ทวีตที่ปักหมุด
nahcrof
1.9K posts

nahcrof
@nahcrof
Cheapest inference provider in the world https://t.co/NhE9WmHpYT
somewhere เข้าร่วม Kasım 2022
47 กำลังติดตาม621 ผู้ติดตาม

@nahcrof everything you do is very impressive. so, when do you sleep?
English

@viktorg475 @bianco_____ I don’t adjust the model, it’s the inference engine and quantization, I can’t control much but I can always do my best
English

@nahcrof @bianco_____ A bit of curiosity on how this all works, why is this your responsibility and not Zhipu's? Aren't you just using their weights? How can you make "adjustments" to an already trained model?
English
@bianco_____ Alright, I’ll admit I haven’t messed with spawning sub agents so I’ll look into it, thank you for the feedback
English


cheapest LLM inference world wide
Clifton Sellers@CliftonSellers
You got 5 words Sell me your service
English

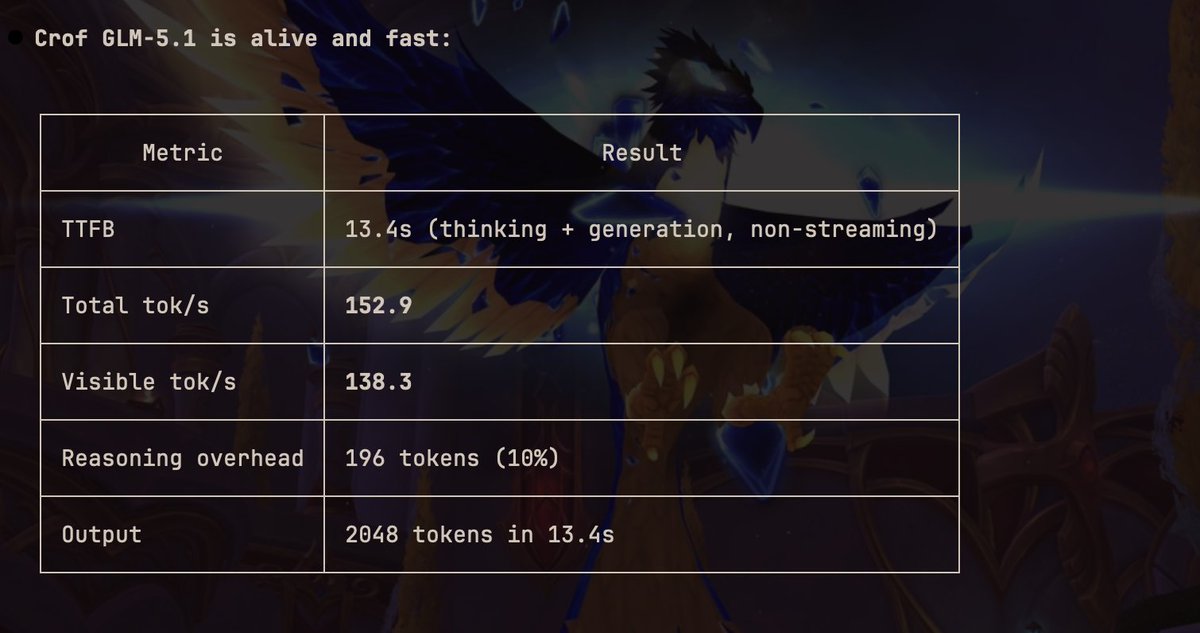
@viktorg475 The tokens are counted by the tokenizer for the model so that’s why there’s variance, as for logging that is some time thing I intend on improving that and glm-5.1 should be better now, infra was struggling to keep up until today when I pushed a patch
English
So I bought some tokens and tried to use your service (glm-5.1) and nothing ever came back after a minute. You need better logging (like Openrouter has). And maybe average relative token expense to your cheapest model (ie: "what model are you?" in minimax is N tokens but N*4 in GLM)
English
@JaidCodes Yes, they actually reached out to me at one point and long story short they decided they didn’t want to (because of a bug that wasn’t our fault)
English


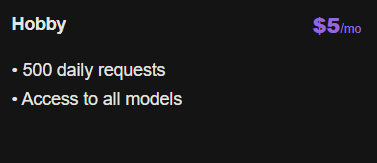
@nahcrof Awesome! Any plans for a $20 plan? The jump from 10 to 50 is pretty significant.
Either that or an option to buy packs like how synthetic does it would be cool.
English

@nahcrof rlly sorry, i just re-did the setup and `crof.ai` worked instead of `crof.ai/v1`. should have tried earlier. i feel stupid now. + earlier it might be down as u were changing inference engine.
great service and great work man :D
English

@nahcrof Does the api and subscription plan both have same infra so technically speed would be same, as chutes has been slow and opencode go hits limit very fast
English
@oneabdulshakoor I have been looking into adding that model, I just don't wanna use more capacity than I can comfortably handle
English
@nahcrof Also stepfun , probably will push me to switch once stepfun 3.5 is available its in top5 and benchmark are crazy for such a small model , just check openrouter usage , i have been following for a while and thinking of switching might try api first to test the speed
English
@adhtri001 I have thought about speculative decoding but I haven't put much effort into it, I might do it though (especially for kimi-k2.5)
English

@nahcrof Hey, was wondering if you wanted to consider eagle3 speculative decoding?
Generally, offers 3x throughput, without any quality loss. Could do 5x in rare cases.
As of now, I think k2.5 have a good eagle3 model in HF.
English