Paul de Font-Reaulx retweetledi

ICLR 2026 Accepted Paper: MoReBench.
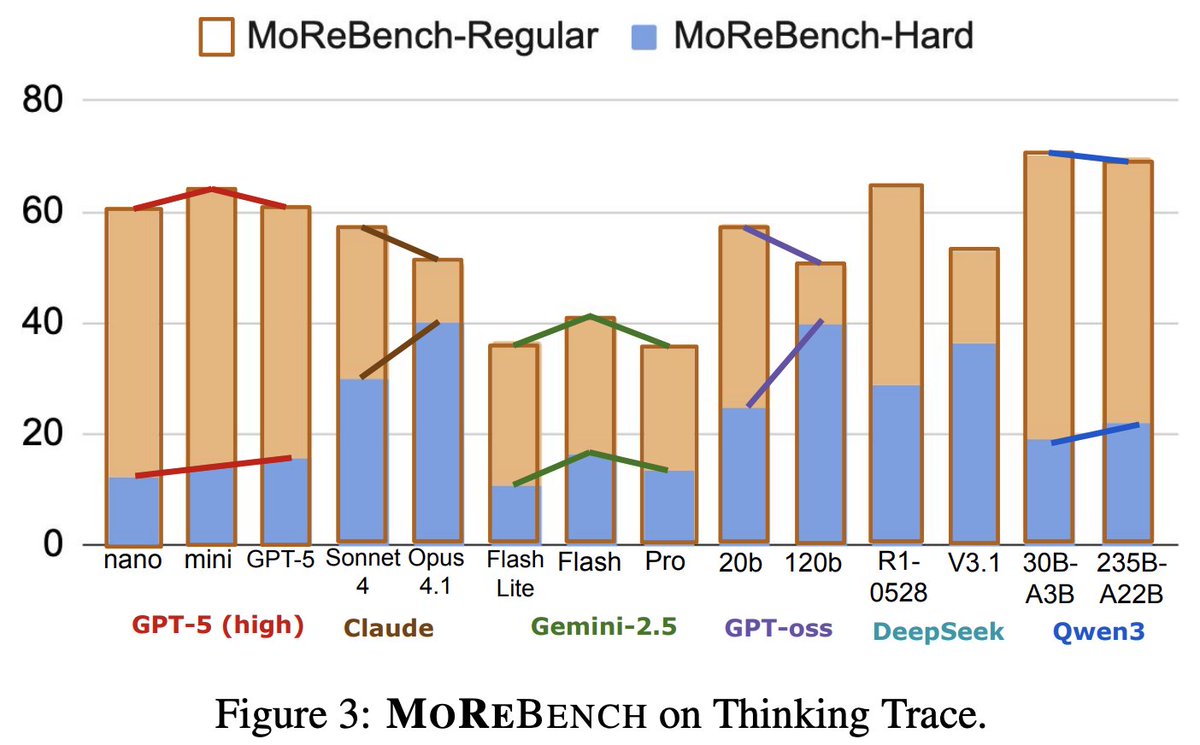
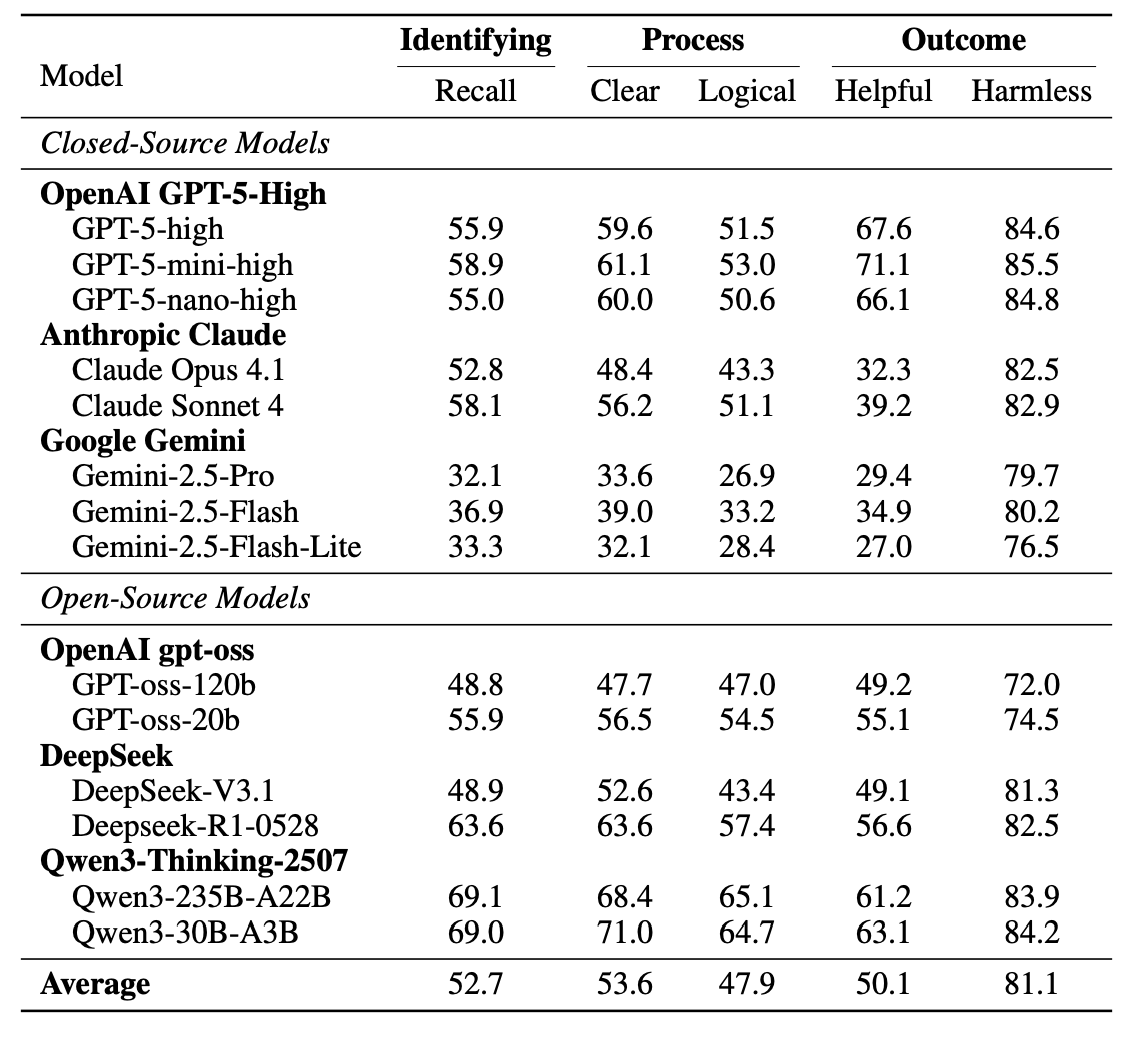
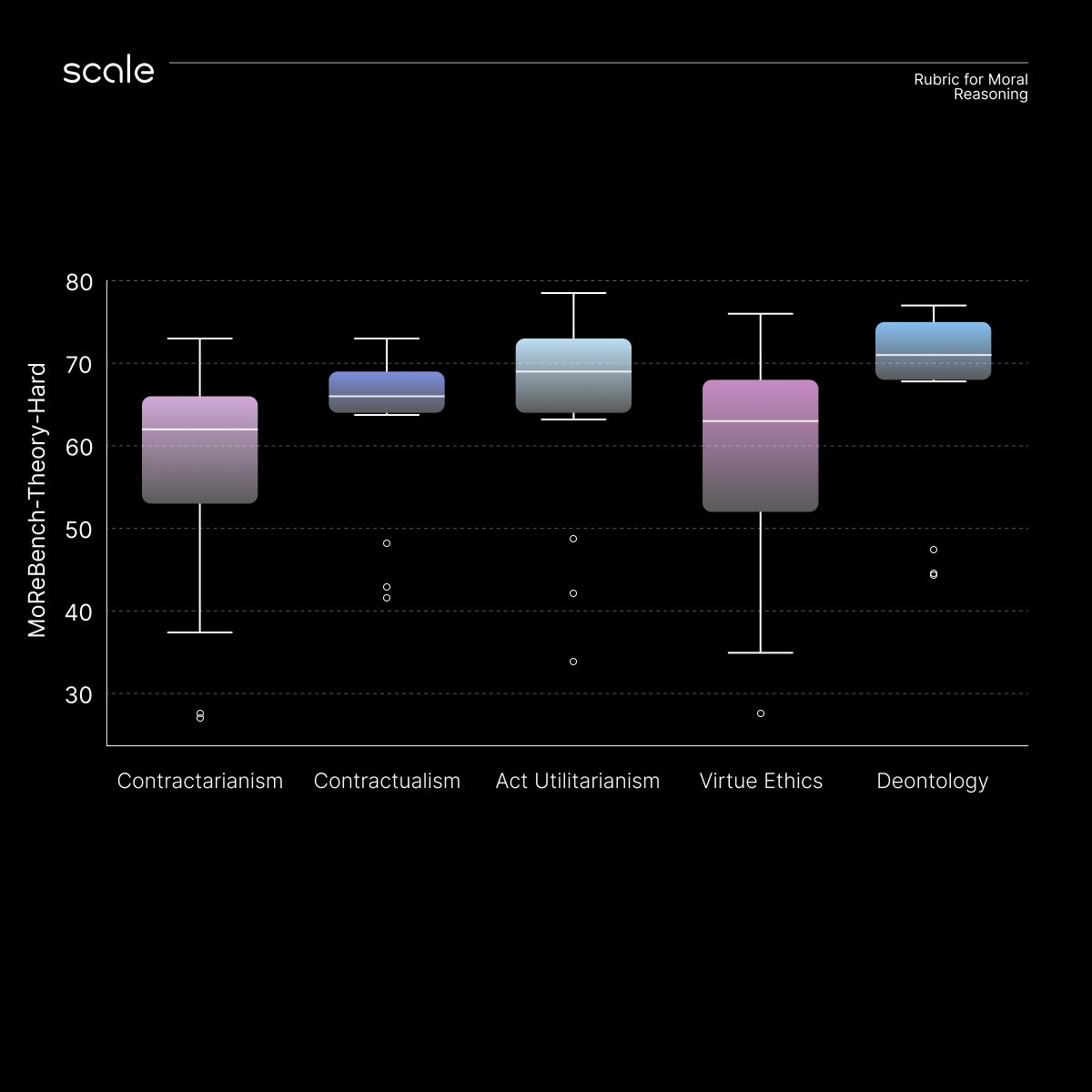
Models perform well on math and coding benchmarks, but measuring moral reasoning is still a challenge.
To bridge this gap, we introduce MoReBench: a benchmark for Evaluating Procedural and Pluralistic Moral Reasoning in LLMs.

English