
David Buxton
122 posts


GLM 5.2 has been my daily driver for a few days and the code quality is genuinely good. Bug spotting, complex refactors, multi-file changes. It is right there at the frontier.
But the thinking phase. My god.
Someone on Reddit called it "thinkslop" and that is the perfect word. The model burns through 5x more tokens than GPT-5.5 doing the same task. Not because the task is harder. Because it goes in circles.
Ok, let me do this. But wait, what about this. Actually, let me see. Wait, but then. Ok, now let me write this. Actually, nevermind.
It drafts entire code sections, throws them away, starts over. Considers edge cases that do not exist. Seems afraid of getting something wrong.
The theory is interesting. Open models might have a weaker internal evaluation function. So they compensate with brute-force searching. Like a chess engine with a worse position evaluator doing deeper tree search to keep up.
The pricing looks great on paper. $2 per million input tokens, $6 per million output. A fraction of what GPT-5.5 or Opus 4.8 cost. But if the model eats 5x tokens on thinking loops, those savings disappear pretty fast. Pay per token and you have to wonder what the real advantage is over just using GPT or Opus, which get to the same result in a fraction of the tokens.
The only way it works cost-wise is with a subscription like Umans, which currently offers unlimited tokens for $50 a month. Flat fee, does not matter how many tokens the model wastes on thinking loops. Otherwise the token bill from all that overthinking kills the price advantage.
There are mitigations. You can set a reasoning budget. Switch reasoning to low. Write better system prompts. It helps, but it feels like putting a band-aid on something structural.
The counterargument people keep making: closed models probably do the same thing, they just hide their chain of thought. The last frontier model that showed its thinking, Opus 4.6, rambled exactly the same way. We just cannot see what GPT-5.5 is doing behind the curtain.
Maybe. But if I am waiting 90 seconds for a response that should take 20, the lack of transparency does not help much.
What has your experience with GLM 5.2 been so far?
English
I agree that resolving a ticket decouples input cost and output value. I do not think that repackaging tokens as compute units does so. Obviously it does give you more discretion to slip margin in, but you’re fundamentally still using a cost yardstick, albeit one that’s more flexible in your favor.
Tomasz Tunguz@ttunguz
Sierra charges when an agent resolves a ticket, zero for failures. Devin sells Agent Compute Units, not tokens — the same abstraction Databricks & Snowflake use with credits to decouple pricing from raw compute. Margin is decoupled from the inference line. Durable.
English
@paulg It's amazing how human some of the old attempts to pass the Turing test are way better than the best LLMs in terms of non-boringness (even if they can get a little weird)

English

Another annoying thing about getting emails people have used AIs to write for them is that they're usually longer than they'd have written by themselves. Paragraphs and paragraphs of plausible-sounding text. Ugh.
English
I’ve been wondering if we need a new notation for AI.
Big-O describes how computation scales.
But what we’re seeing now is something different: how much agency we’re willing to hand over.
Call it Big-A.
A(1):
“Write this function.”
A(n):
“Execute this workflow.”
A(n²):
“Keep working until the tests pass.”
A(n³):
“Debate another model until you’re both happy with the result.”
A(n⁴):
“Build this product.”
A(∞?):
“Achieve this outcome.”
The point isn’t that these are mathematically correct.
The point is that every time AI gets cheaper, we don’t seem to do the same work for less money.
We move up a level of abstraction and ask for something bigger.
A prompt becomes a workflow.
A workflow becomes an agent.
An agent becomes a team.
A team becomes a project.
A project becomes an outcome.
Which makes me wonder whether Jevons Paradox has any natural limit in AI.
Do we eventually run out of higher-order loops to automate?
Or does Big-A just keep increasing forever?
English
@kakashiii111 free credits are a sugar high. they delay the moment you have to ask why the spend is what it is, they don't answer it. the teams that actually flatten the bill aren't the ones with the biggest credit line, they're the ones who can see and cap usage.
English

