
Shuang Fu
116 posts
Shuang Fu
@judefffff
Interested in SMLM/computing SR technique | PostDoc in LiLab @YimingLi_SZ, SUSTech
เข้าร่วม Mayıs 2022
129 กำลังติดตาม20 ผู้ติดตาม

We introduce mirror-enhanced 4Pi-SMLM (me4Pi-SMLM), a streamlined single-objective configuration that leverages mirror-based retroreflection of the illumination beam to achieve near-isotropic localization precision of 2–3 nm, resolving diverse ultrastructural features.
Nature Biotechnology@NatureBiotech
Mirror-enhanced 4Pi-SMLM with one objective enables isotropic nanoscale imaging go.nature.com/3Ocpn3N
English
Shuang Fu รีทวีตแล้ว

🚨BREAKING: OpenAI published a paper proving that ChatGPT will always make things up.
Not sometimes. Not until the next update. Always. They proved it with math.
Even with perfect training data and unlimited computing power, AI models will still confidently tell you things that are completely false. This isn't a bug they're working on. It's baked into how these systems work at a fundamental level.
And their own numbers are brutal. OpenAI's o1 reasoning model hallucinates 16% of the time. Their newer o3 model? 33%. Their newest o4-mini? 48%. Nearly half of what their most recent model tells you could be fabricated. The "smarter" models are actually getting worse at telling the truth.
Here's why it can't be fixed. Language models work by predicting the next word based on probability. When they hit something uncertain, they don't pause. They don't flag it. They guess. And they guess with complete confidence, because that's exactly what they were trained to do.
The researchers looked at the 10 biggest AI benchmarks used to measure how good these models are. 9 out of 10 give the same score for saying "I don't know" as for giving a completely wrong answer: zero points. The entire testing system literally punishes honesty and rewards guessing.
So the AI learned the optimal strategy: always guess. Never admit uncertainty. Sound confident even when you're making it up.
OpenAI's proposed fix? Have ChatGPT say "I don't know" when it's unsure. Their own math shows this would mean roughly 30% of your questions get no answer. Imagine asking ChatGPT something three times out of ten and getting "I'm not confident enough to respond." Users would leave overnight. So the fix exists, but it would kill the product.
This isn't just OpenAI's problem. DeepMind and Tsinghua University independently reached the same conclusion. Three of the world's top AI labs, working separately, all agree: this is permanent.
Every time ChatGPT gives you an answer, ask yourself: is this real, or is it just a confident guess?

English
Shuang Fu รีทวีตแล้ว
Happy to share our latest work, 4Pi-SIMFLUX, which combines structured illumination with interferometric detection to achieve near-isotropic 3D localization precision of 2–3 nm and resolve sub-10 nm structural features in cells. nature.com/articles/s4159…
rdcu.be/eQVxt
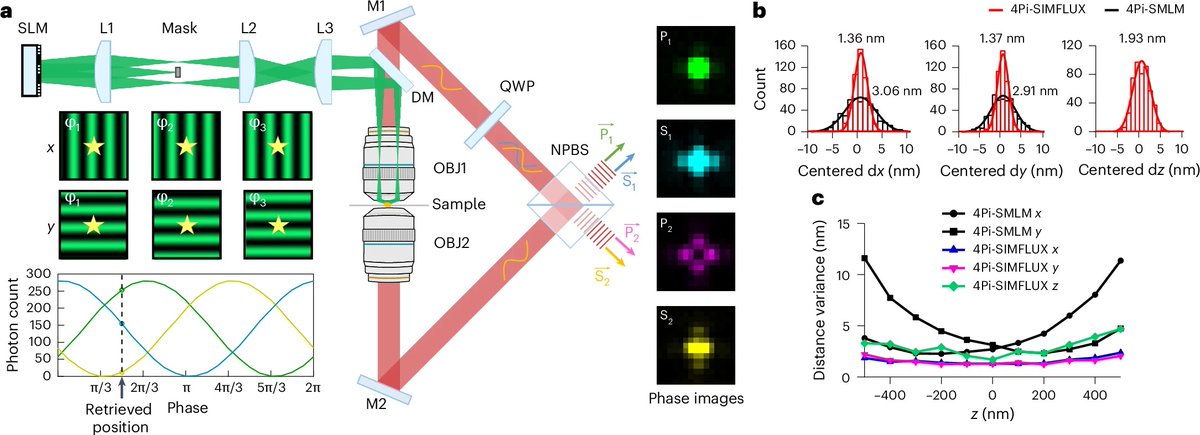

