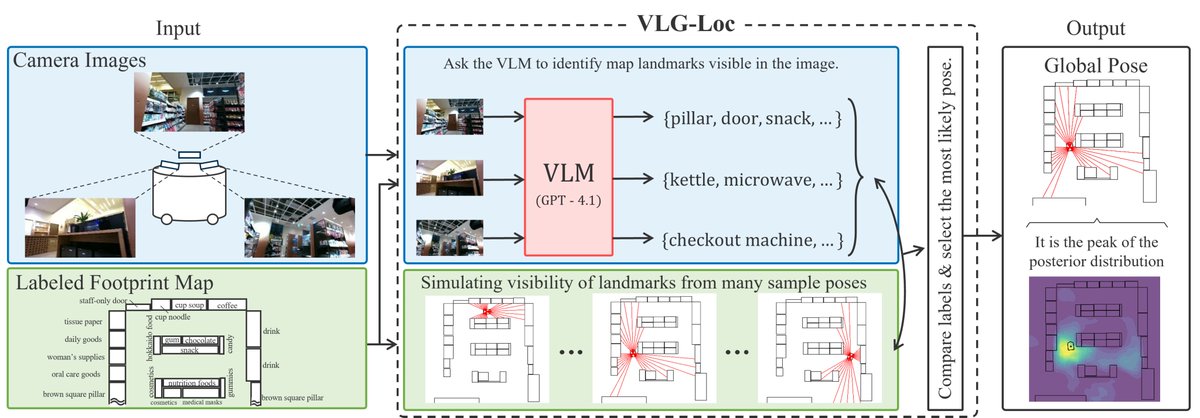
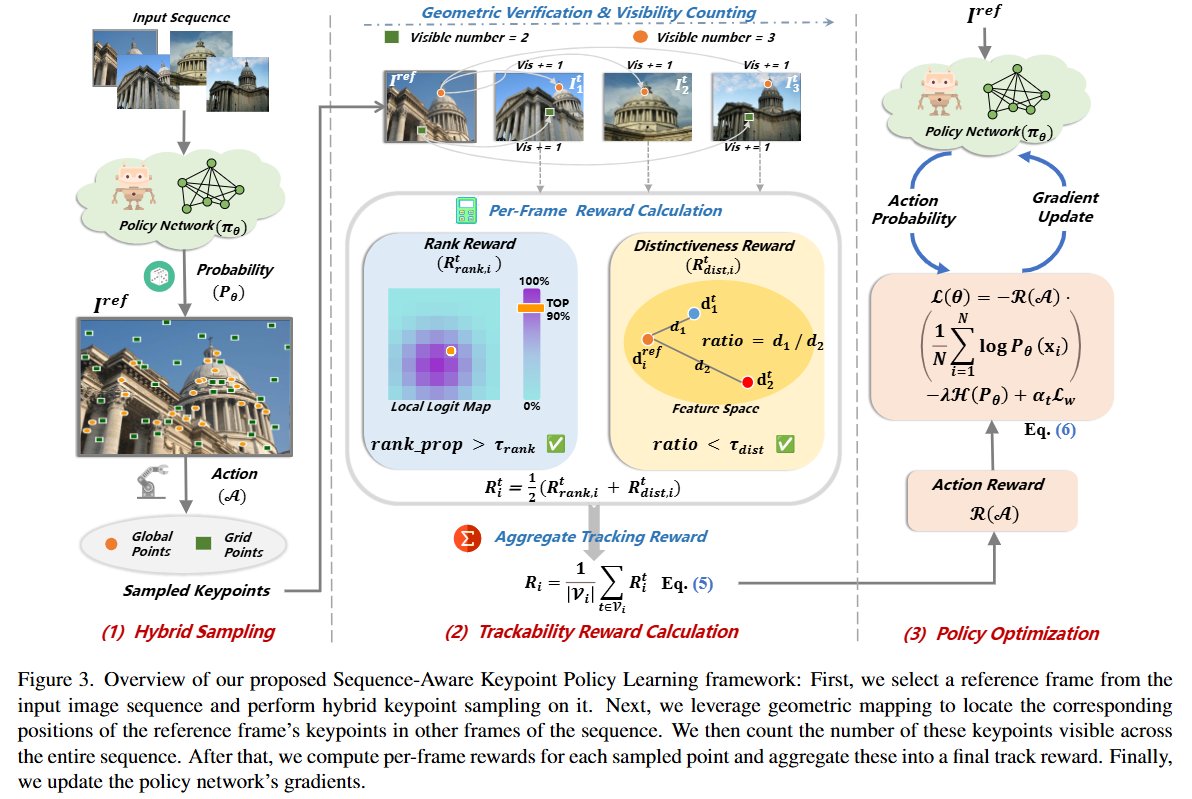
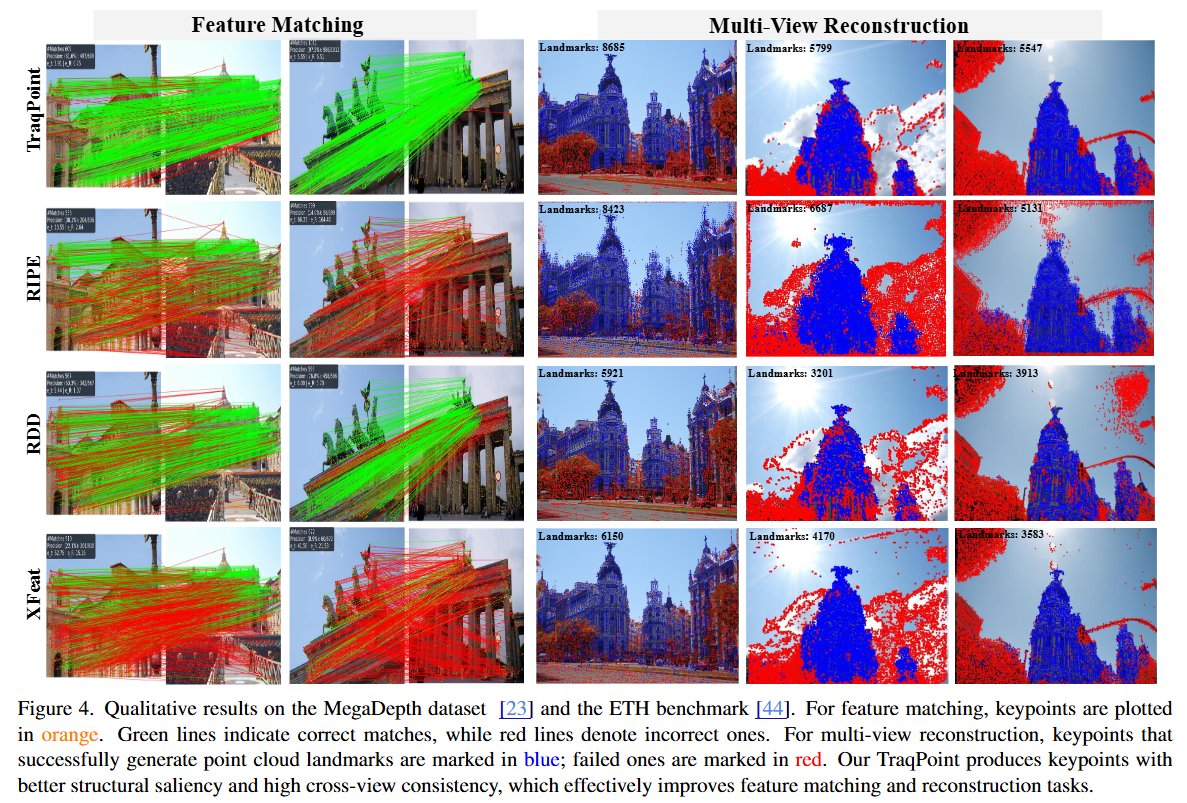
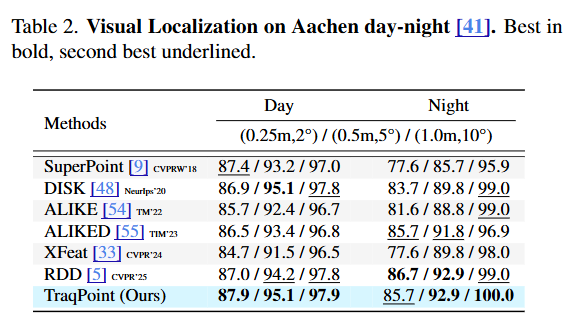
Naka-pin na Tweet

Image matching webui is now deployed on HF, link: huggingface.co/spaces/Realcat…
English
Vincent Qin
1.5K posts

@AlphaRealcat
⭐️Focusing on Visual Localization, SfM and SLAM.


