
codex feature request: continue chatgpt conversation in codex / import chatgpt conversation into codex session would be extremely convenient @thsottiaux (even simply an "export to codex" button in chatgpt)
English
Thomas Pethick
124 posts



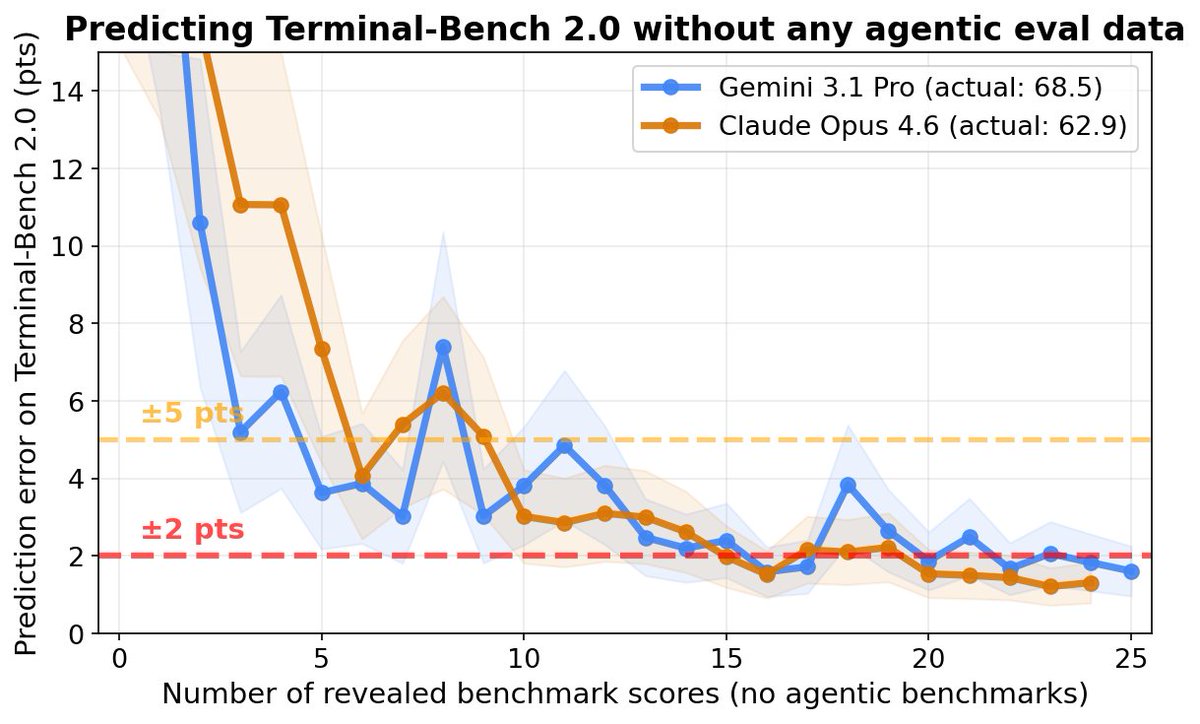









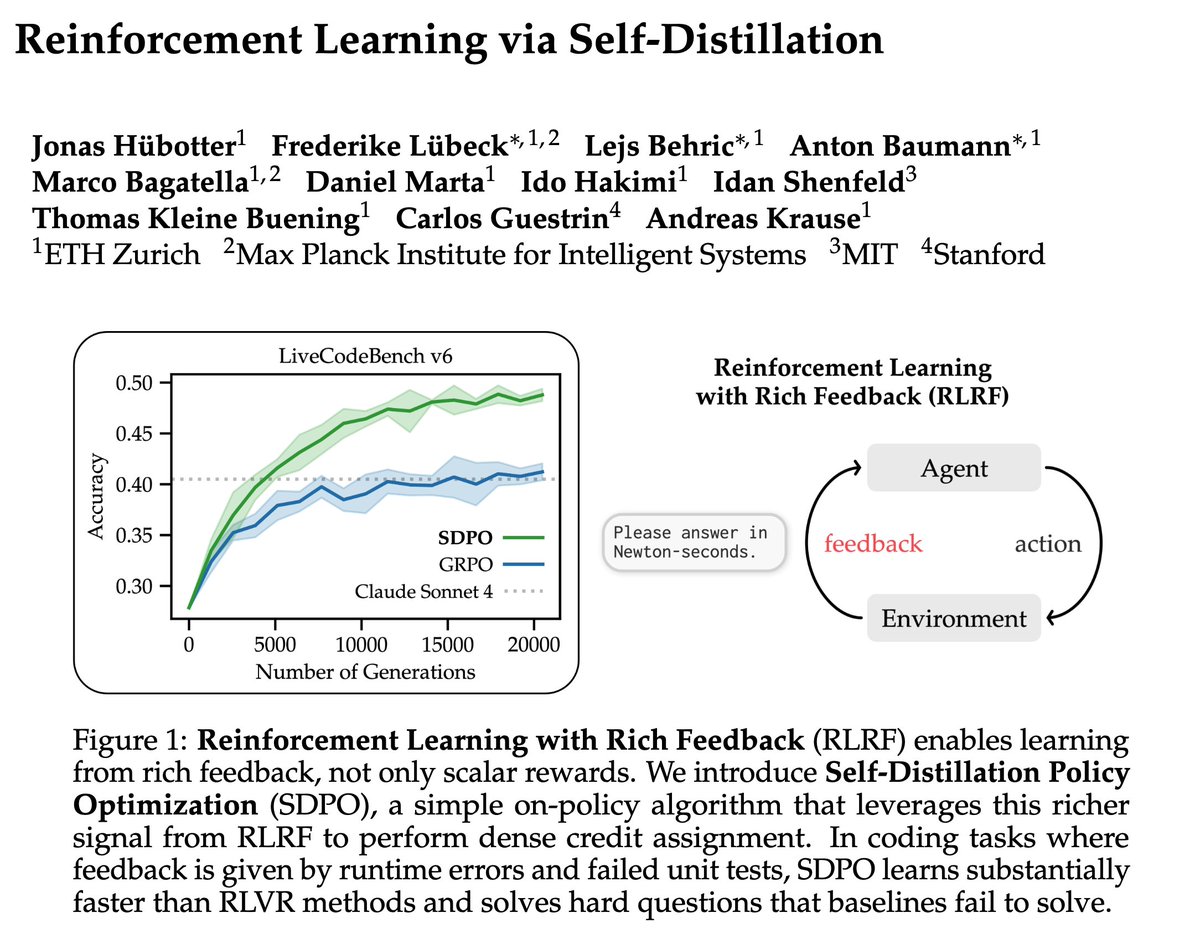


New paper studies when spectral gradient methods (e.g., Muon) help in deep learning: 1. We identify a pervasive form of ill-conditioning in DL: post-activations matrices are low-stable rank. 2. We then explain why spectral methods can perform well despite this. Long thread