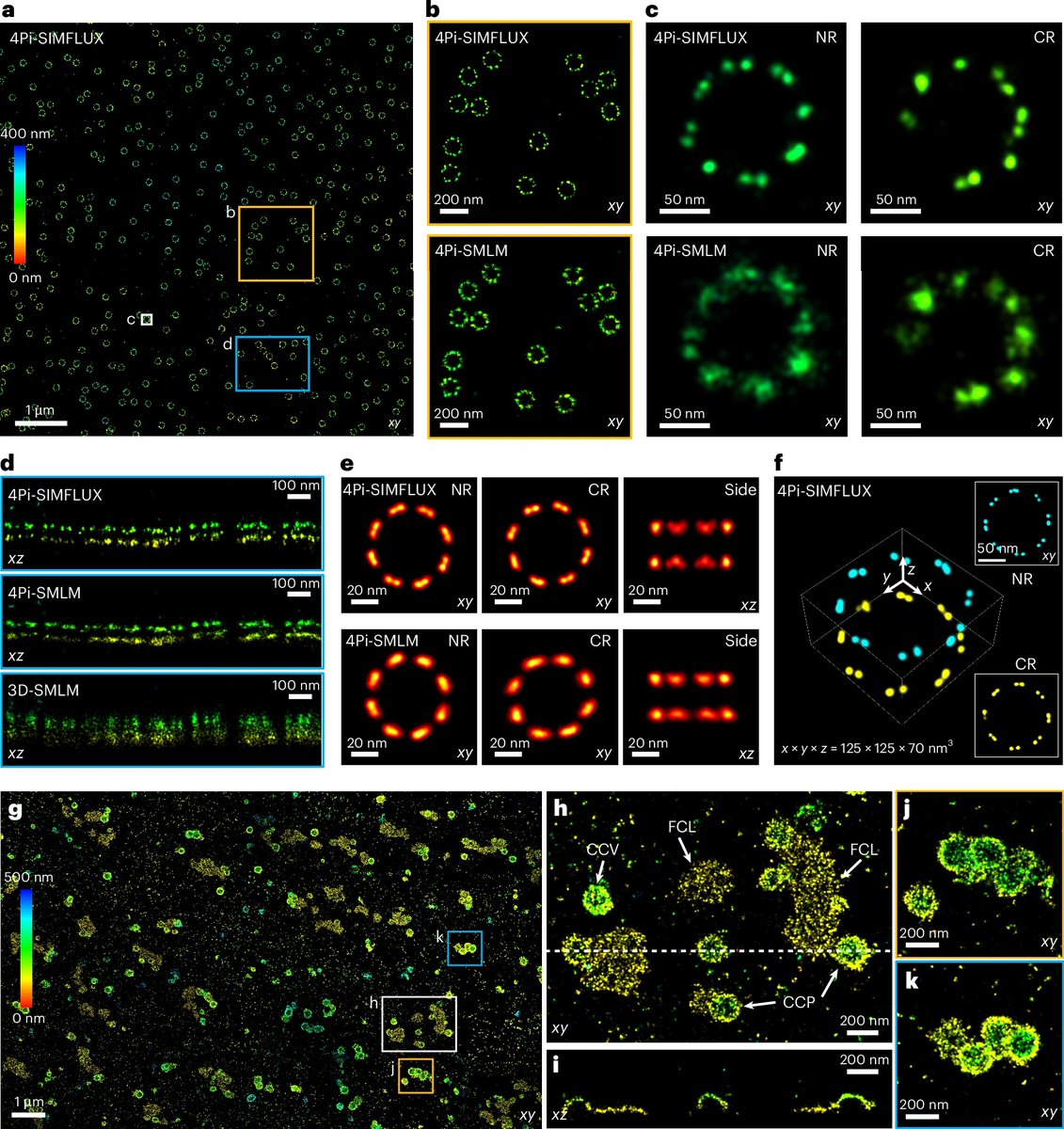
English
Shuang Fu รีทวีตแล้ว

We’re excited to share LiteLoc — a lightweight and scalable deep learning framework for high-throughput single-molecule