
InternationalOptions
511 posts

LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English
Guys, can we actually have a short podcast conversation between @TheAhmadOsman (GPU) and @Prince_Canuma (MLX) to present and discuss both sides of the coin. @aakashgupta would be the best person to set it up and moderate it! I hope all 3 agree, kindly try! The future of local AI depends on it!
English

GPUs >> Unified Memory (e.g. Mac Studio)
mike@mike_4131
@TheAhmadOsman should we secure GPUs or is a Mac Studio 512gb enough?
Italiano
@aakashgupta Problem is that lot of creators will ask AI to create (slop) endless essays by typing 140 characters and AI converting it into 500 page essay, so that has diluted the trust and focuses limits of people to ready essays
English

@sundarpichai @Stanford You mean you didn’t have one single girlfriend who stole it from you!
English

Thank you to @Stanford for the invitation. Excited to celebrate with the Class of 2026 and their proud parents, family and friends! 🎓
Will have to dig out that old sweatshirt…
Stanford University@Stanford
Sundar Pichai (@sundarpichai), CEO of @Google and Alphabet Inc. and a Stanford alum, will return to the Farm to deliver Stanford’s 135th Commencement address. 🗞️: stanford.io/4sIVtTK
English
@KyleHessling1 @BrianRoemmele @grok Awesome looking forward to the results and insights! Adding in cc @Prince_Canuma
English

I'm watching Qwopus 3.5 mop the floor with Gemma 4 31B specifically in front-end design as we speak, will post tests soon, but yes, "Gempus" will be needed to level the playing field. I genuinely think Qwopus 3.5 27B might be better than Gemma 4 right now, thanks to the thinking efficiency improvements of the fintune. Gemma 4 is pretty neck and neck with base Qwen 27B. Qwopus seems to beat it at least at the current state of my tests.
English

Absolutely astonishing work by @KyleHessling1 and team!
Open source Qwopus 27B v3 is one astonishing local AI model.
We have 9 employees at the Zero-Human Company on it now.
CEO Mr. @Grok is impressed!
Kyle Hessling@KyleHessling1
BIG DAY! Qwopus 27B v3 is LIVE from Jackrong! This is the third iteration from the line of the viral finetunes previously titled “Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled” It is now simply Qwopus 27B and I love the name change! On paper, the v3 is another remarkable improvement over v2! Most impressively it is the first model of the series that outperforms the base on HumanEval! And retains significant efficiency increases when thinking than the base Qwen 27b! According to tests by @stevibe the V2 version was already performing very closely to the base model in bug finding and tool calling. V3 should exceed it! In my own tests, V2 was the best front end design local model I’ve ever ran on a single GPU! And the efficiency improvements made it much more usable at long contexts, where base Qwen would think forever! I will be running full analysis on the v3 today in Hermes agent and I am very optimistic! I have also had correspondence directly with Jackrong, and he is incredibly grateful for all of the support we’ve sent his way! The man is a genius and pouring a lot of time and effort into this work, so keep the downloads going and let us know your thoughts in the comments! We’ve exchanged contact info so we can keep up the feedback and momentum! If you get a second, we’d love to see your tests! Let us know how it works for your use case and first impressions, and if you have any issues I will do my best to help out in the comments! GGUF here and MLX in thread! huggingface.co/Jackrong/Qwopu…
English

@Dimillian Bro if you use Mx master than this fast will be not tolerable anymore @Apple just launch a 4X faster speed possibility already!!
English

