and trying the challenge out myself.
Will post updates here as I go.
CodeCrafters@codecraftersio
Announcing our next challenge: "Build your own SQLite". In this challenge, you'll build a barebones SQLite implementation that supports basic SQL commands like SELECT/INSERT. Along the way we'll learn about SQLite's file format, your indexed data is stored in B-trees and more.
English