localization microscopy, enabling analysis speed of >500 MB/s on 8× RTX 4090 GPUs without compromising accuracy. rdcu.be/eztp6
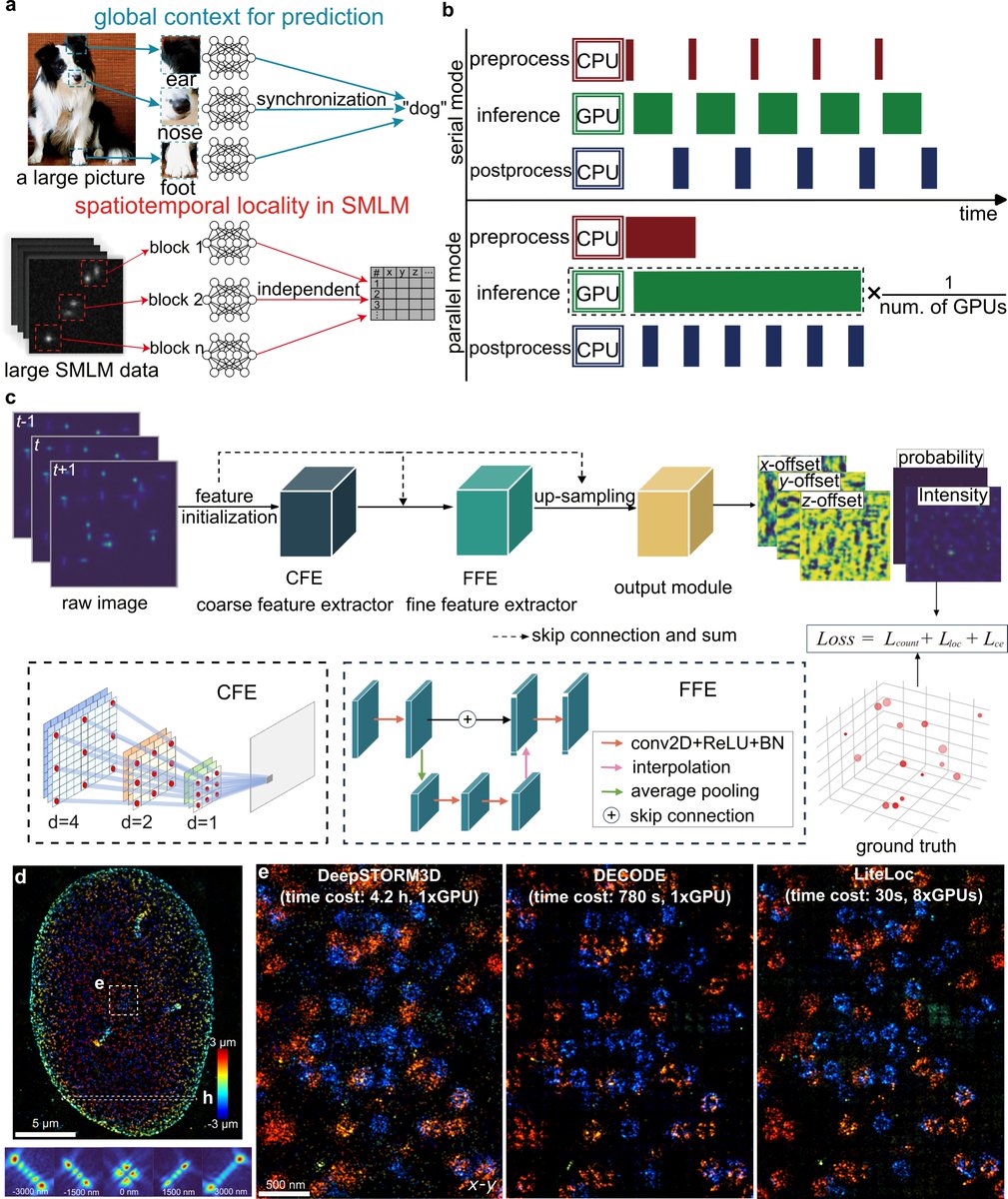
English
Shuang Fu รีทวีตแล้ว

