@xpuente@KordingLab Nevertheless, a more complicated model of RL in the brain probably needs to train some kind of policy network as one component. And for that having access to an error gradient is very beneficial, especially if the action space is continuous.
@xpuente@KordingLab In our Discussion, we point at some ideas of how that gradient might appear, but realistically I think that would require a much more complete model of the whole brain - perhaps also including hippocampus for e.g. off-policy learning with some smart sampling strategy.
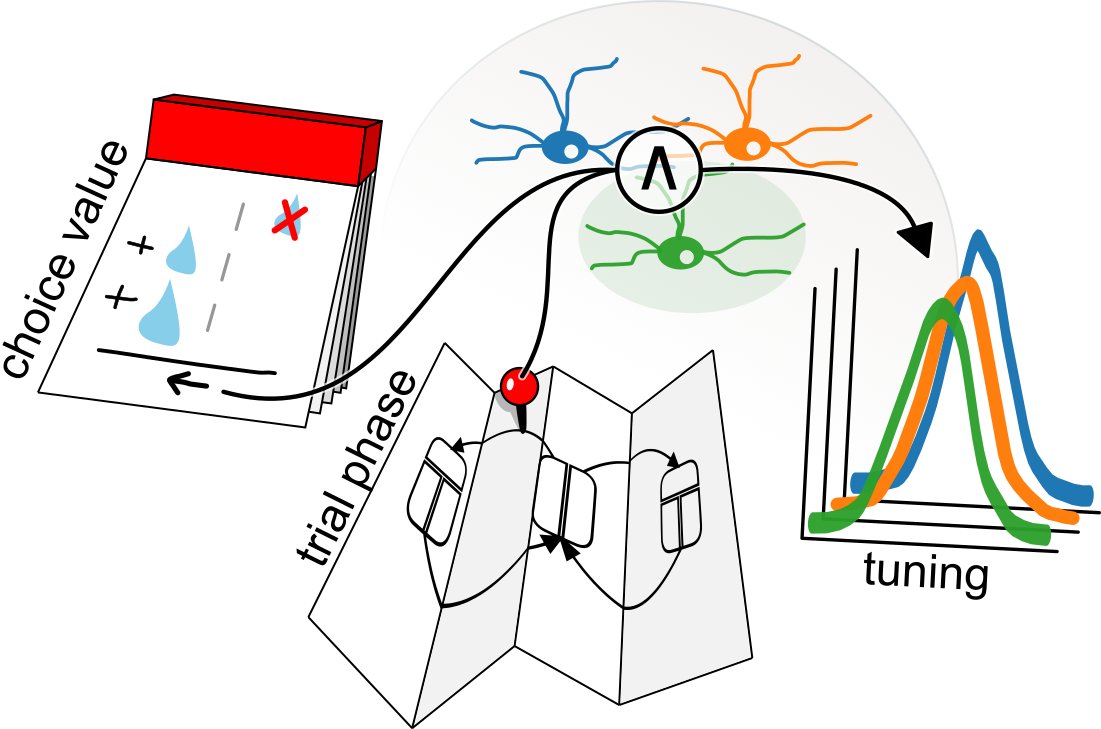
@wegmor@Inscopix In summary, all three striatal pathways independently broadcast a similar, complete representation of the different levels of the task (choice value, trial phase) to downstream targets. This representation looks more like RL state, than actor or critic [8/9]
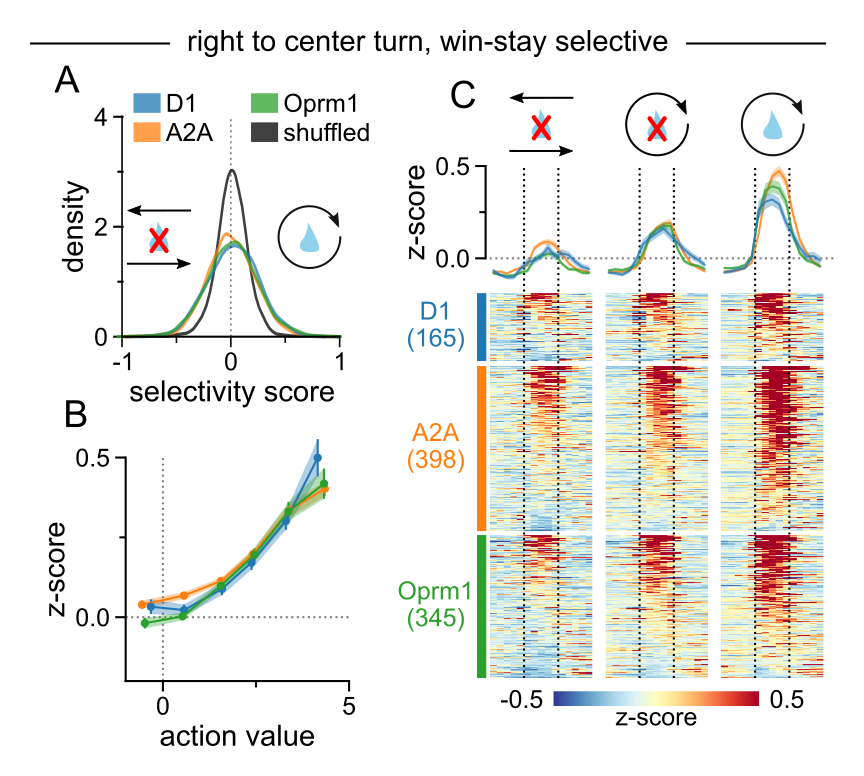
