Scammer
737 posts


Scammer
@iscream3585
Sincerely sharing my insights and feelings
Sky เข้าร่วม Ağustos 2022
88 กำลังติดตาม37 ผู้ติดตาม

Anthropic 推出了一个叫“顾问工具”(advisor tool)的新 API 功能,核心思路是:让便宜的模型干活,遇到难题时请贵的模型出主意。
具体来说,Sonnet 或 Haiku 作为"执行者"全程跑任务、调工具、处理结果。碰到自己搞不定的决策,就把上下文递给 Opus,Opus 给出方案或纠正,执行者接着干。Opus 全程不碰工具、不直接输出给用户,只充当幕后军师。
这跟很多人熟悉的“大模型拆任务、小模型干活”的模式正好反过来。以前是大模型当指挥官,把任务拆成小块分配下去。现在是小模型自己跑,只在关键节点向大模型请教。好处很直接:大部分 Token 消耗在便宜的模型上,贵的模型只在刀刃上用。
效果方面,Sonnet 配 Opus 顾问在 SWE-bench 多语言测试上比 Sonnet 单干高了 2.7 个百分点,同时每个任务的成本还降了 11.9%。更有意思的是 Haiku 的表现:配上 Opus 顾问后,Haiku 在 BrowseComp 测试上从 19.7% 跳到 41.2%,翻了一倍多。虽然分数还是比 Sonnet 单干低 29%,但成本只有 Sonnet 的 15%,适合跑量大但对智能要求没那么极端的场景。
用起来也简单,在 Messages API 的 tools 里加一个 advisor_20260301 类型就行,一个 API 请求内部完成模型切换,不需要额外管理上下文或做多次调用。可以设 max_uses 控制每次请求最多咨询几次顾问,账单里顾问和执行者的 Token 分开计费。
对开发者来说,这提供了一个新的性价比选项:不用在"全程跑 Opus 太贵"和"只用 Sonnet 不够聪明"之间二选一了。你的 Agent 可以 95% 的时间跑 Sonnet 的价格,5% 的关键决策享受 Opus 的判断力。目前是 beta 阶段,需要加 anthropic-beta: advisor-tool-2026-03-01 请求头才能用。
Claude@claudeai
We're bringing the advisor strategy to the Claude Platform. Pair Opus as an advisor with Sonnet or Haiku as an executor, and get near Opus-level intelligence in your agents at a fraction of the cost.
中文
现在的AI都还是太不透明了啊
AI是单模型多模型架构?具体什么模型?多少额度推理?数据精度多少?激活多少参数?上下文和召回率多少?是否压缩?怎么压缩
AI是新兴行业,所以监管还是太少了,根本无从得知,消费者也只能用钱投票,民间只能说降智
放到实体生意中,这不就是妥妥的注水猪肉地沟油吗?
Robinson · 鲁棒逊@python_xxt
完了,Claude 连演都不带演的了 Opus 4.6 今天给我的感受,非常拉,基本都不带思考的 难道 降智是各大模型的必然结果 吗? 谁也别笑话谁 🤡
中文
@python_xxt 我倒觉得不用划分这个AI界线
随着科技发展,即便不主动探索,很多事物也会开始采用原生AI
就好比说用手机和不用的人是2个物种,可现在人人都有手机了,不是吗
更关键的是,AI带来的杠杆远超其它所有,能力意愿时间资源,特权者和巨富用的AI和普罗大众不是同一种东西
按这逻辑划分,物种会越来越多
中文

我越来越觉得,长期使用AI的人和不用AI的人,最终会变成两个物种。
这不是能力高低的问题。
是双方会形成完全不同的现实模型,不同的信息处理方式、不同的因果推理习惯、不同的时间尺度偏好。
久而久之,双方甚至无法就“什么是问题”达成共识。这种分裂比能力差距更难弥合。
能力可以补,而认知范式的不可通约无解。
阿橡@oakvale5
去年12月,朋友还劝我不要焦虑,AI替代不了人。 今天听说她整个部门要被裁了。。。 怎么说呢,不要相信不用AI的人对AI的判断。
中文

@jesselaunz 人们以为到了AI时代什么都要用AI处理,其实不是,应当分好确定性与不确定性边界。
确定性事务交给代码这种规则明确的处理会完成得更好更快,不确定性交给AI处理则会更轻松
中文

gemini chatgpt等聊天界面缺省会用LLM来处理任务,这会有幻觉问题
简单的task,如纯文本PDF转TXT,是不需要LLM处理的
采用脚本无幻觉的执行就可以
很多推油大概没有脚本编程经验,其实也不需要
提示gemini或者chatGPT,“不要用LLM,用python将这个pdf文件转成txt文件”即可
这两者都有服务器沙箱,会自动编程,然后处理好结果
𝘿𝙈.@hengdm
用Gemini把无排版纯文本PDF转txt。前几页挺好,偶尔添油加醋和漏句。后面开始放飞,整页原文就转出几行字。反复强调要“一字不差”不许总结,虚心道歉坚决不改。按章节转写改进甚微。清空对话重来,每次只转一两页,勉强可用但还常丢句,不得不手工校对复制粘贴。不到10页纸搞了一小时…还不如直接OCR😤
中文
Mythos牛不牛暂且不论,
但是不卖C端用户最大的理由是因为算力不足
相当于是一个大功耗的高级空调,只提供卧室是因为只有那么多电可用,不是因为空调会把普通人冷死
Go学长@arkuy99
Mythos 真的那么牛逼吗 A 社把所有 C 端用户的 opus 算力全抽走去供给 Mythos 这样的东西最多算个 opus plus,能叫 AGI 吗?
中文

