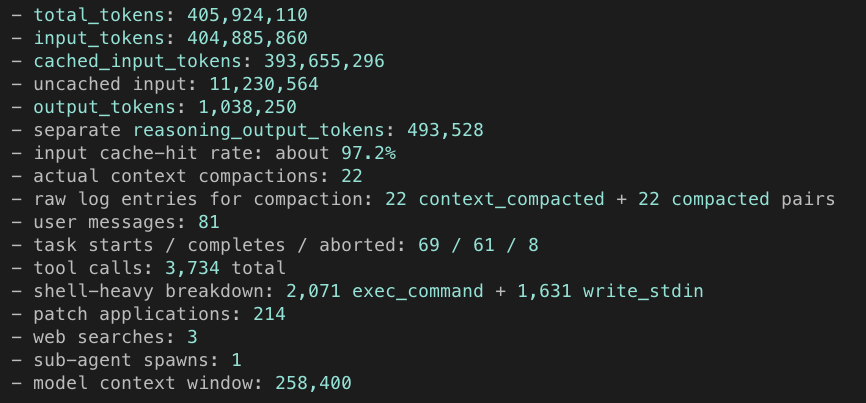
@finbarrtimbers @ChinmayKak the assumption is that the SFT models are then used in RL right? which will reward the model on the correct answers? i guess the open question you are referring to is if there is a diversity benefit to training on incorrect answers during SFT which boosts downstream RL?
English