Really excited to share this Perspective from John Danial covering how technology is moving the field of fluorescence microscopy toward structural biology. nature.com/articles/s4159…
English
Shuang Fu รีทวีตแล้ว

...and gradient descent is Bayesian inference:
jmlr.org/papers/v24/22-…
Kording Lab 🦖@KordingLab
After many papers, finally wrote out why I believe the brain to do gradient descent as a blog post: @kording/why-i-believe-that-the-brain-does-something-like-gradient-descent-27611c491205" target="_blank" rel="nofollow noopener">medium.com/@kording/why-i…
English
This is perfectly compatible with LUNAR, which leverages temporal context up to 9 frames to achieve ultra-high localization precision. Imagine the possibilities of large-DOF in situ multicolor 3D reconstructions!
Massive Photonics@massphoton
🎊Fantastic work!!! This pre-print by @LE_Laurent_ @S_LevequeFort et. al introduces Brightness Demixing for simultaneous 3-target imaging using 1 laser🤯 📷 Our #DNAPAINT ready 2ry antibodies & imagers were used for vimentin, clathrin,& tubulin imaging biorxiv.org/content/10.110…
English
Shuang Fu รีทวีตแล้ว

If you're at #AAAI2025, try to catch Cornell PhD student @yingheng_wang, who just presented a poster on Diffusion Variational Inference.
The main idea is to use a diffusion model as a flexible variational posterior in variational inference (e.g., as the q(z|x) in a VAE) [1/3]

English
Shuang Fu รีทวีตแล้ว

Optical nanoscopy, but without the OFF...!
Published in @NaturePhysics by T.A. Hensel, J.O. Wirth, O.L. Schwarz & S.W. Hell.
Check it out with open access at
nature.com/articles/s4156…
@mpi_nat @mpi_mr_hd #Imaging #Optics #Waves #Microscopy
English
My first postdoc project! Combining neural networks & physics for self-supervised localization was a wild ride. Grateful for the journey and the team!
Yiming Li@YimingLi_SZ
Excited to share LUNAR (Localization Using Neural-physics Adaptive Reconstruction) —a self-supervised, blind localization method that combines neural networks & physics to estimate aberrations from overlapped blinking molecules for large DOF imaging. Great work @judefffff !
English
Shuang Fu รีทวีตแล้ว

The Laplacian pyramid is the ancestor of the wavelet transform. Defines a compact multiscale representation by iterative lowpass/highpass filterings. en.wikipedia.org/wiki/Pyramid_(…

English
Shuang Fu รีทวีตแล้ว
Introducing Interactive Cell Biology, a complete course solution—no textbook needed. In partnership with @MacmillanLearn, delivered through Achieve. Check it out today! Visit: macmillanlearning.com/college/us/pre… to learn more. #cell #biology #education #animation
English
Shuang Fu รีทวีตแล้ว

MIT's "Street Fighting Mathematics"
This course teaches the art of guessing results and solving problems without doing a proof or an exact calculation.
Book: ocw.mit.edu/courses/18-098…

English
Shuang Fu รีทวีตแล้ว

Microscopy Nodes: versatile 3D microscopy visualization with Blender
Oane Gros, Chandni Bhickta, Granita Lokaj, Yannick Schwab, Simone Köhler and Niccolò Banterle
biorxiv.org/content/early/…

Română
Shuang Fu รีทวีตแล้ว

Maybe the most amazing microscope paper of the year just dropped: Live 4pi-SIM (a.k.a I5S*):
nature.com/articles/s4159…
Having worked with Mats Gustafsson, I can attest that this is both extremely hard, but also extremely cool!
Kudos to the authors!
*cell.com/AJHG/fulltext/…