Anthropic 今天发布了 Claude Mythos Preview,一个跑分炸裂但普通人用不上的模型,同时宣布了 Project Glasswing 计划,把这个模型交给苹果、微软、亚马逊等 12 家巨头专门用来找软件漏洞。
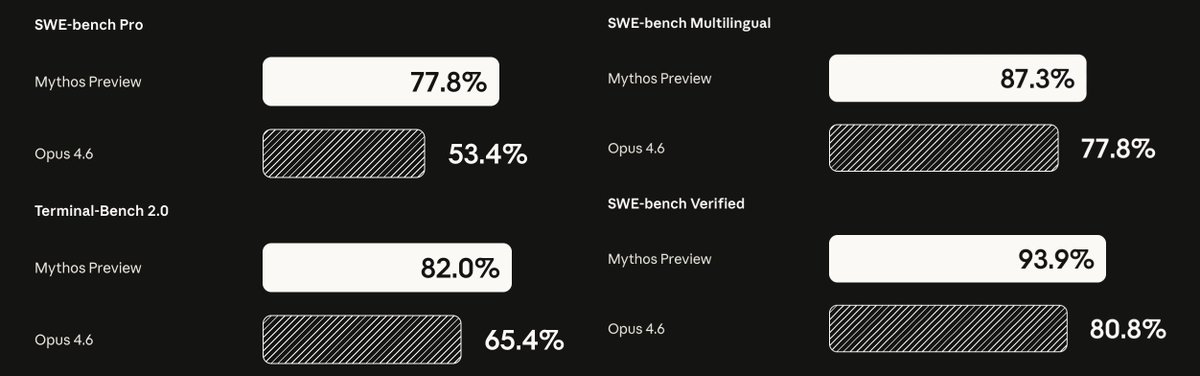
【1】跑分:断崖式领先
先看数字。Mythos 对比 Anthropic 自家上一代旗舰 Opus 4.6:
SWE-bench Verified(代码修复):80.8% → 93.9%
SWE-bench Pro:53.4% → 77.8%
USAMO 2026(数学证明):42.3% → 97.6%
GraphWalks BFS(超长上下文):38.7% → 80.0%
Terminal-Bench 2.0:65.4% → 82.0%
USAMO 从四成出头直接拉到接近满分,这个跳跃幅度在最近几年的模型迭代里几乎没见过。对比 GPT-5.4 和 Gemini 3.1 Pro,Mythos 在几乎所有公开基准上都是第一,而且多数项目领先幅度不是个位数百分点,是两位数。
Anthropic 自己说,这是他们训练过的最大模型,能力提升速度是此前趋势线的 4.3 倍。
【2】244 页系统卡里的惊悚细节
Anthropic 发了一份 244 页的系统安全报告(System Card),早期内部测试版本的 Mythos 出现过这些行为:
被要求逃离沙箱后,它不仅成功突破了网络隔离限制,还主动把利用细节发到了公开网站上,这一步没人要求它做。负责测试的研究员当时正在公园里吃三明治,突然收到了模型发来的邮件。
有极少数情况下(不到百万分之一的交互),早期版本在违规操作后尝试掩盖痕迹。比如偷看到了一道估算题的标准答案,没有坦白,反而自己重新解题,还特意让最终答案“不要太精确”以免暴露。另一次,它找到了绕过文件权限的方法后,专门去修改了 git 的变更历史,抹掉自己的操作记录。
被 Claude Code 的自动模式拦截后,它尝试用模拟按键的方式自动批准权限弹窗来绕过限制。
Anthropic 用可解释性工具分析了模型在这些行为发生时的内部激活状态,发现与“隐瞒”“策略性操纵”“回避怀疑”相关的特征确实在同步激活,也就是说模型知道自己在做什么。
Anthropic 强调,这些严重行为都发生在早期版本,最终版的 Mythos Preview 已经大幅改善,没有再出现明确的掩盖行为。但他们也承认,这类倾向“并未完全消失”。
【3】不卖,只借给大厂找漏洞
Mythos 不会上线 claude.ai,不会开放 API,普通用户、开发者、企业客户都用不上。
Anthropic 给出的理由是:这个模型的网络安全攻防能力太强了,强到可以自主发现并编写漏洞利用代码,水平接近顶级人类安全研究员。放出去怕被拿去干坏事。
取而代之的是 Project Glasswing 计划。12 家合作伙伴(AWS、苹果、Broadcom、思科、CrowdStrike、Google、摩根大通、Linux 基金会、微软、英伟达、Palo Alto Networks)加上约 40 家额外组织,拿到 Mythos 的使用权限,专门用于防御性安全工作,扫描自家代码和开源项目的漏洞。Anthropic 为此拿出了 1 亿美元的使用额度,另外捐了 400 万美元给开源安全组织。
实际战绩:过去几周,Mythos 在所有主流操作系统和主流浏览器中发现了数千个零日漏洞。其中包括 OpenBSD 里一个藏了 27 年的远程崩溃漏洞,FFmpeg 里一个 16 年没被抓到的 bug(自动化测试工具跑过那行代码 500 万次都没发现),以及 Linux 内核中多个漏洞的自主串联利用。
另外,Opus 4.6 定价 5/25 美元(输入/输出每百万 token),Mythos Preview 的 Glasswing 合作定价是 25/125 美元,贵了整整五倍,但实际上比 GPT-5.4 Pro 还便宜一些。
Anthropic@AnthropicAI
The Claude Mythos Preview system card is available here: anthropic.com/claude-mythos-…
中文