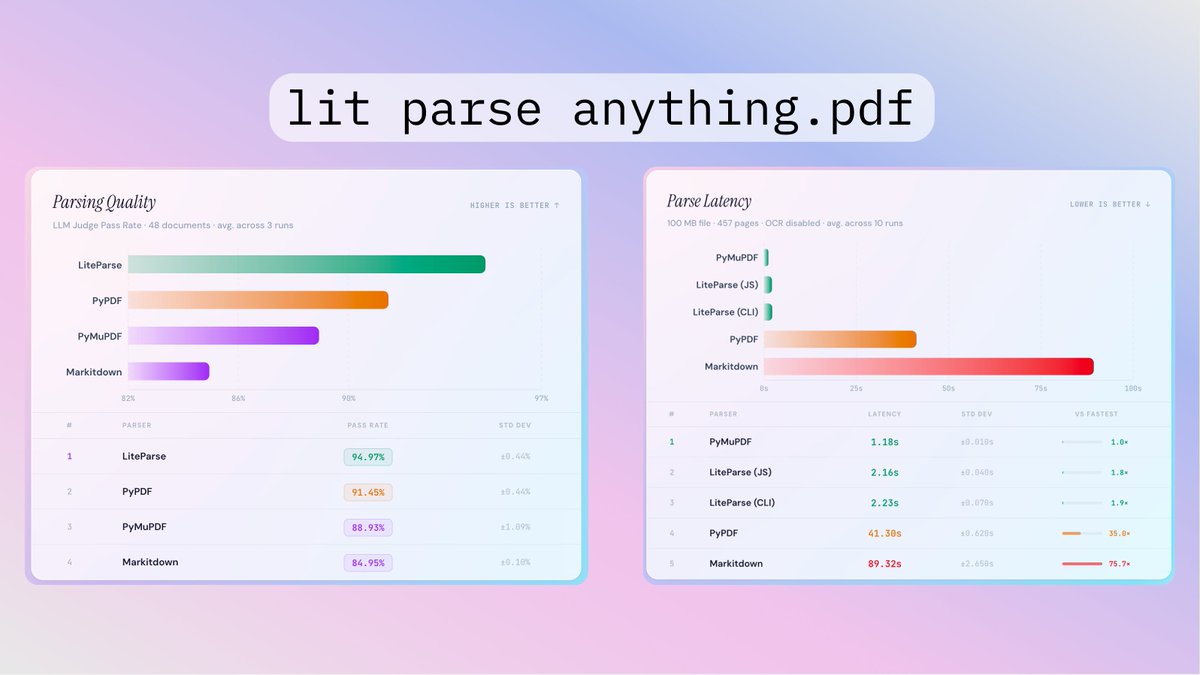
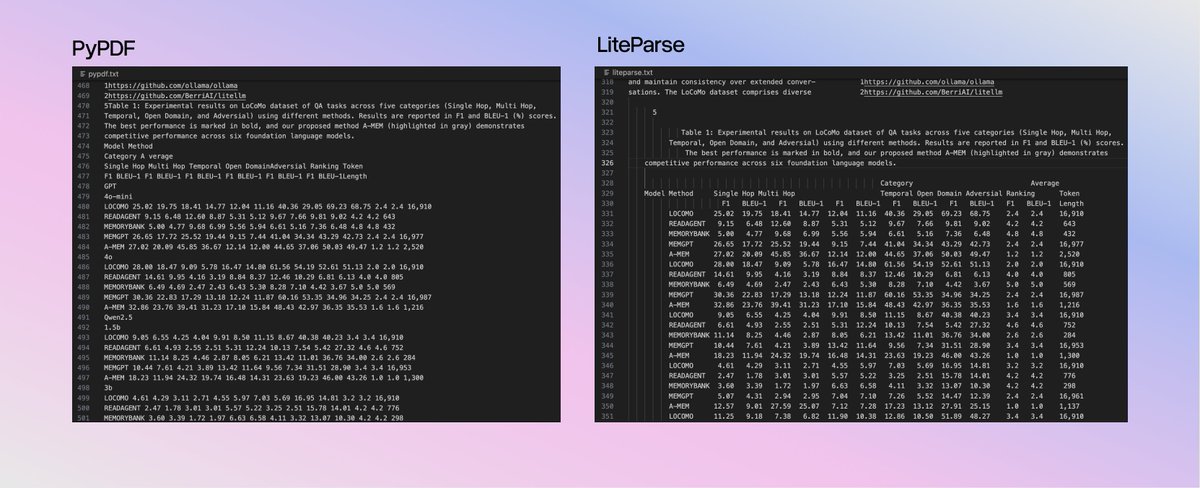
LlamaIndex Releases LiteParse: A CLI and TypeScript-Native Library for Spatial PDF Parsing in AI Agent Workflows The technical shift here is significant: - Zero Python Dependencies: Built natively in TypeScript using PDF.js and Tesseract.js. It runs entirely on your local CPU—no API keys, no latency, and no data leaving your environment. - Spatial Text Parsing: Instead of struggling with complex Markdown conversion, LiteParse projects text onto a spatial grid. It preserves the document's original indentation and layout, allowing LLMs to use their internal spatial reasoning to interpret tables and multi-column text. - Multimodal Agent Support: Beyond text, LiteParse generates page-level screenshots. This allows your AI agents to "see" charts, diagrams, and visual context that text-only parsers miss. Full Analysis: marktechpost.com/2026/03/19/lla… Repo: github.com/run-llama/lite… Technical details: llamaindex.ai/blog/liteparse…? @llama_index @tuanacelik