ทวีตที่ปักหมุด

Pruthviraj P
817 posts

@spidernvdev
Deep Learning SDE @nvidia · ex-nobody cuda guy





triton, gluon, cutedsl, hopper, blackwell, tensorcores, layouts, composition, local_tile, partitionS, partitionD, wgmma, tcgen05, TMA, block scaling, coalesced access, ampere, ada lovelace, cutlass, cublas, cudnn, flash attention, gemm, sgemm, fp16, bf16, mxfp8, nvfp4, int4, quantization, mixed precision, occupancy, reductions, warp divergence, bank conflicts, memory coalescing, shared memory, global memory, texture memory, constant memory, unified memory, epilogues, kernel fusion, graph optimization, tensorrt, torch compile, dynamo, inductor, graph capture, thread blocks, warps, SIMT, streaming multiprocessors, L1 cache, L2 cache, register spilling, thread divergence, memory bandwidth, compute capability, CUDA cores, ldg, stg, ncu, nsys, atomic operations, syncthreads, cooperative groups, dynamic parallelism, persistent kernels, vectorized loads, static quantization, tensors, swizzling, predication, instruction throughput, memory latency hiding...



The Physical AI Robotics GR00T‑X Embodiment Sim dataset has surpassed 10 million downloads on @HuggingFace. 🥳 A huge shoutout to the global research and developer community exploring the future of embodied AI and robotics with this open dataset — you made this milestone possible. 📥 Try it on Hugging Face 👉 nvda.ws/3Qv64Ul


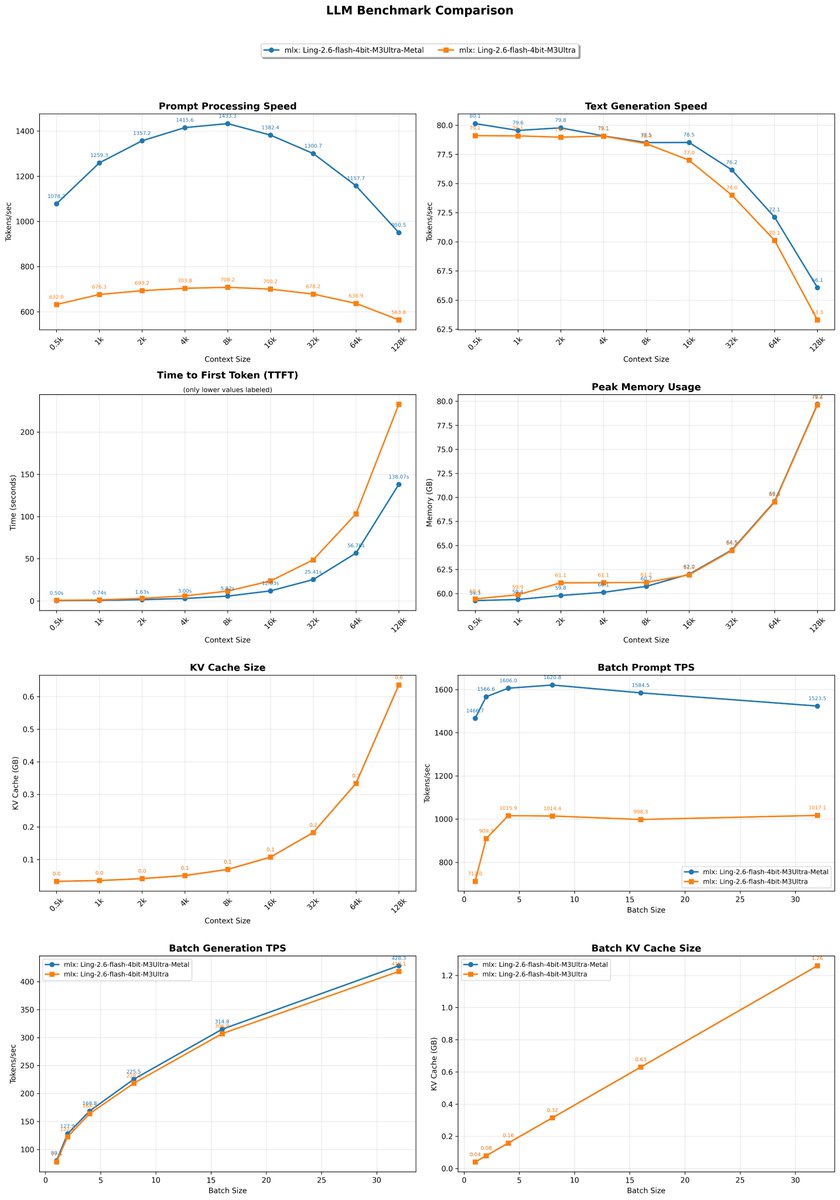
MLX Ling-2.6-flash support added! 💪 Here my (preliminary, because I bet @angeloskath will improve performance) context benchmark for the 4bit version running on M3 Ultra (cooking a new version) I created the PR with the amazing transformer_to_mlx skill by @pcuenq and Opus 4.7. Few iterations and it seems 😂 working 100%! Ultra fast model created by @TheInclusionAI. Can't wait to test it with a code harness! Raw results: Ling-2.6-flash-mlx-4bit MLX Benchmark Results Hardware: Apple M3 Ultra, 512.0GB RAM, 32 CPU cores, 80 GPU cores 0.5k pp 632 tg 79 t/s mem 59.4GB kv 0.03GB 1k pp 676 tg 79 t/s mem 59.9GB kv 0.04GB 2k pp 693 tg 79 t/s mem 61.1GB kv 0.04GB 4k pp 704 tg 79 t/s mem 61.1GB kv 0.05GB 8k pp 708 tg 78 t/s mem 61.2GB kv 0.07GB 16k pp 700 tg 77 t/s mem 61.9GB kv 0.11GB 32k pp 678 tg 74 t/s mem 64.5GB kv 0.18GB 64k pp 637 tg 70 t/s mem 69.5GB kv 0.33GB 128k pp 564 tg 63 t/s mem 79.6GB kv 0.64GB Total generated tokens: 1135 Batch TPS: b1 78 b2 123 b4 164 b8 218 b16 307 b32 418 Batch KV : b1 0.04GB b2 0.08GB b4 0.16GB b8 0.32GB b16 0.63GB b32 1.26GB