Any company concerned about AI cost should call Jensen. Nvidia has $30B worth of cloud credits across neoclouds and hyperscalers, and they'd be happy to share them with you, just don't cut the AI budget.
zerohedge@zerohedge
"We created a monster" companies rein in AI usage as costs strain budgets “Compute costs are now beginning to enter the minds of both CFOs and boards. Consumers and businesses have been taught that AI is cheap or free and that is definitely not the case,” said Costi Perricos, global generative AI leader at Deloitte. ... some companies have told workers to use open-source models that can be run locally on their own servers or personal devices, reducing the bill they pay to AI labs and cloud providers. ... customers are still weighing higher costs against the promises they have made to investors about AI’s impact on their own bottom line and workers’ productivity.
English
@dexhorthy "just build more loops" is the same instinct that shows up in the finance review as a 5-figure inference bill nobody can explain. the loop that doesn't read its own output burns tokens and trust at the same rate.
English

love you all, this is hard work, there's still tons of unknowns, I'm trying to help you speed run to the frontier here. rant:
i'm sorry but if people are tokenmaxxing bugs into production and taxing your senior engineers with kLOC PRs that they didn't read themselves, those people shouldn't have jobs
coaching juniors on SWE fundamentals is hard work and it takes time but if you're not supporting the people trying to coach them, or actively undermining them by telling the team to "just build more loops" or "let go of reading the code", not gonna end well
Deedy@deedydas
Most software engineers are facing an identity crisis bordering on depression. As CTOs aggressively evangelize tokenmaxxing, a class divide ensues. The lazy. The lazy push code. They don't write it. They don't manually test it. They don't even read it. They're on autopilot. See Jira ticket, prompt for task, submit code. Many of them are barely on their computer the whole day. A comment on the PR asking why they did this? The lazy ask AI. A Slack message? The lazy ask AI. Need to prepare for standup? The lazy ask AI. As long as it sounds enough like them and isn't detected. Some of the lazy are even overemployed, and work multiple jobs. The lazy smart ones get away with this, and even rewarded. After all, software engineering for the lazy is just a dance to convince your colleagues you're smart and hard working. The craftsmen. The craftsmen are tired. Very tired. 15 PRs in queue. Slack blowing up. The entire burden of review falls on the craftsman. The burden of understanding. They try. They work their way through the code, thoughtfully commenting to improve what ships. The response? A lazy: "That's a clever idea! You're absolutely right." with an incorrect change. It's fine, the craftsman says. I can fix them. They write a doc urging his colleagues to be better. The next day? 20,000 line PR to review. Day after day, their workload grows. Bugs seep into production. No one seems to care. Another round of AI is thrown at it. Their animosity to their colleagues rises. Eventually, they give up. It's just not what it used to be. The craft they loved is dead. They eventually wake up, a lazy. This isn't all companies. Many companies are genuinely more productive, adopt the right set of principles and practices around AI development and have highly talented teams that trust each other. It tends to happen in bigger companies that are 10+yrs old with a higher talent variance. But it happens. A lot.
English
@kimmonismus the tell is they're building an "AI Gateway to track spend and impose token budgets" in-house. every big co is quietly arriving at the same place: the cost problem was never the model price, it's that nobody could see or cap usage. a control problem wearing a procurement costume.
English

No more tokenmaxxing at Meta
Meta is preparing to curb internal AI usage after employee token consumption surged so sharply that the company now expects internal AI costs alone to reach billions of dollars in 2026 (looking at you Claude).
The move marks a sharp reversal from Meta’s earlier push to reward “AI-driven impact,” as the company now builds an AI Gateway to track spending, impose token budgets, and shift employees toward in-house tools like MetaCode.

