Artificial Analysis@ArtificialAnlys
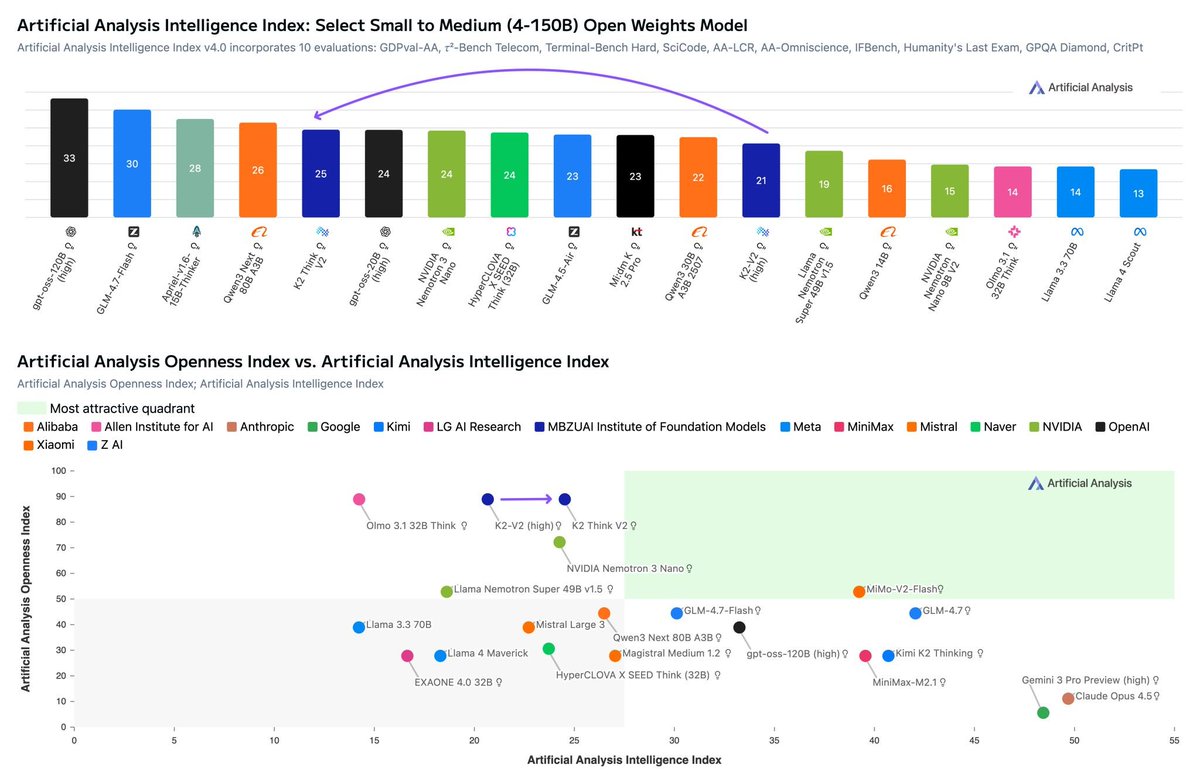
MBZUAI’s Institute for Foundation Models’ new K2 Think V2 model improves on 70B K2-V2 in intelligence, maintains its tied first place in our Openness Index, and has a low hallucination rate
🇦🇪 Third UAE model on Artificial Analysis in the last month: K2 Think V2 is a dense 70B reasoning model. It was post-trained from MBZUAI’s K2-V2, previously released in December 2025. We also recently evaluated Falcon-H1R-7B from TII, another government-sponsored research center from the UAE
📖 Pushes the frontier in Intelligence vs Openness: Like its base model, K2-V2, K2 Think V2 maintains its tied lead in Openness with the Olmo family from Allen Institute for AI. The Artificial Analysis Openness Index is our newly released, standardized, independently assessed measure of AI model openness across availability and transparency. K2 Think V2 provides full access to pre- and post-training data, as well as publishing training methodology and code with a permissive Apache license allowing free use for any purpose. The model is the most intelligent model among highly open peers
🔮 Low hallucination rate: K2 Think V2’s hallucination rate is among the lowest of relevant comparison models. Its hallucination rate sits between Anthropic’s Claude 4.5 Opus and Claude 4.5 Sonnet - Anthropic being a leader in low-hallucination models. The Artificial Analysis Omniscience Hallucination Rate highlights how often models will incorrectly answer knowledge-based questions, rather than abstain. The significant improvement from K2-V2’s hallucination rate from 89% to 52% demonstrates how post-training can effectively reduce hallucination. This contributes to a strong score of -26 for K2 Think V2 in AA-Omniscience, our new knowledge and hallucination benchmark
📈 Improved intelligence among medium-sized (40-150B) open weights models: K2 Think V2 improves by 4 points on its base model. This improvement is driven largely by its reduced hallucination rate (described above), but also its improved long context reasoning capability. K2 Think V2 scores 53% in AA-LCR, our long context reasoning benchmark, a significant jump from 33% in K2-V2
⚡Slightly improved token efficiency: K2 Think V2 uses 10% fewer tokens (99M) than its base model (110M) to run our Intelligence Index
Congratulations to the team at @mbzuai !