send this to your girlfriend and say us
fishious@fishquichee
Me and the bad bitch i pulled by creating an elaborate geometric sand pattern
English
colloidal scientist
309 posts

Me and the bad bitch i pulled by creating an elaborate geometric sand pattern
Chappell Roan responds to the controversy involving a security guard confronting a young fan.

Staying at a 5 star hotel for the first time in my life cause the Ritz in Chengdu is $240 a night compared to $975 in Dallas and everything about this experience is totally blowing my mind.
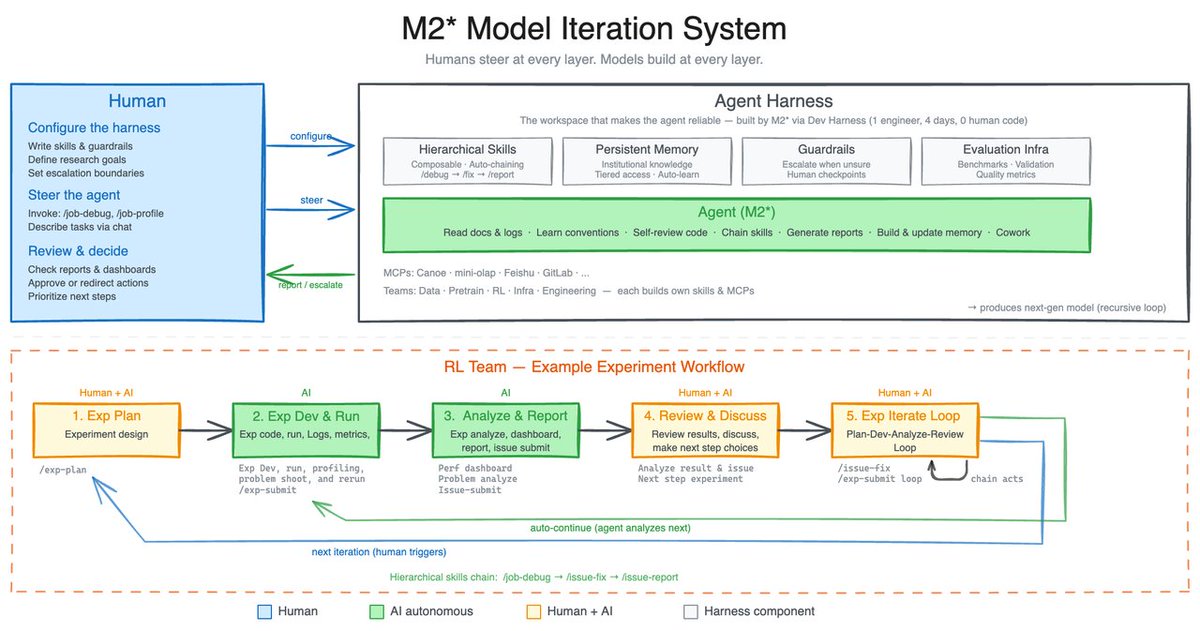
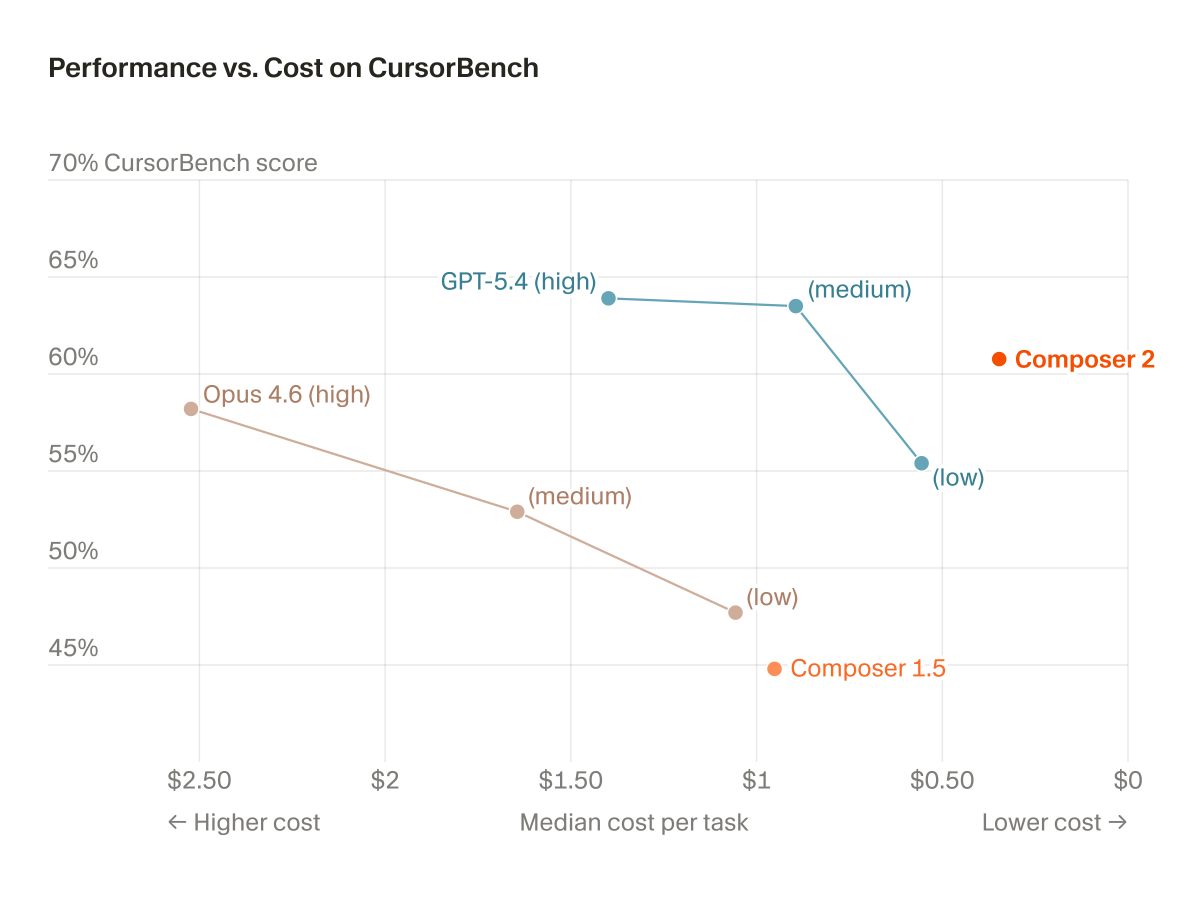
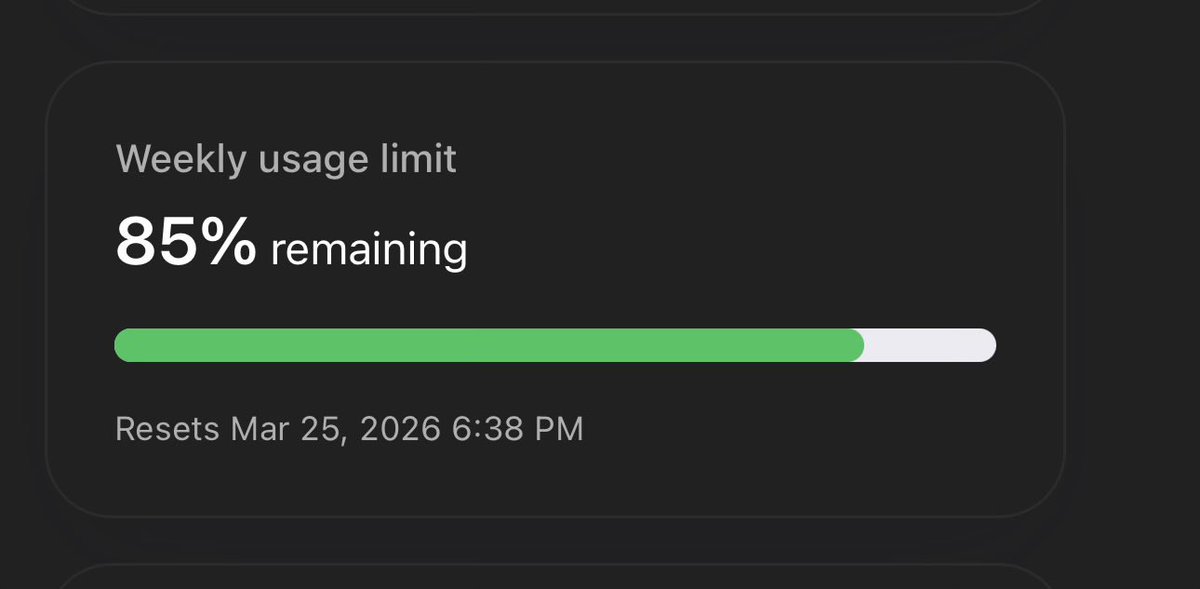
“If your $500K engineer isn’t burning at least $250K in tokens, something is wrong.”