@emil_warnberg@Inscopix Trial progression: ✓. But can we decode win/switch strategy? Focusing on the right to center port turn, we indeed found neurons selective for win-stay vs lose-switch trials. Moreover, these neurons did not simply encode strategy; their activity increased with choice value. [7/9]
In our new bioRxiv preprint, we used @Inscopix miniscopes to calcium-image neurons of 3 striatal output pathways (matrix direct/D1, matrix indirect/A2A and striosome/Oprm1) in mice making decisions. Hypothesis: the matrix serves as RL-actor and the striosome as critic. [1/9]
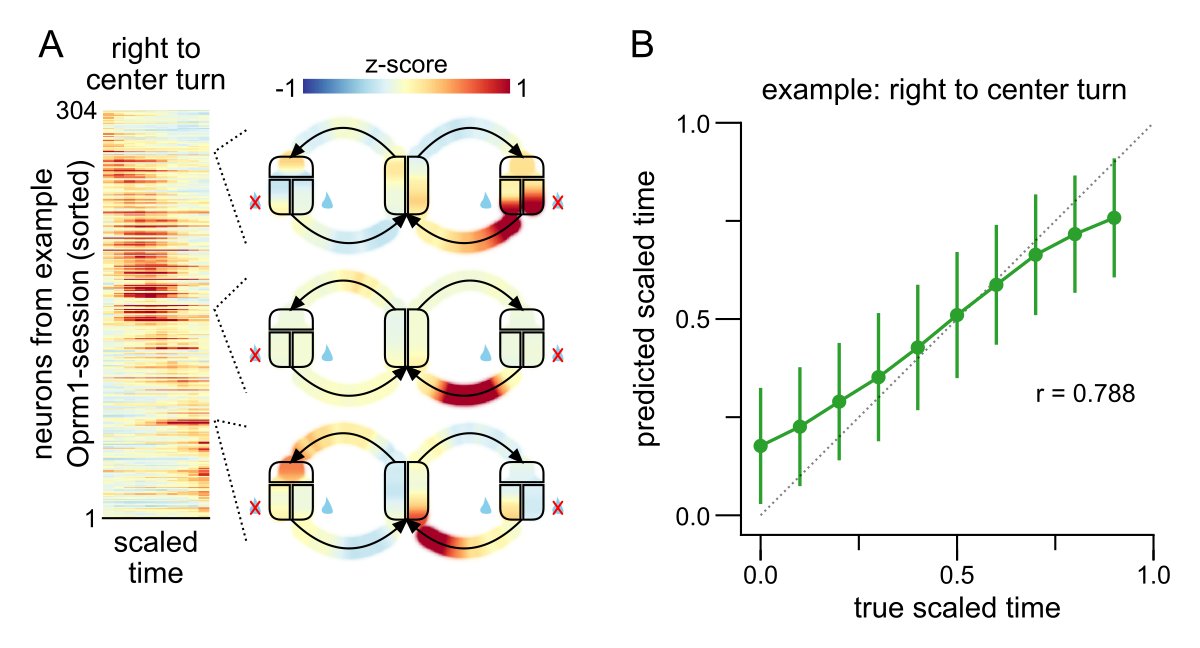
@wegmor@Inscopix Our division of the task into 12 discrete phases was somewhat arbitrary. Could we have chosen a finer division? Turns out the answer is yes: we can accurately decode the animals’ progression through individual phases (example: right to center port turn). [6/9]
@emil_warnberg@Inscopix The neurons kept their tunings across days and weeks. In fact, tunings were stable enough to support accurate, trial-by-trial decoding of the trial phase across days. [5/9]