English
Shuang Fu รีทวีตแล้ว

Shuang Fu รีทวีตแล้ว

New scattering compensation method is compatible with widefield #Fluorescence #Microscopy, requiring tens of frames of raw data acquired using random illumination patterns, but without the need for a spatial light modulator or target sparsity: bit.ly/4i9ivOW
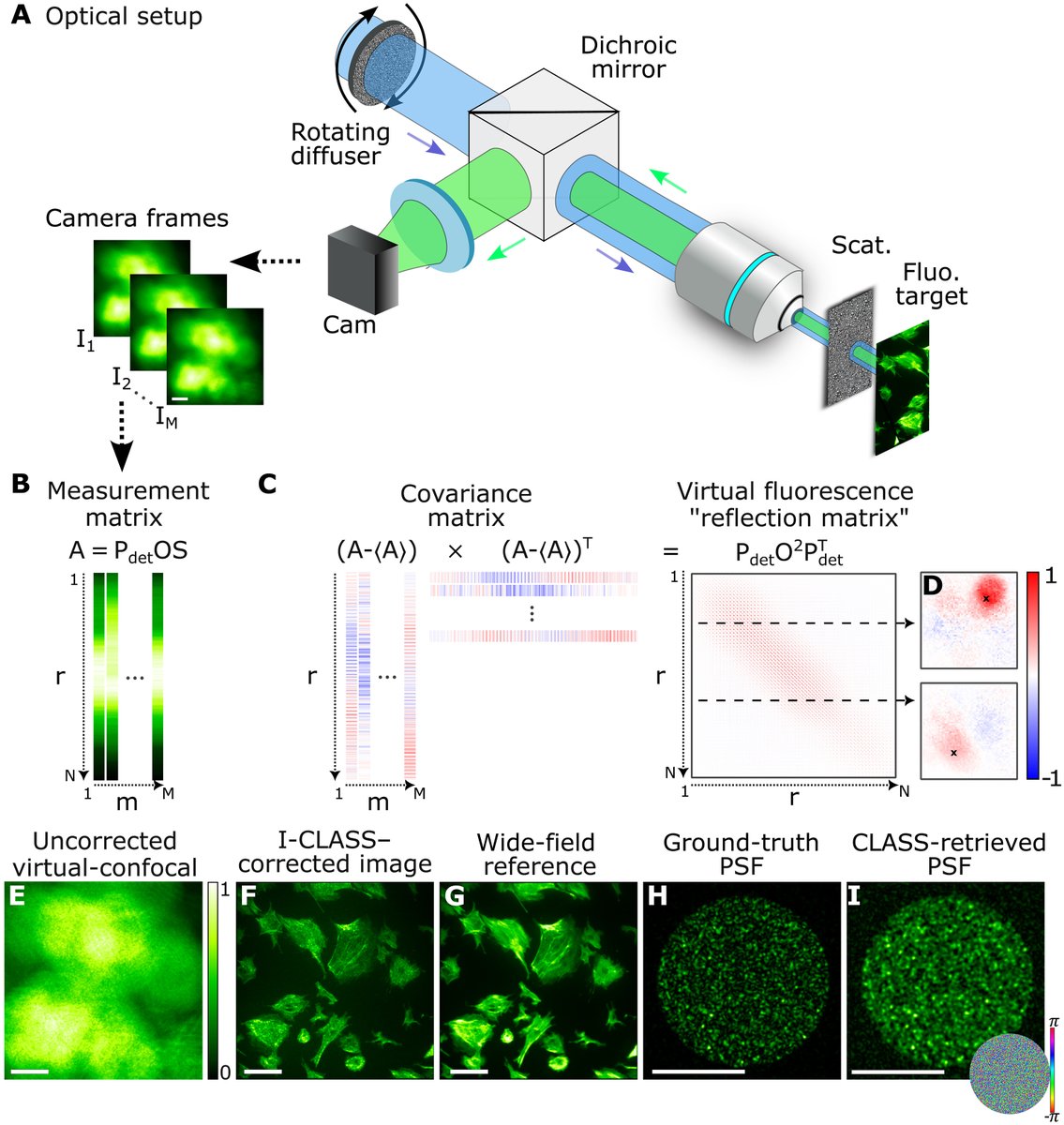
English
Shuang Fu รีทวีตแล้ว
PetaKit is great; it deals efficiently with large data, and it is easy to use. I can highly recommend it if you need deskewing, rotation and/or deconvolution for your post-processing.
The repository is also not large, so it does not take much to clone it and try it out.
