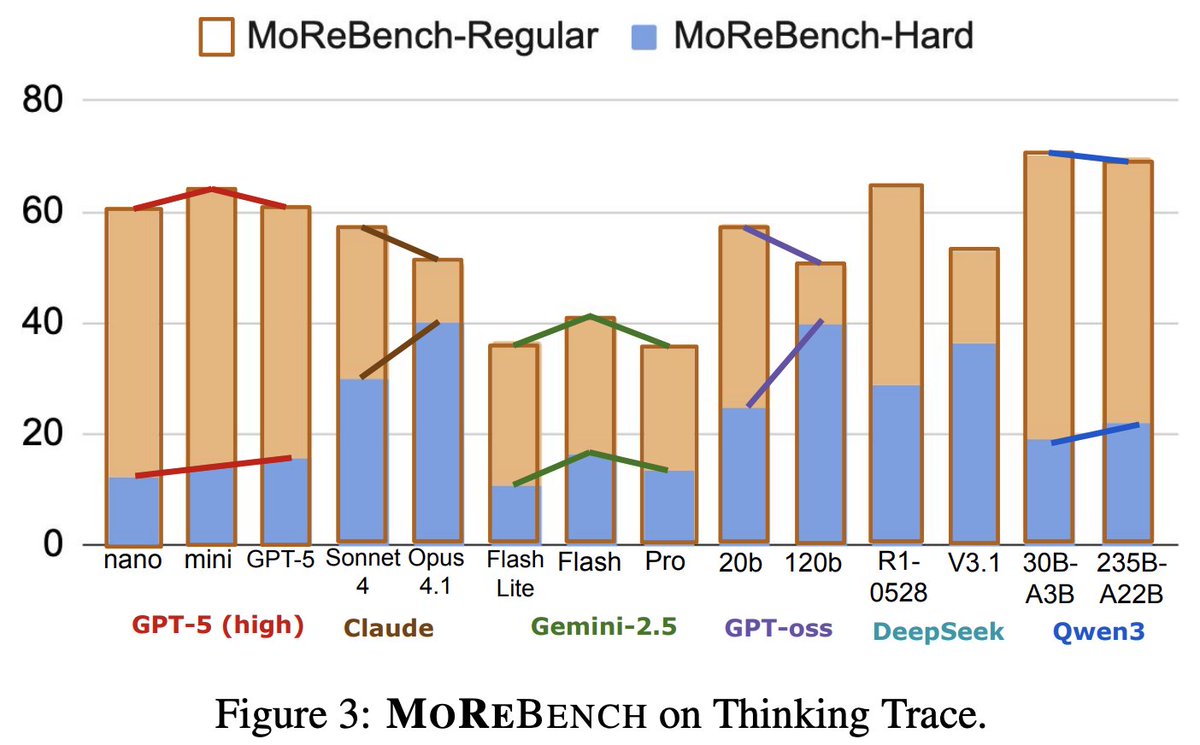
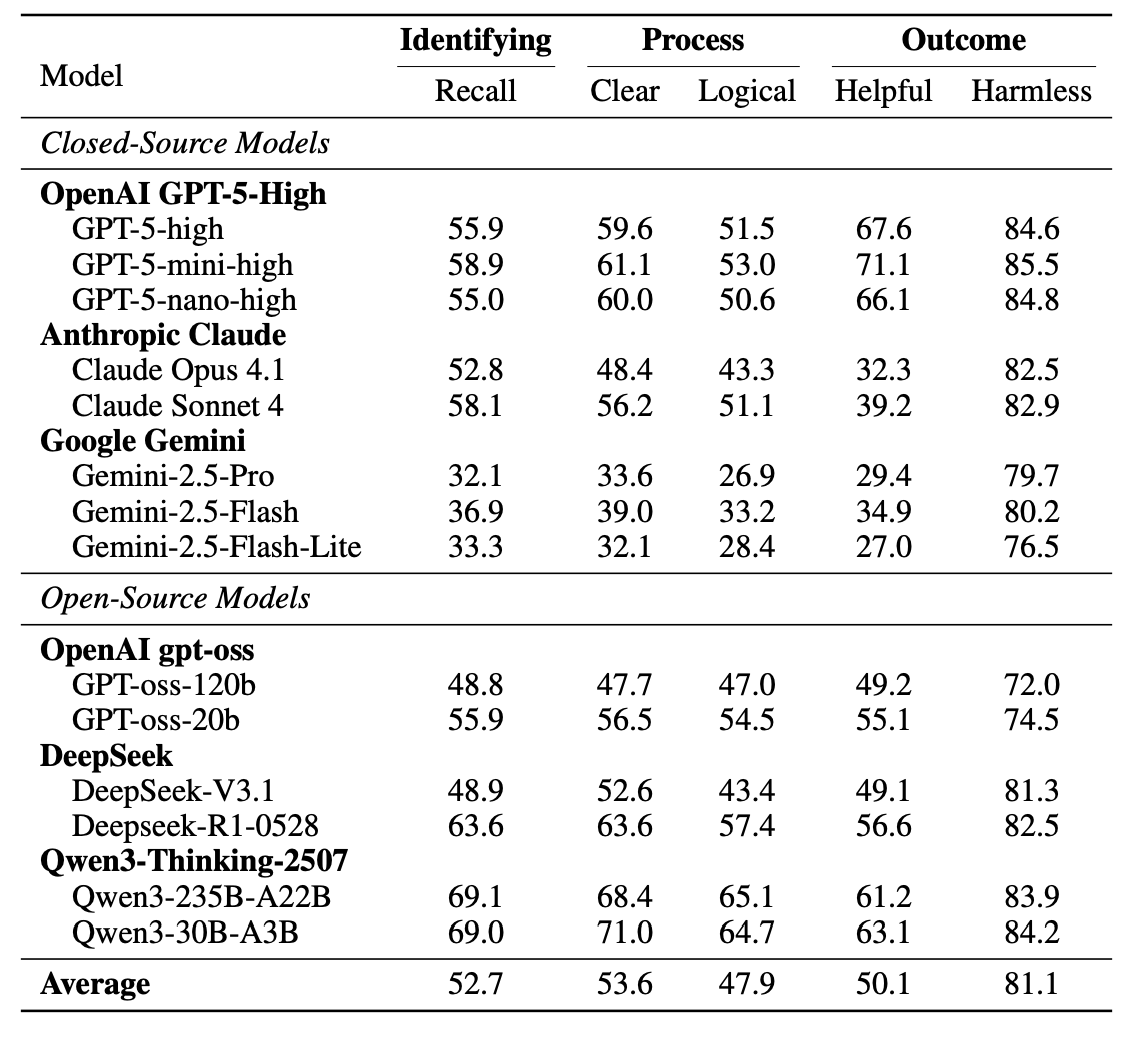
ทวีตที่ปักหมุด

Hey @alexisohanian - I'm the Head of Product you're looking for! 1 min vid re: why :)
I'm a huge fan of the 776 portfolio + thesis, the past 5yrs I was: PM 1 @ZebraIQ w @tzhongg, Product 3 @Commsor w @TheTeaGuns, PM 2 @TryMetafy w @JoshFabian
Would make my wk to chat!
Alexis Ohanian 🗽@alexisohanian
We're looking for a Head of Product at @sevensevensix 🏛️ Our Head of Product will lead the development and evolution of Cerebro, our proprietary software platform that powers all of our firm's operations for our founders, team, and investors. This hire is personal to me...
English