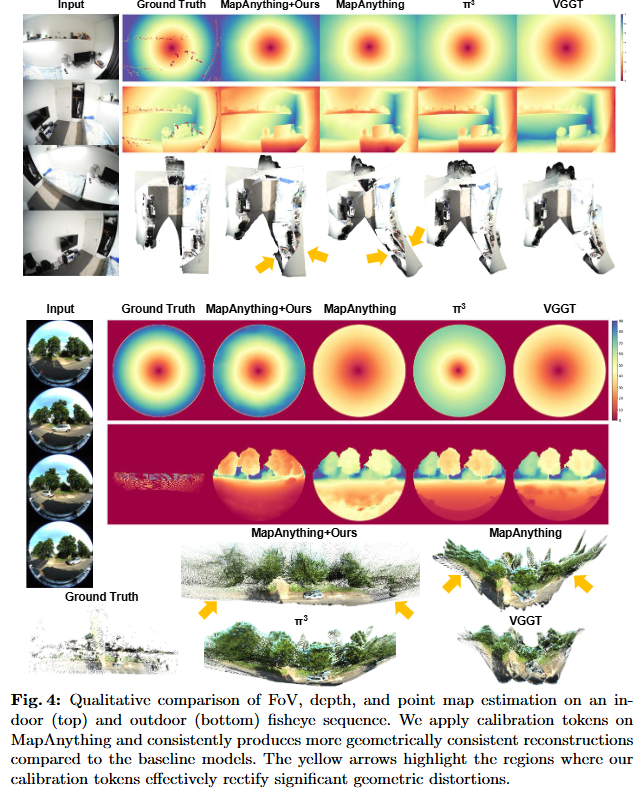


MV-RoMa: From Pairwise Matching into Multi-View Track Reconstruction Jongmin Lee, Seungyeop Kang, Sungjoo Yoo tl;dr: pairwise matches->sampling->initial feature tracks->cross-attention->refined multi-view dense matches arxiv.org/abs/2603.27542









