ทวีตที่ปักหมุด

Giving LLMs very large amounts of context can be really useful, but it can also be slow and expensive. Could scaling inference time compute help?
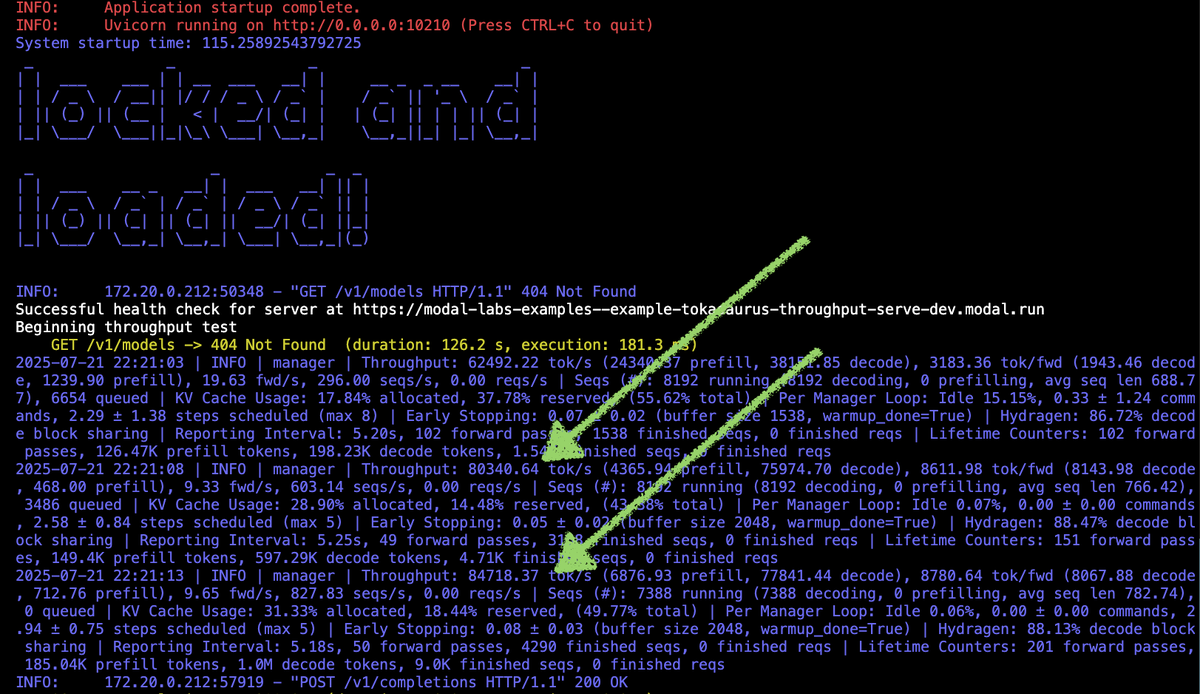
In our latest work, we show that allowing models to spend test time compute to “self-study” a large corpora can >20x decode throughput while maintaining downstream task performance.
Our approach is simple:
1. Use the LLM to sample synthetic conversations about the corpora.
2. Using gradient descent, train a small adapter (we term a Cartridge) on these synthetic conversations to “burn” the corpora into the adapter weights.
Surprisingly, parameterizing this adapter as a KV cache rather than a LoRA lead to both better in-domain task performance and less forgetting of unrelated facts.
There were a bunch of other interesting results like this: take a look at @EyubogluSabri's thread and the paper for more details about our methodology and results.
Joint work with @EyubogluSabri , @simran_s_arora, @NeelGuha, @dylan_zinsley, @james_y_zou, @Azaliamirh, @HazyResearch
& others!
Sabri Eyuboglu@EyubogluSabri
When we put lots of text (eg a code repo) into LLM context, cost soars b/c of the KV cache’s size. What if we trained a smaller KV cache for our documents offline? Using a test-time training recipe we call self-study, we find that this can reduce cache memory on avg 39x (enabling 26x higher tok/s and lower TTFT) while maintaining quality. These smaller KV caches, which we call cartridges, can be trained once and reused for different user requests! Github: HazyResearch/cartridges
English