Paul
350 posts


Paul
@PaulOctoBot
Making crypto investment easier with @DrakkarsOctoBot










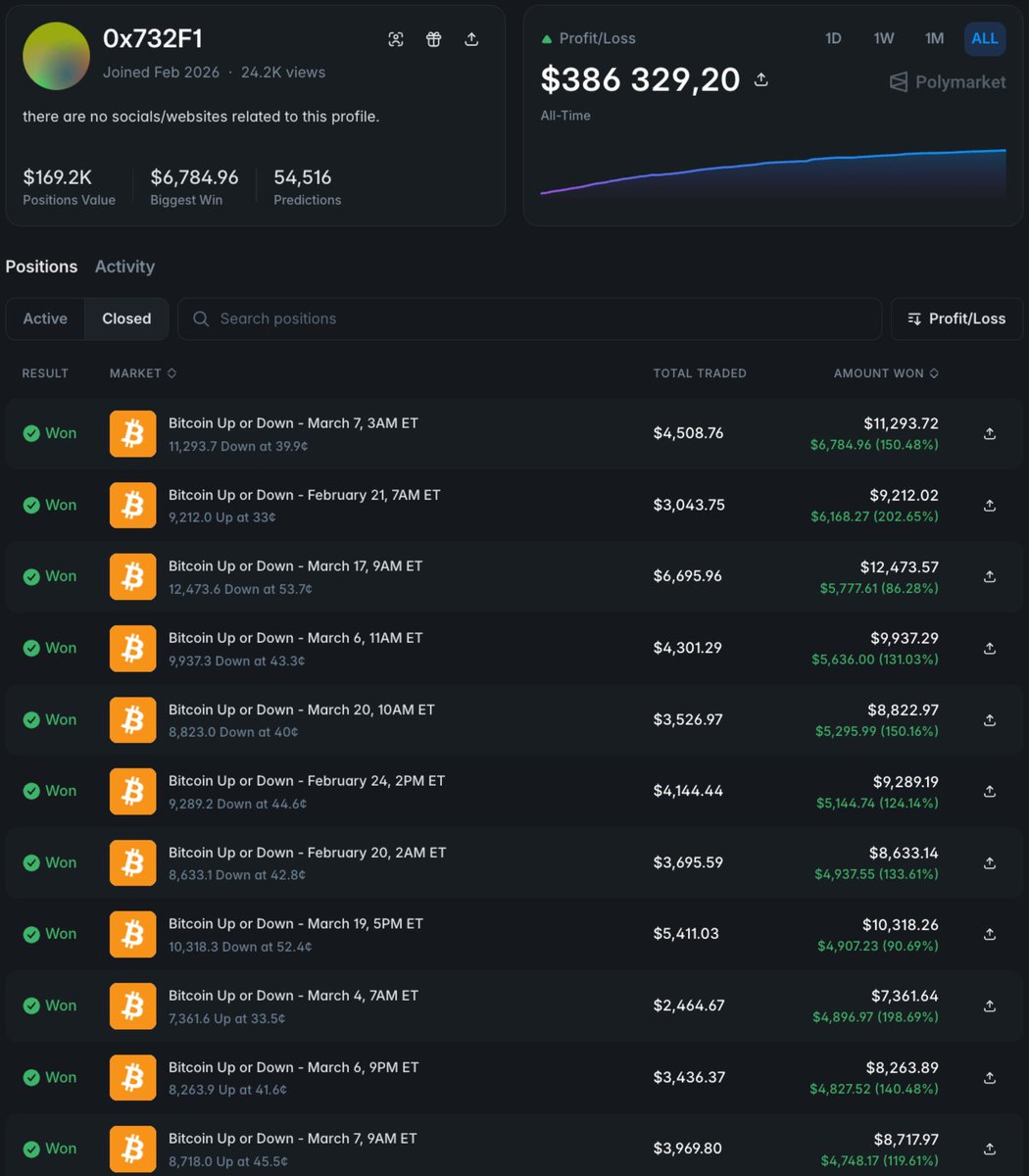
These 3 bots trading Polymarket made $13,801 in 8 hours (67.1% win rate) Wasn’t trying to build something crazy just split the market into 3 simple systems Prediction Alpha LLM reads news / twitter / narratives -> text -> signal > direction -> enters when sentiment moves before price It’s noisy, but catches the early moves Liquidity Beta - no predictions -> spread > fees > execute -> orderbook imbalance > lean -> bad quotes / routing lag > capture just constant micro-PnL dΠ/dt ≈ α · (spread − fees) · flow − β · latency² Gamma Harvest Only trades when things get unstable -> volatility spikes -> event repricing -> panic moves doesn’t predict direction just trades mispriced convexity edge ≈ γ · σ² · ∂²P/∂x² combined it behaves like: E[PnL] ≈ Σᵢ (αᵢ + βᵢ + γᵢ) · (1 / latency) · liquidity not perfectly clean math but surprisingly close to reality Most people try to build one “smart” model but markets don’t fail in one way -> narratives lag -> liquidity disappears -> volatility gets mispriced So instead of one model i just separated the failure modes 3 simple bots > 1 complex system LLMs didn’t make it smarter Just faster at seeing where the market is wrong















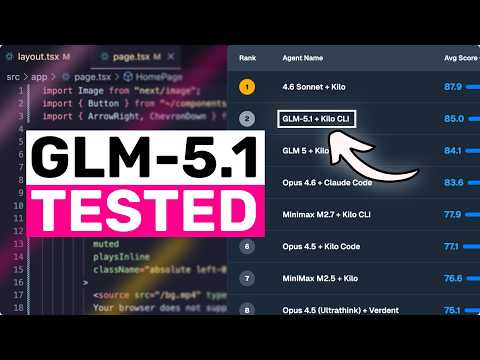
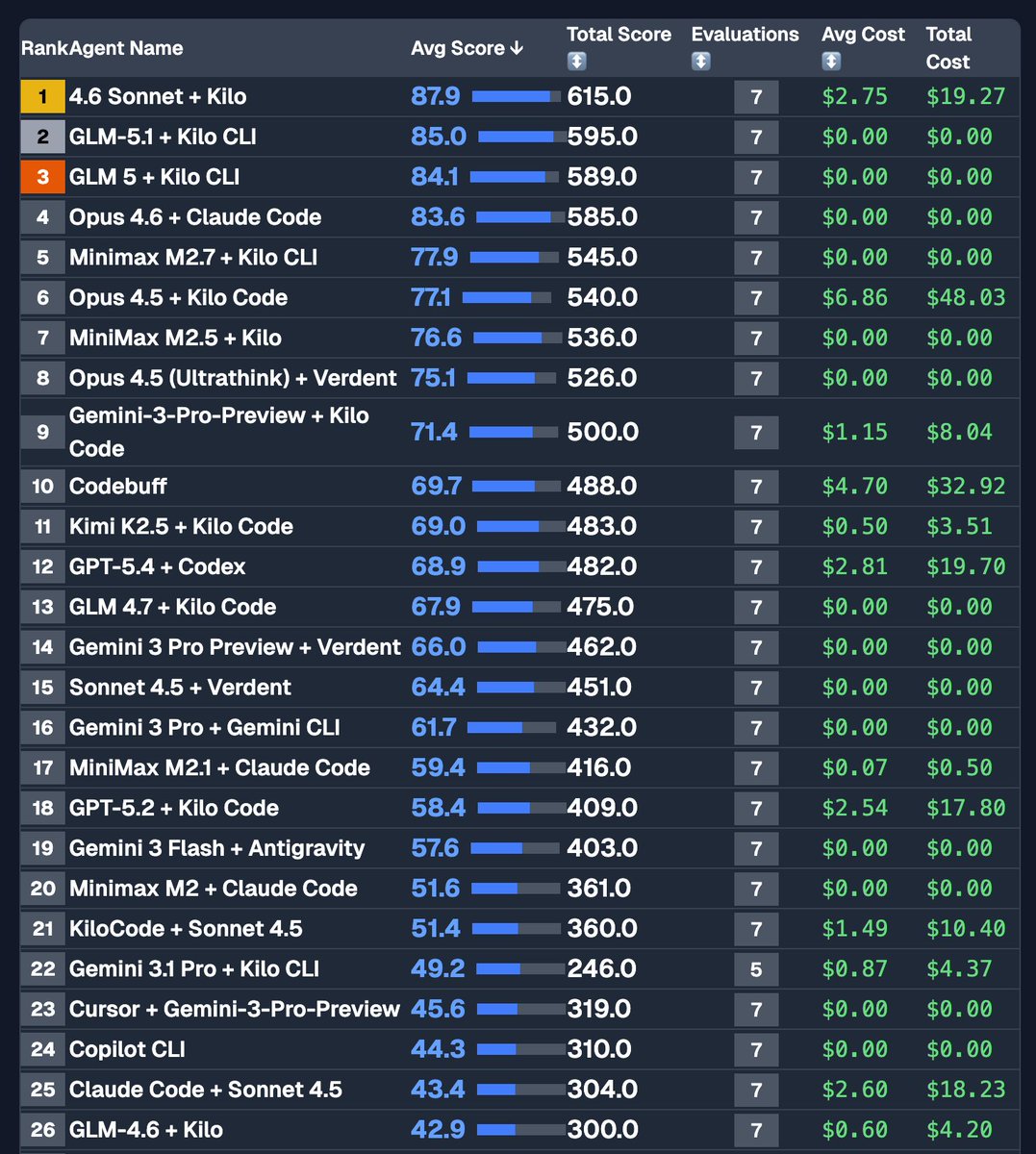
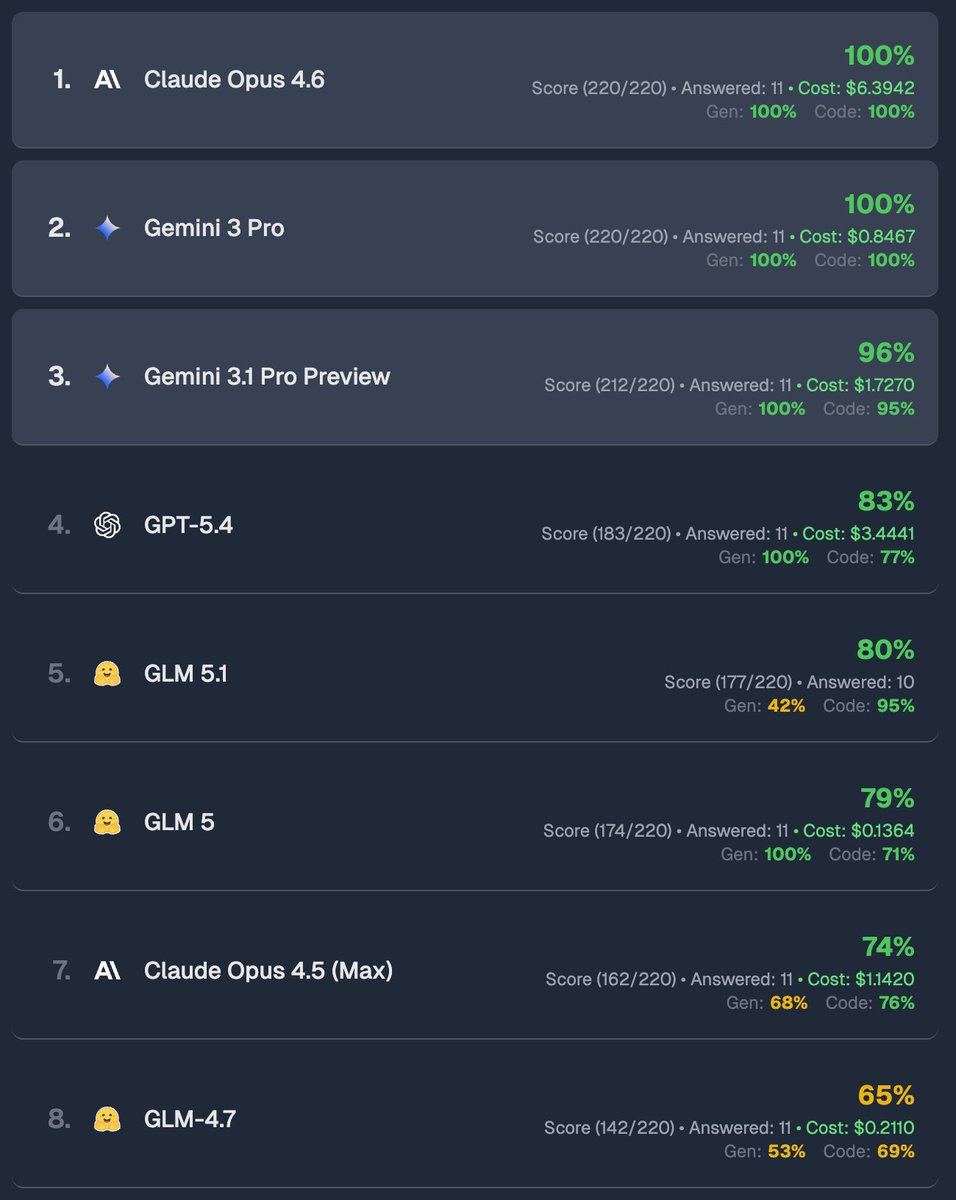
GLM-5.1 is available to ALL GLM Coding Plan users! z.ai/subscribe