@wegmor@Inscopix Let’s unpack that a bit. Here’s a video of three Oprm1-neurons during the task: the red one fires in the center to right port turn; the purple one fires in the center port prior to left choices; the cyan one when getting a reward from the left port. [3/9]
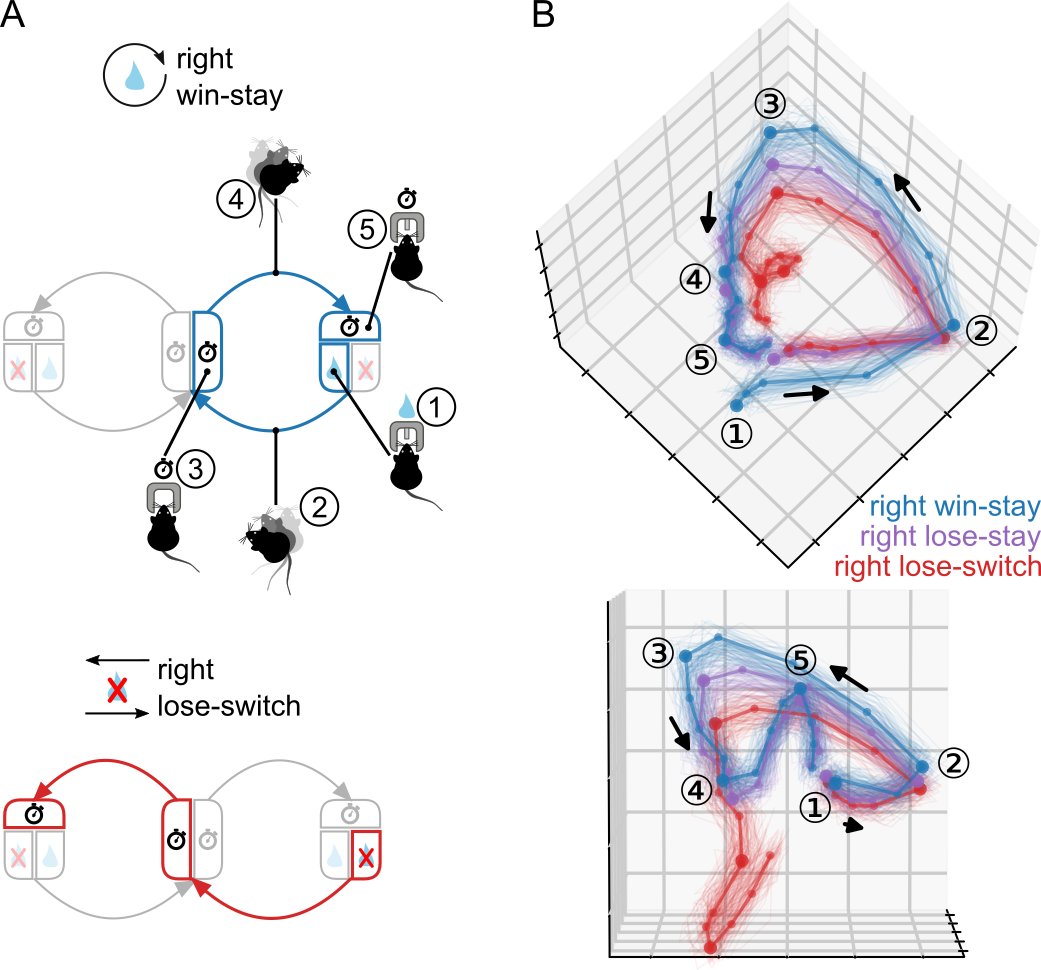
@wegmor@Inscopix Choice port outcomes were occasionally swapped covertly (75% vs 0% reward). In response, mice adapted a win-stay (blue), lose-switch strategy (red). In short, the striatal activity reflected both the mice’s progression through trials and their win/switch strategy. [2/9]
Determining what matters and does not is more complicated than accepting binary “statistical” significance. I signed on to this @nature paper, with 800+ other scientists, which eloquently urges we stop talking about statistical significance: go.nature.com/2TkvLDN@societyforepi