

Sam Stolt รีทวีตแล้ว

Anthropic accidentally leaked their entire source code yesterday. What happened next is one of the most insane stories in tech history.
> Anthropic pushed a software update for Claude Code at 4AM.
> A debugging file was accidentally bundled inside it.
> That file contained 512,000 lines of their proprietary source code.
> A researcher named Chaofan Shou spotted it within minutes and posted the download link on X.
> 21 million people have seen the thread.
> The entire codebase was downloaded, copied and mirrored across GitHub before Anthropic's team had even woken up.
> Anthropic pulled the package and started firing DMCA takedowns at every repo hosting it.
> That's when a Korean developer named Sigrid Jin woke up at 4AM to his phone blowing up.
> He is the most active Claude Code user in the world with the Wall Street Journal reporting he personally used 25 billion tokens last year.
> His girlfriend was worried he'd get sued just for having the code on his machine.
> So he did what any engineer would do.
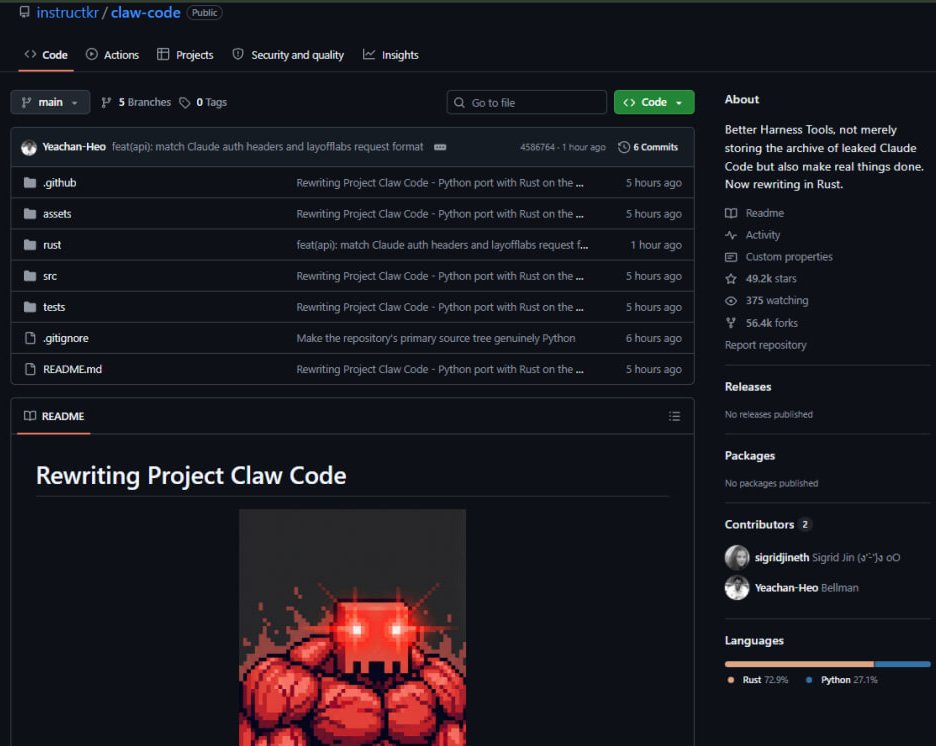
> He rewrote the entire thing in Python from scratch before sunrise.
> Called it claw-code and Pushed it to GitHub.
> A Python rewrite is a new creative work. DMCA can't touch it.
> The repo hit 30,000 stars faster than any repository in GitHub history.
> He wasn't satisfied. He started rewriting it again in Rust.
> It now has 49,000 stars and 56,000 forks.
> Someone mirrored the original to a decentralised platform with one message, "will never be taken down."
> The code is now permanent. Anthropic cannot get it back.
Anthropic built a system called Undercover Mode specifically to stop Claude from leaking internal secrets. Then they leaked their own source code themselves. You cannot make this up.
English












