johnny
22 posts

johnny
@johnnylin
@neuronpedia. prev @apple.
San Francisco, CA Sumali Ocak 2009
3 Sinusundan539 Mga Tagasunod

johnny nag-retweet

Researchers can use the Neuronpedia interactive interface here: neuronpedia.org/gemma-2-2b/gra…
And we’ve provided an annotated walkthrough: github.com/safety-researc…
This project was led by participants in our Anthropic Fellows program, in collaboration with Decode Research.
English
johnny nag-retweet

Announcement: we're open sourcing Neuronpedia! 🚀
This includes all our mech interp tools: the interpretability API, steering, UI, inference, autointerp, search, plus 4 TB of data - cited by 35+ research papers and used by 50+ write-ups.
What you can do with OSS Neuronpedia: 🧵
GIF
English
johnny nag-retweet

Neuronpedia now hosts Chain-of-Thought! Steer and inspect Deepseek-R1-Distill-Llama-8B with SAEs trained by @Open_MOSS on @neuronpedia (linked below). One fun initial result: the model can easily be steered into "overthinking/anxious" mode with a single latent.


English
johnny nag-retweet

Google DeepMind has a new way to look inside an AI’s “mind” trib.al/UN5W3Uh
English
johnny nag-retweet

Gemma Scope allows us to study how features evolve throughout the model and interact to create more complex ones.
Want to learn more? Here’s an interactive demo made by @neuronpedia - no coding necessary ↓ dpmd.ai/gemma-scope
GIF
English
johnny nag-retweet

Want to learn more? @neuronpedia have made a gorgeous interactive demo walking you through what Sparse Autoencoders are, and what Gemma Scope can do.
If this could happen pre-launch, I'm excited to see what the community will do with Gemma Scope now!
neuronpedia.org/gemma-scope

English
johnny nag-retweet
Sparse Autoencoders act like a microscope for AI internals. They're a powerful tool for interpretability, but training costs limit research
Announcing Gemma Scope: An open suite of SAEs on every layer & sublayer of Gemma 2 2B & 9B! We hope to enable even more ambitious work
GIF
English
exciting new research from @apolloaisafety and @jordantensor: E2E SAEs (w/ ~700k features) are now live on @neuronpedia - the first to use dual UMAPs for visual comparison and exploration between SAE training methods.
check it out at neuronpedia.org/gpt2sm-apollojt

Lee Sharkey@leedsharkey
Proud to share Apollo Research's first interpretability paper! In collaboration w @JordanTensor! ⤵️ publications.apolloresearch.ai/end_to_end_spa… Identifying Functionally Important Features with End-to-End Sparse Dictionary Learning Our SAEs explain significantly more performance than before! 1/
English
Terrific work by @saprmarks and team! 🥳
We really enjoyed working with them to get their Sparse Autoencoders onto @neuronpedia.
You can explore, search, and test their 622,594 features here: neuronpedia.org/p70d-sm
Samuel Marks@saprmarks
Can we understand & edit unanticipated mechanisms in LMs? We introduce sparse feature circuits, & use them to explain LM behaviors, discover & fix LM bugs, & build an automated interpretability pipeline! Preprint w/ @can_rager, @ericjmichaud_, @boknilev, @davidbau, @amuuueller
English
6/ Oh and of course, @neuronpedia is publicly available for anyone to experiment and play with at neuronpedia.org. Let us know what you think!
English
5/ Thanks to @JBloomAus for support, @NeelNanda5 for TransformerLens, @ch402 @nickcammarata for inspiration from OpenAI Microscope, and William Saunders for Neuron Viewer.
It's time to accelerate (interpretability research). 🚀🔬
lesswrong.com/posts/BaEQoxHh…
English
1/ Introducing Neuronpedia: an open platform for interpretability research with hosting, visualizations, and tooling for Sparse Autoencoders (SAEs).
Let's try it out! ➡️
Neuronpedia lets us instantly test activations of SAE features with custom text. Here's a Star Wars feature:
English
johnny nag-retweet