English
@mattpocockuk For things like classification, summarization I don’t think it’s impossible for these to work but I also haven’t seen good results
English

The "X technique reduces tokens by Y%" fad is so old
Can't believe people get taken in by this
Charly Wargnier@DataChaz
UP TO 95% TOKEN REDUCTION WITH ZERO CODE CHANGES A Netflix engineer just open-sourced Headroom, and it’s one of the smartest ways I’ve seen to cut LLM costs. It wraps Cursor or Claude in a local proxy to compress your payload before it hits the LLM: → Intelligently shrinks logs, JSON, and code → Perfectly preserves logic accuracy → Keeps 100% of your data local → Stops Opus-tier models from wasting tokens on boilerplate It already crossed 35K stars, which says a lot. 100% free and open-source. repo in 🧵↓
English
@bscholl I love this framing. Imagine the user stories: “As an enemy fighter pilot, I want to get shot down, because…”
English

6/ In wartime, the enemy is the real customer of defense products—the enemy defines what is useful and war economics drive what costs are viable.
Defense products iterate on the battlefield with the enemy.
English
@emollick Yes, the value is what you do along the way rather than the end result. Whereas in coding if you just magically write the answer and it’s right, who cares what you did to get there
English

A fundamental problem with extending Codex/Cowork/Code to all knowledge work is that they remain very "software-brained" where the end result (the software) is what is important & that code serves as a source of truth.
For a lot of other knowledge work, the process is at least as important as the outcome. This includes researching what is known, an exploration of alternatives, failed efforts, prototype branches, experiments, etc. All of those things are valuable, so you cannot use the PowerPoint at the end the way you can use a codebase, nor is progress on a to-do list sufficient context post compaction. You work in learning loops, refining your perspectives as you go.
In some ways, this makes long-running models like Fable hard to use for deep knowledge work, since they are designed to deliver product to you in the end. You can prompt your way around this problem, but everything about the Codex and Code harnesses want you to be a software developer and you have to fight them. There is a real disconnect between how a manager or analyst thinks about problems and how the agentic software tools approach solving them. Addressing this is critical to breaking out of the coding niche for these tools.
English
A simulation environment is hard to build but game changing when it comes to ability to iterate
If you don’t have one, you’ll be constantly holding customers’ hands while they press the “on” button on agentic stuff
Curious, is anyone building a comprehensive harness for this as a standalone product?
English

@arshamg_ Dm me and I can show you how this is solved by harriethq.com
English

MCP solves 80% of this but sharing with your team/collaboration is unsolved. example:
we have a daily codex automation that combines all of Ribbon customer usage data with our Attio data to highlight any big movers
right now it runs out of my account- there is no good way to share this with the team. I can share the prompt/skill but the MCP connections are not portable and the automation relies on local files like a python script to match up customers
there’s a big problem to be solved here
Gergely Orosz@GergelyOrosz
One interesting trend: I’m seeing *so many* VC-funded, internally built infrastructure and bootstrapped solutions around “building a context layer for engineering teams.” Aka trying to solve the problem of “if only eg Claude Code had the context from all your other systems”
English
@scottastevenson Do-maxxing is a suboptimal choice when everything that can be done soon _will_ be done. The same thing done tomorrow will be half the price of doing it today.
It is the era of wait-maxxing
English

learn-maxxing is a bad bet when the world is changing so quickly. The expiry date on knowledge is just around the corner.
It is the era of do-maxxing
English

@paulg Do you know anyone doing the smart compiler? Feels like it might just be tractable with Fable+ quality coding agents
English
I haven't read this for about 10 years, but I just looked at it after someone linked to it and I was surprised how many of these things are starting to happen. Still no next Steve Jobs yet though.
paulgraham.com/ambitious.html
English
@petergyang You are being massively subsidized. Long may it last. But at some point there will be a rug pull
English

I will go against the grain and say I can barely use up my Codex and Claude $200 subscriptions so I don’t see the point of trying local models…
Also to try the latest glm locally requires 512 mb which is like a $10K Max Studio?
English
@theo This is very task dependent. There are a lot of simple tasks - especially non-programming - that GLM will burn similar numbers of tokens on and hence be way cheaper.
English

