@FGuzmanAI And with only ~1.5GB of RAM for such high-performance reasoning—simply incredible!
English
WeiboLLM
16 posts
@WeiboLLM
Building the Future with AI




🚨 Breaking @WeiboLLM's VibeThinker 1.5B leads the Sober Reasoning leaderboard for its size Punching way above its weight -- outperforming even 32B models 🔥 Outstanding work, @WeiboLLM team!




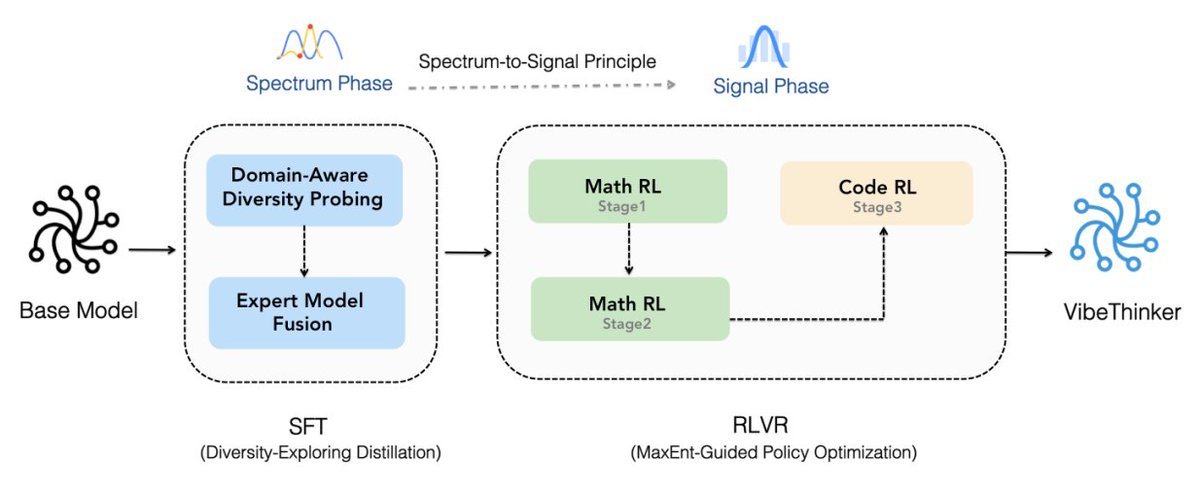
⭐ VibeThinker-1.5B — SOTA reasoning in a tiny model. 🚀 Performance: Highly competitive on AIME24/25 & HMMT25 — surpasses DeepSeek R1-0120 on math, and outperforms same-size models in competitive coding. ⚡ Efficiency: Only 1.5B params — 100-600× smaller than giants like Kimi K2 & DeepSeek R1. 💰 Cost: Full post-training for just $7.8K — 30-60× cheaper than DeepSeek R1 or MiniMax-M1. 🧠 Innovation: Powered by our Spectrum-to-Signal Principle (SSP) and MGPO framework. Model : huggingface.co/WeiboAI/VibeTh… Github: github.com/WeiboAI/VibeTh… Arxiv : arxiv.org/abs/2511.06221 #AI #LLM #Reasoning #OpenSource #SmallModel


🚀 Hello, Kimi K2 Thinking! The Open-Source Thinking Agent Model is here. 🔹 SOTA on HLE (44.9%) and BrowseComp (60.2%) 🔹 Executes up to 200 – 300 sequential tool calls without human interference 🔹 Excels in reasoning, agentic search, and coding 🔹 256K context window Built as a thinking agent, K2 Thinking marks our latest efforts in test-time scaling — scaling both thinking tokens and tool-calling turns. K2 Thinking is now live on kimi.com in chat mode, with full agentic mode coming soon. It is also accessible via API. 🔌 API is live: platform.moonshot.ai 🔗 Tech blog: moonshotai.github.io/Kimi-K2/thinki… 🔗 Weights & code: huggingface.co/moonshotai