@trikcode What? So if a team writes some software at a company. They quit and the company hires other devs, you telling me those devs can’t debug it because they didn’t write it? What an absurd claim.
English
QuantumCTO
1.7K posts

@dannywall92
CTO of OA Quantum Labs and avid currency/crypto trader.


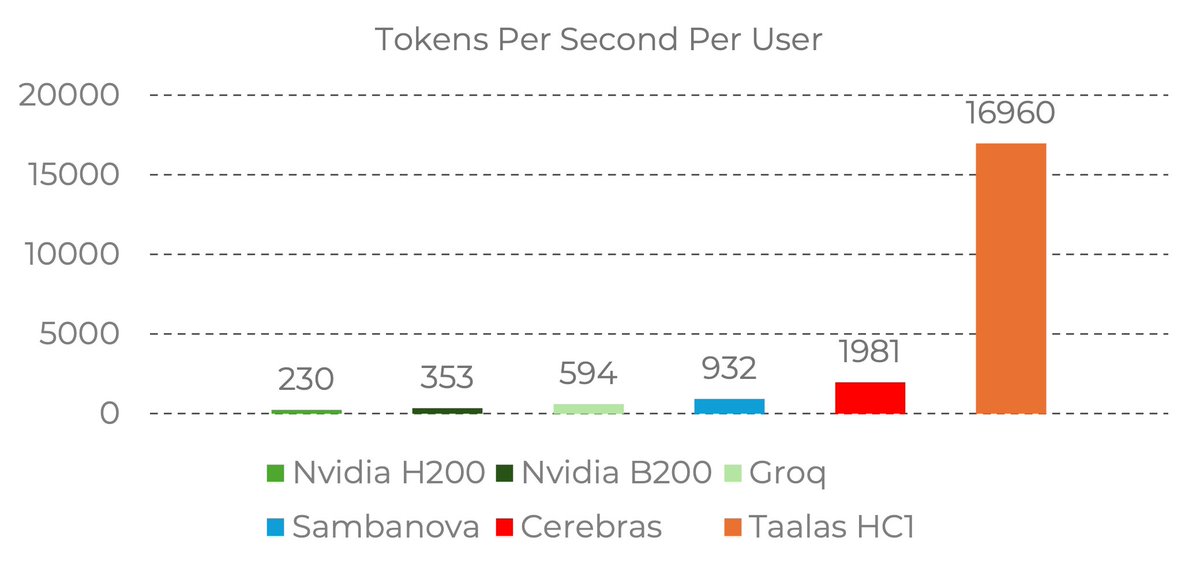
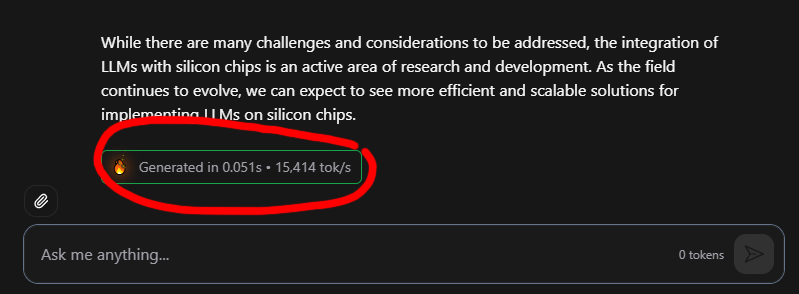
24 dedicated people. $30M spent on development. Extreme specialization, speed, and power efficiency. Today we launch Taalas’ first product. Check it out: Details: taalas.com/the-path-to-ub… Demo chatbot: chatjimmy.ai API: taalas.com/api-request-fo…






BREAKING: Netherlands’ House of Representatives has approved a 36% tax on unrealized capital gains.


One thing I noticed is that none of the "SaaS is dead" posters seem to ever identify which SaaS product is dead. I really find that amusing. There are so many SaaS products out there. If SaaS was truly dead, it would be trivial to name one or two that you think was now DOA.