HHMI | Janelia@HHMIJanelia
Introducing PetaKit5D: a comprehensive suite of software tools for processing petabyte-scale microscopy data from Janelia Sr Fellow/HHMI Investigator @Eric_Betzig, Xiongtao Ruan, Matthew Mueller, Srigokul Upadhyayula @ABCUCBerkeley @UCBerkeley & colleagues nature.com/articles/s4159…
English
Shuang Fu รีทวีตแล้ว
Introducing spIsoNet, a software tool that addresses the challenges of map anisotropy and particle misalignment in cryo-EM caused by the preferred orientation problem.
@zhou_lab @yuntaoinnit @hongcheng_fan
nature.com/articles/s4159…
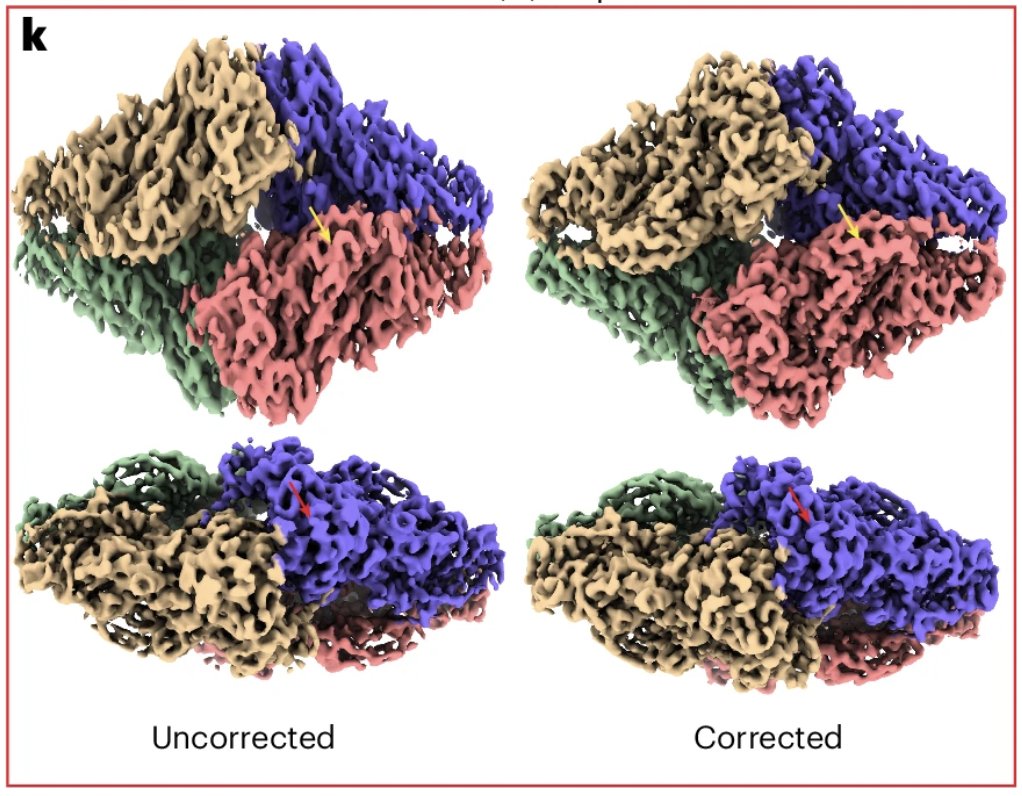
English