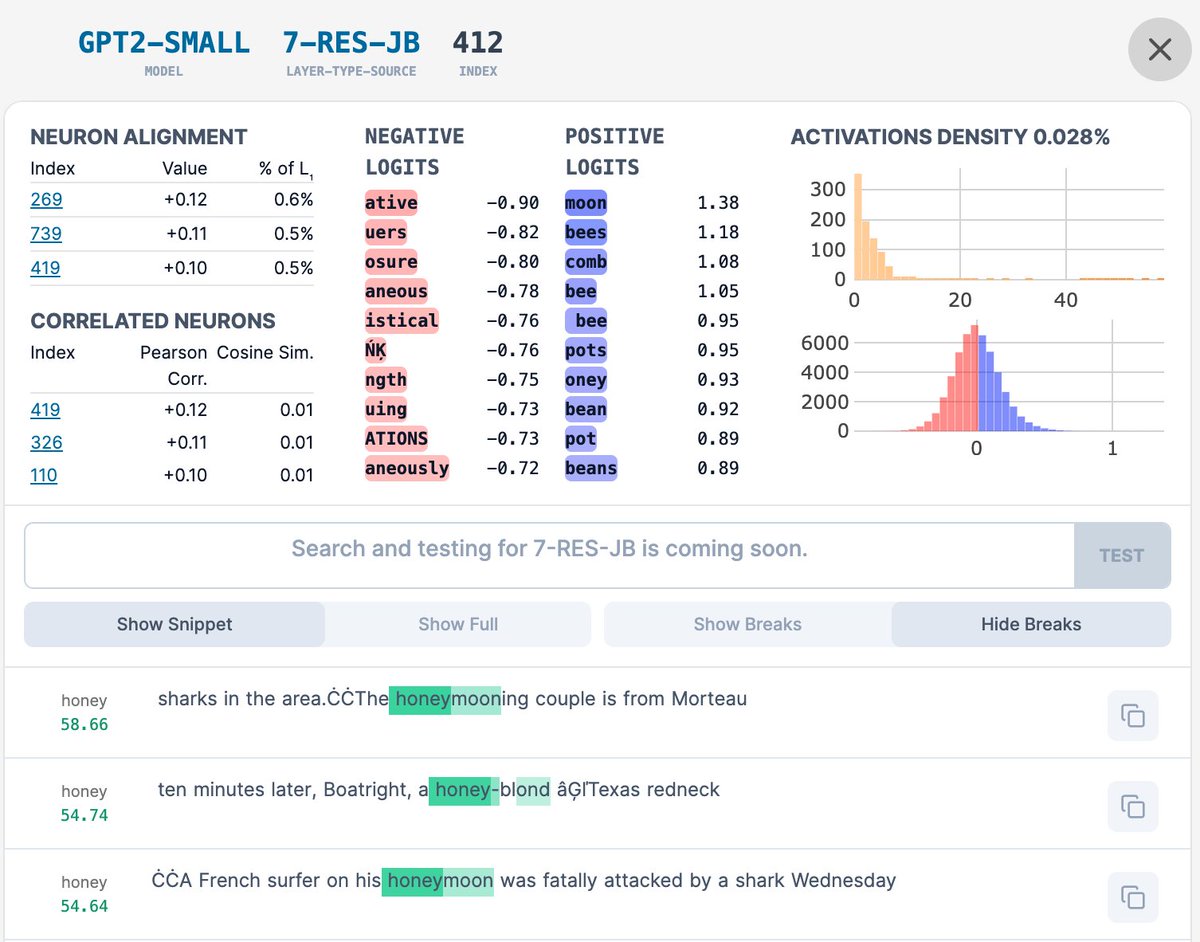
Super impressed by @johnnylin's Interactive Interface for exploring my GPT2 Small SAE Features. neuronpedia.org/gpt2-small/res….
First 5000 for each layer are there with the rest coming shortly! We've updated the feature-activation highlighting to better show multiple fires per context!
English
johnny nag-retweet

Openly Operated wants to make privacy policies actually mean something theverge.com/2019/6/18/1868…

English