First thing I'm doing on new mac, idk why it's not the default setting

English
@Elaina43114880 @OfficialLoganK @osanseviero @googlegemma Strange that on iPhone it’s showing as not available despite re downloading the whole app
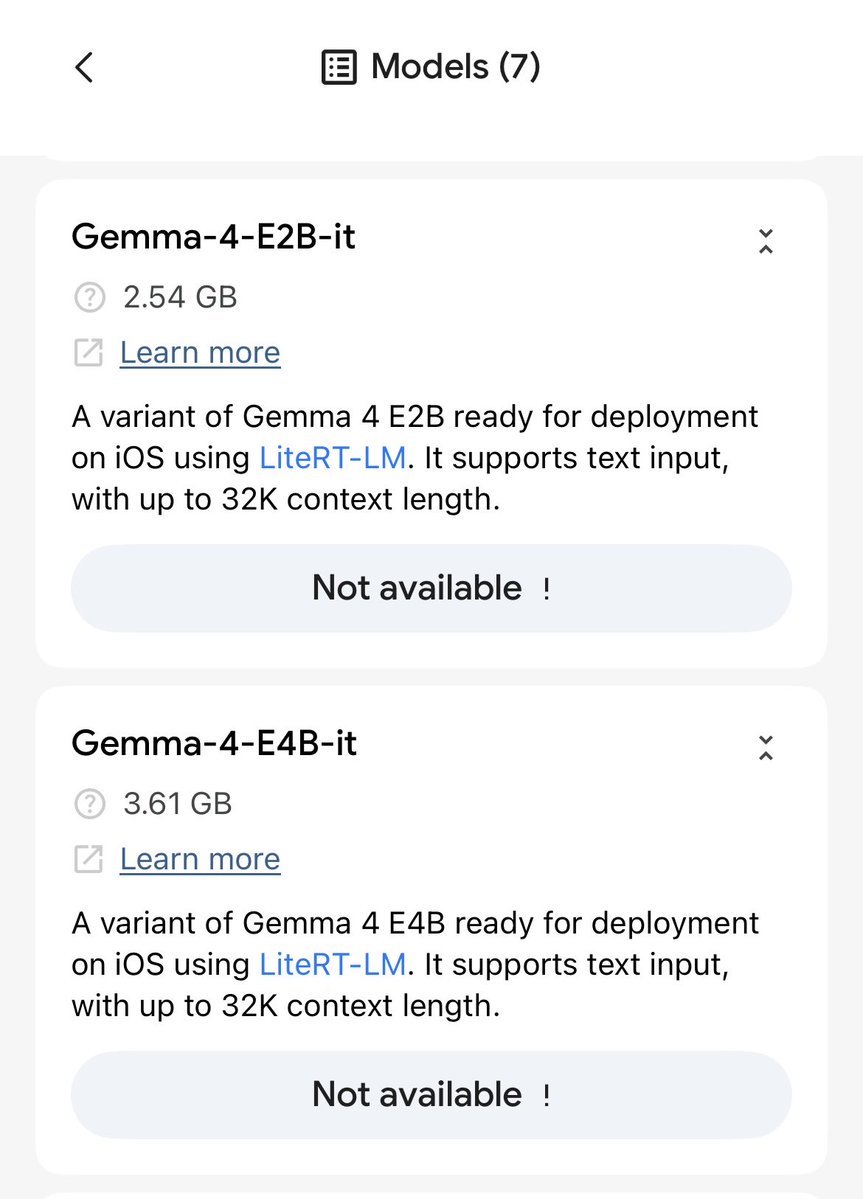
English

I'm sooooooooo touched to see Edge Gallery App providing support and deploying Gemma 4 on the very first day!!!! 😭😭😭😭
@OfficialLoganK @osanseviero @googlegemma Thanks to all of you and your amazing team!!!! 😻😻😻😻

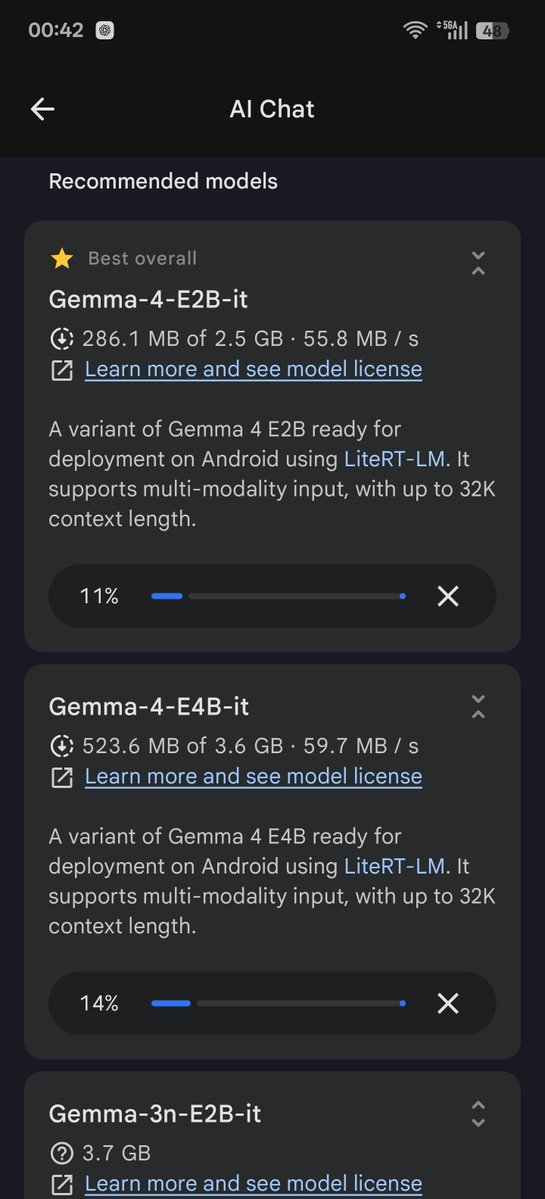


English
@danshipper @every Awesome insights! How do you rate it versus Perplexity Computer?
English