“If your $500K engineer isn’t burning at least $250K in tokens, something is wrong.”


Mistral has released Mistral Small 4, an open weights model with hybrid reasoning and image input, scoring 27 on the Artificial Analysis Intelligence Index @MistralAI's Small 4 is a 119B mixture-of-experts model with 6.5B active parameters per token, supporting both reasoning and non-reasoning modes. In reasoning mode, Mistral Small 4 scores 27 on the Artificial Analysis Intelligence Index, a 12-point improvement from Small 3.2 (15) and now among the most intelligent models Mistral has released, surpassing Mistral Large 3 (23) and matching the proprietary Magistral Medium 1.2 (27). However, it lags open weights peers with similar total parameter counts such as gpt-oss-120B (high, 33), NVIDIA Nemotron 3 Super 120B A12B (Reasoning, 36), and Qwen3.5 122B A10B (Reasoning, 42). Key takeaways: ➤ Reasoning and non-reasoning modes in a single model: Mistral Small 4 supports configurable hybrid reasoning with reasoning and non-reasoning modes, rather than the separate reasoning variants Mistral has released previously with their Magistral models. In reasoning mode, the model scores 27 on the Artificial Analysis Intelligence Index. In non-reasoning mode, the model scores 19, a 4-point improvement from its predecessor Mistral Small 3.2 (15) ➤ More token efficient than peers of similar size: At ~52M output tokens, Mistral Small 4 (Reasoning) uses fewer tokens to run the Artificial Analysis Intelligence Index compared to reasoning models such as gpt-oss-120B (high, ~78M), NVIDIA Nemotron 3 Super 120B A12B (Reasoning, ~110M), and Qwen3.5 122B A10B (Reasoning, ~91M). In non-reasoning mode, the model uses ~4M output tokens ➤ Native support for image input: Mistral Small 4 is a multimodal model, accepting image input as well as text. On our multimodal evaluation, MMMU-Pro, Mistral Small 4 (Reasoning) scores 57%, ahead of Mistral Large 3 (56%) but behind Qwen3.5 122B A10B (Reasoning, 75%). Neither gpt-oss-120B nor NVIDIA Nemotron 3 Super 120B A12B support image input. All models support text output only ➤ Improvement in real-world agentic tasks: Mistral Small 4 scores an Elo of 871 on GDPval-AA, our evaluation based on OpenAI's GDPval dataset that tests models on real-world tasks across 44 occupations and 9 major industries, with models producing deliverables such as documents, spreadsheets, and diagrams in an agentic loop. This is more than double the Elo of Small 3.2 (339) and close to Mistral Large 3 (880), but behind gpt-oss-120B (high, 962), NVIDIA Nemotron 3 Super 120B A12B (Reasoning, 1021), and Qwen3.5 122B A10B (Reasoning, 1130) ➤ Lower hallucination rate than peer models of similar size: Mistral Small 4 scores -30 on AA-Omniscience, our evaluation of knowledge reliability and hallucination, where scores range from -100 to 100 (higher is better) and a negative score indicates more incorrect than correct answers. Mistral Small 4 scores ahead of gpt-oss-120B (high, -50), Qwen3.5 122B A10B (Reasoning, -40), and NVIDIA Nemotron 3 Super 120B A12B (Reasoning, -42) Key model details: ➤ Context window: 256K tokens (up from 128K on Small 3.2) ➤ Pricing: $0.15/$0.6 per 1M input/output tokens ➤ Availability: Mistral first-party API only. At native FP8 precision, Mistral Small 4's 119B parameters require ~119GB to self-host the weights (more than the 80GB of HBM3 memory on a single NVIDIA H100) ➤ Modality: Image and text input with text output only ➤ Licensing: Apache 2.0 license


Anthropic would have built this in a day and a dev would have tweeted the news. At OpenAI, an exec is telling you about a plan. That gap tells you everything. In the last 7 days, Anthropic shipped Dispatch, channels, voice mode, /loop, 1M context GA, MCP elicitation, persistent Cowork on mobile, Excel and PowerPoint cross-app context, inline charts, and 64k default output tokens. Felix Rieseberg tweeted "we're shipping Dispatch" and you could control your desktop Claude from your phone that afternoon. Every launch came from an engineering account or a GitHub release. In the same 7 days, OpenAI shipped GPT-5.4 mini and nano. Redesigned the model picker. Sunset the "Nerdy" personality preset. Announced three acquisitions. To find a comparable volume of shipped product from OpenAI, you have to rewind to December. This is the most underrated difference in AI right now. Anthropic PMs don't write PRDs. Boris Cherny, head of Claude Code, ships 10 to 30 PRs a day and hasn't written code by hand since November. 60 to 100 internal releases daily. Cowork was built with Claude Code in 10 days. The tools build the next version of the tools. Every cycle compresses the last one. Engineers are empowered to ship and announce. The entire org runs like a product team, not a corporation. OpenAI has the opposite problem. Fidji Simo is CEO of Applications, a title that exists because engineers aren't empowered to ship without executive approval chains. She joined from Instacart. Before that, a decade at Meta running the Facebook app. Since she arrived, OpenAI has acquired 12 companies for $11 billion in 10 months and announced a "superapp" consolidation through the Wall Street Journal. The exec responsible for shipping it is tweeting about "phases of exploration and refocus" on the product she hasn't shipped yet. That's what happens when you layer a Meta-style product org on top of an AI lab. Decisions go up. Shipping slows down. Announcements replace releases. Anthropic's product announcements come from the people who wrote the code. OpenAI's come from the C-suite and the press. One of those loops compounds. The other one meetings.