I see a lot of people hyped about GLM-5.2. Rightfully so! Having an open weight model surpass GPT-5.4 and every Gemini model is dope.
That said - it's not cheap. Both Opus 4.8 and GPT-5.5 set to "medium" are cheaper and smarter than GLM-5.2
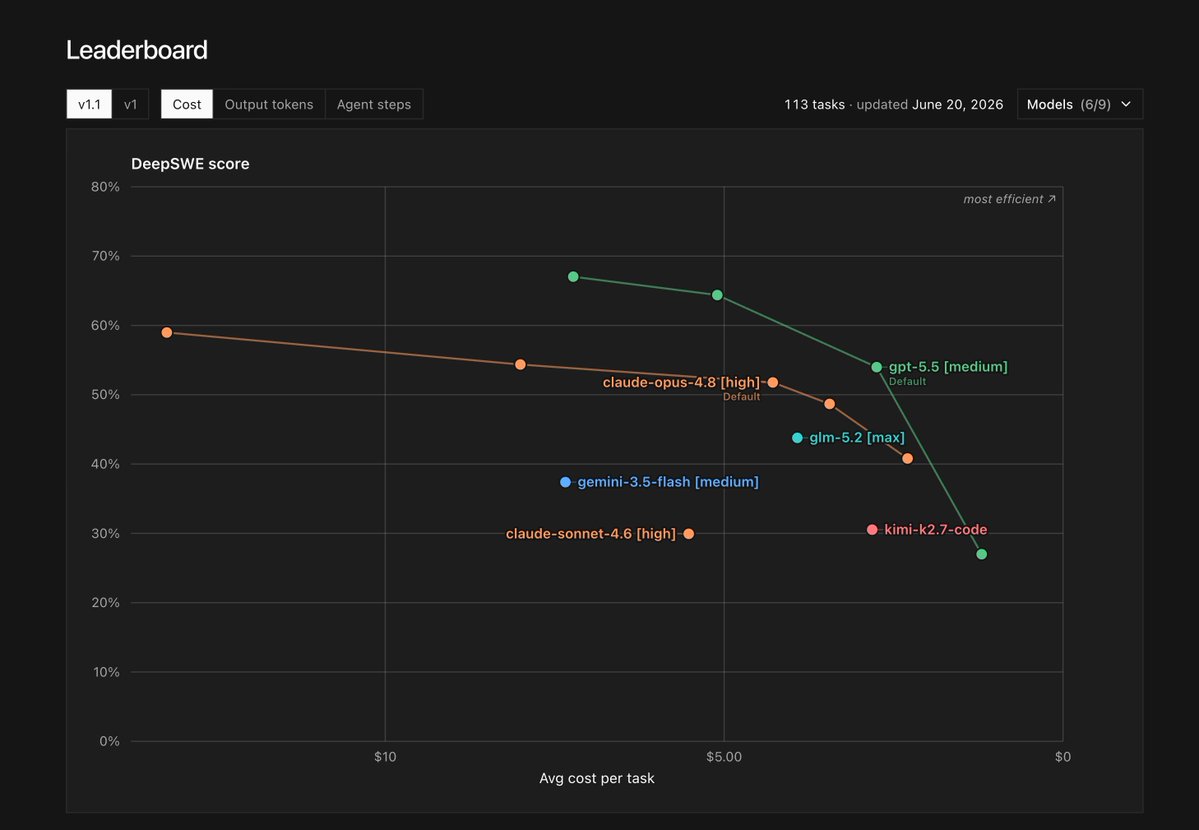
English
@EXM7777 I think for short horizon loops it’s really great.
Not quite there for long-horizon /goal type usage but honestly nothing is perfect yet; Fable is closest that we have come yet
English

Strongly agree on latency. I’m so bored of waiting for Claude
Zach Lloyd@zachlloydtweets
I've been using both GLM 5.2 and kimi 2.7 code in @warpdotdev and both are very good quality. Not quite frontier imo, but you can get a ton of good building done with them. The thing that stands out though is that 1) you get 10-20x further with them for the same price compared to the frontier lab models 2) they are like 3x faster for me Having used GPT 5.5 and Opus 4.8 regularly I was surprised by how much I actually cared about the latency difference in addition to the obvious cost savings. Highly suggest folks try them
English