Excited to share that our paper "Global-Aware Edge Prioritization for Pose Graph Initialization" has been accepted to CVPR 2026! #CVPR2026 See you soon in Denver!🥳🥳Code is coming soon💻 🫰Big thanks to my amazing co-authors Giorgos Tolias & supervisors: @majti89 @matas_jiri
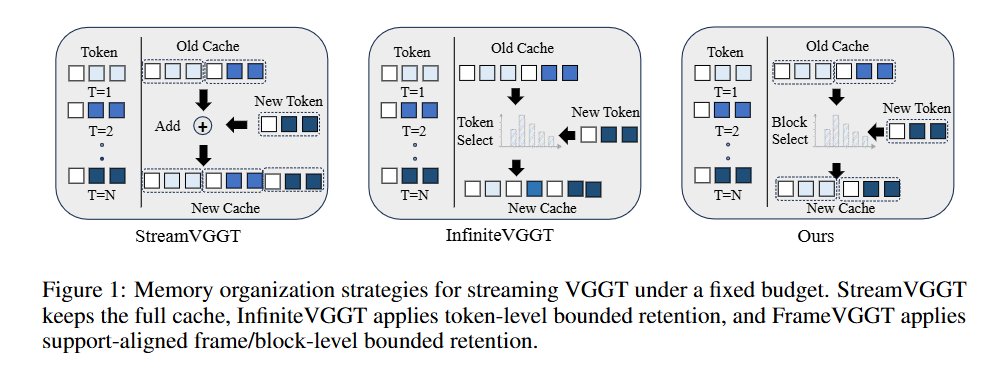
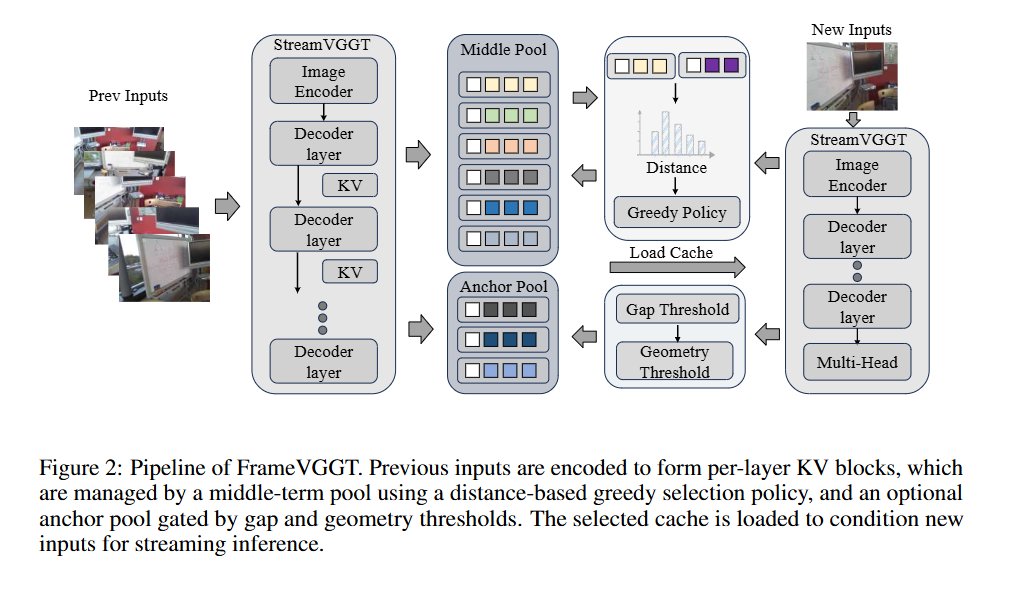
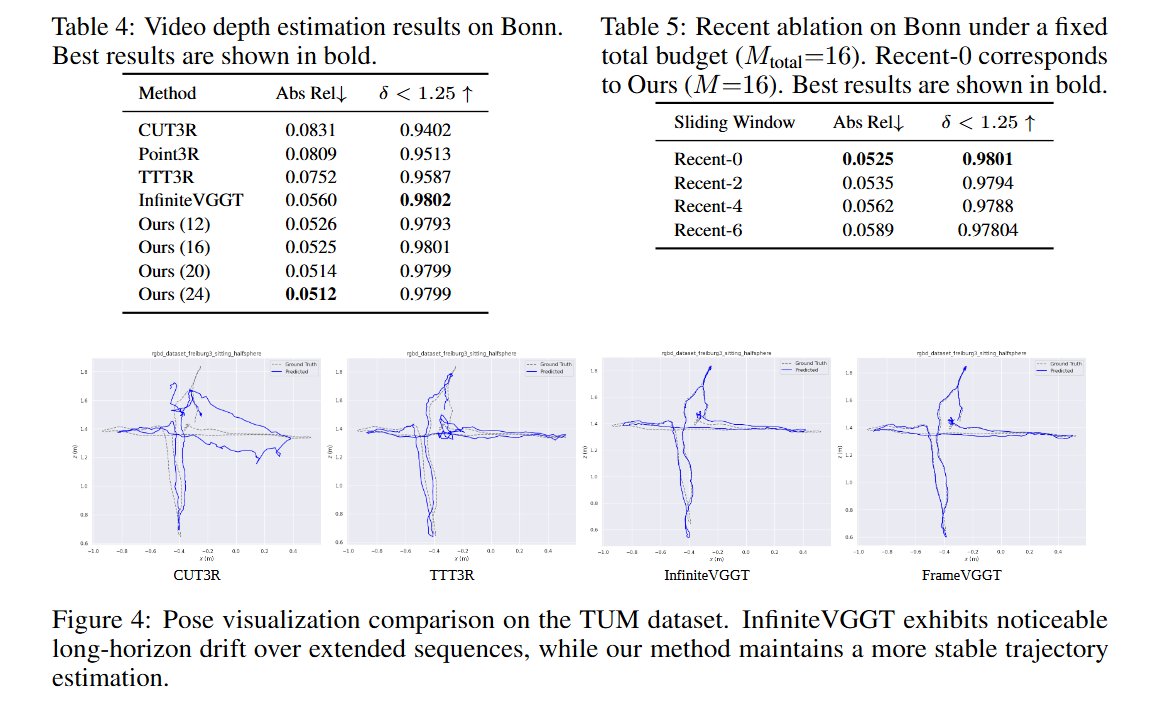