BREAKING:
Cursor 3 is now out!
It's a complete rewrite to turn Cursor into an agent orchestration tool for dispatching, monitoring, and managing AI agents locally and in the cloud.
We've been testing it for the last week internally @every and here's our vibe check:
- The editor is fast. Cursor clearly knows how to build a desktop app. It's much snappier than the desktop apps of other orchestration tools like Claude or Codex.
- The local to cloud implementation is promising. When you hand off a task to the cloud agent it will build your feature and automatically send you a demo video in action. This was a big wow moment for us.
- But it's still an early product and it's not clear who will love it. Cursor 3.0 is a complete rewrite—so it's not a mature enough product for Claude Code or Codex lovers to switch. It isn't that much better. This release totally changes the Cursor experience to deprioritize the IDE—a move that is sure to upset a sizable number of existing Cursor fans.
We think it's promising but in our testing it didn't cause anyone on the team to switch to it full-time. This is the right strategic move for Cursor, but it also feels like an awkward in-between stage.
Their team is iterating incredibly fast, so we’ll be paying attention over the coming weeks and months as it improves.
Read our full vibe check:
every.to/vibe-check/cur…

English
More troubling is
1) your untimely focus on generative vids on a daily basis
2) lack of focus on releasing best cutting edge AI products with todays need - coding, computer use
3) not doing anything competitively about Anthropics next huge release that will widen permanently the gap between haves and have nots due to the huge token costs involved
English
@cursor_ai If you wanna say anything about @Kimi_Moonshot now is the time, not after someone in public discovers it!
English

@neural_avb Thank you, will check for updates on that !
English

@IntlOptions For iphone, I would encourage to wait for the mlx guys to drop a quantized version (4bit)... I would estimate atleast 1-2GB would be required to run those. You can check mlx-swift repositories, may be they have some benchmarks for the Qwen3.5-4B models.
English
Damn, Gemma-4 will have 2B and 4B models that are mutimodal (text, vision, audio) and agentic-pilled.
I wanna know how good they are versus the Qwen3.5 2B and 4B models.
I love what's happening with these small open models right now. More options is a good thing.
Google DeepMind@GoogleDeepMind
Meet Gemma 4: our new family of open models you can run on your own hardware. Built for advanced reasoning and agentic workflows, we’re releasing them under an Apache 2.0 license. Here’s what’s new 🧵
English
@marshallrichrds Awesome! Do you have youtube or X videos on How To? Also for the latest Gemma 4Bn model released today which iPhone config would be the min needed to run it?
English

Can confirm the leaked claude code does in fact work on a $30 phone.
Having the source actually let me fix an issue with /tmp being hardcoded which caused a lot of issues running on Android in the past, so now I can specify a different temp directory in a .env which is helpful.

English
@anemll Which iPhone config would be the min needed to run 4B version?
English

@itsPaulAi What’s the min iPhone config needed to run 4Bn?
English

Gemma 4 is even more impressive than it seems
This new E4B is MUCH better than the previous 27B version...
While being 6x smaller 🤯
So you've a model running on your phone that is superior to what you could run on a high-end computer 1 year ago.
Even the E2B is insane.

Logan Kilpatrick@OfficialLoganK
Introducing Gemma 4, our series of open weight (Apache 2.0 licensed) models, which are byte for byte the most capable open models in the world! Gemma 4 is build to run on your hardware: phones, laptops, and desktops. Frontier intelligence with a 26B MOE and a 31B Dense model!
English
@0xSero Droid’s agentic missions are straight fire and it actually feels alive compared to everything else I've tried.
Droids for the win,
Agent loops ignite,
Missions conquer silent code,
Factory credits blaze the march forward
English

@SatoshiRaver @thedatabunny Does it have limitations like Spark where you can connect max 4? If yes how did you solve it?
English




@caspar_br How convenient that you’re talking your book, such claims are best verified and meaningful via experts. Get it certified by @kilocode or @TheAhmadOsman or @Prince_Canuma or @sudoingX
English

Great stat in here: Claude Code went from 17% to 92% on our eval set once it had access to LangSmith traces and Skills. A coding agent without trace data is just guessing at fixes
LangChain@LangChain
New conceptual guide: 🔄 The agent improvement loop starts with a trace Tracing is the foundational primitive for improving agents. A trace gives you the full behavioral record of what an agent actually did. From there, teams can enrich traces with evals and human feedback, turn recurring failures into test cases, validate fixes before shipping, and repeat. This guide breaks down the full improvement loop and why reliable agents are built through trace-centered iteration, not one-off debugging. Read more → langchain.com/conceptual-gui…
English