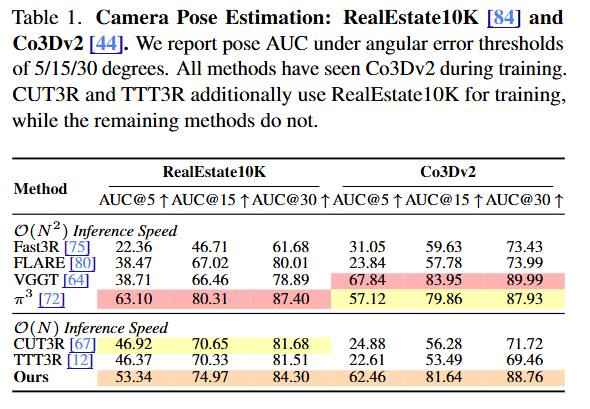
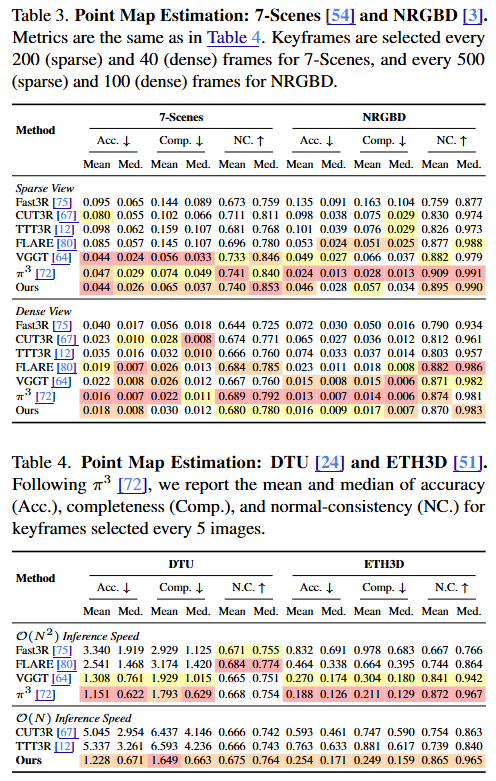
XStreamVGGT: Extremely Memory-Efficient Streaming Vision Geometry Grounded Transformer with KV Cache Compression Zunhai Su, Weihao Ye, Hansen Feng, Keyu Fan, Jing Zhang, Dahai Yu, Zhengwu Liu, Ngai Wong tl;dr: pruning and quantization->StreamVGGT arxiv.org/abs/2602.21780