پن کیا گیا ٹویٹ
Chris
749 posts


Chris
@chrisdrit
Digging into new things! @FrameworkPuter @OmarchyLinux @Neovim, LLMs, Agents, AI and loving it!
Earth شامل ہوئے Kasım 2009
304 فالونگ302 فالوورز

morning dgx spark notes
wanted a better gemma 4 nvfp4 model to run locally, so i searched hugging face by actual deployment fit, not just model size
looked at:
gemma 4 nvfp4
gemma 4 26b a4b nvfp4
gemma 4 31b nvfp4
gb10 and dgx spark mentions
vllm tags
safetensor size
downloads and likes
whether there was a real serving recipe
the winner for my nvidia dgx spark was AEON-7/Gemma-4-26B-A4B-it-Uncensored-NVFP4 @SpaceTimeViking
why:
it is 26b moe with around 4b active
only about 16gb of weights
has a matching dflash drafter
has a dgx spark specific vllm container
fits the gb10 memory profile nicely
and it actually has a practical launch path instead of just a checkpoint
downloaded already, started the container, hit the openai compatible endpoint, and got a clean response back
running now on the dgx spark at 262k context
next step is benchmarking it against the heavier 31b nvfp4 options and seeing where the sweet spot is for latency vs quality
English
Brilliant! I would expect nothing less from @atmoio 🙌
Mo@atmoio
The Unethical Guide to Surviving AI Layoffs
English

Quickshell menu, Iron Man style for Omarchy.
I'm going to push the limits of Quickshell going forward to learn what it is capable of.
Vlad Tarko 🌐 🏗️@vladtarko
@iamdothash Can you make the Omarchy menu like this?
English
@ppressdev @mvanhorn just printed my first CLI for SEC Edgar data.
Printing Press is a nice project! Congrats on the hard work, excited to see my CLI added!
English
I need to try this...
NVIDIA AI@NVIDIAAI
OpenShell v0.0.37 🧩 pluggable compute drivers: Docker, Podman, Kubernetes, MicroVM 🔒 OIDC + RBAC gateway auth ☸️ Helm chart + Kubernetes user namespaces 📦 Debian, RPM, and Homebrew packages breaking: recreate the gateway before upgrading. github.com/NVIDIA/OpenShe…
English
got Gemma 4 26B A4B uncensored running locally on the DGX Spark.
setup:
- NVIDIA GB10 / Blackwell
- 128GB unified memory
- NVFP4 quantized model
- vLLM-compatible OpenAI API
- DFlash speculative decoding
- local only, no cloud API
the interesting part: this is small enough to run comfortably on the Spark, but still capable enough for agentic workflows.
with the @SpaceTimeViking vLLM container + DFlash drafter, it’s hitting interactive speeds that feel usable for local coding / research agents, roughly ~90 tok/s range in smoke tests, depending on prompt and settings.
still caveating this heavily:
- batch throughput and single user latency are different games
- DFlash helps a lot for interactive decode
- high concurrency may favor non speculative serving
- GB10/SM121 still has some weird kernel edge cases
but this is exactly why i wanted local hardware.
not just “run a model locally.”
actually tune the stack:
model → quantization → kernels → serving → speculation → agent loop
local AI is becoming less about downloading weights and more about owning the whole inference system.
that’s the fun part.
English
@mr_r0b0t @GIGABYTEUSA Interesting, I’ve had similar results bypassing my window manager, Hyprland, and just going directly through a TTY
English

@chrisdrit @GIGABYTEUSA The minute I stopped using GNOME it went from really good to excellent!
Definitely need to use it headless whenever possible!
English

@mr_r0b0t @morganlinton @NVIDIAAI @NousResearch @Teknium That’s very nice, was this on the dgx spark?
English
@morganlinton @NVIDIAAI @NousResearch @Teknium Z-lab doesn’t have a draft model for Nemotron so in pure tok/s it lost out. Concurrency however is where it makes up for it. It ran up to 192 concurrent requests before I stopped it for fear of OOM crash 😭
139.70 tok/s at c4 is stable and very workable!

English
Productive day for the @NVIDIAAI GB10!
“r0b0t-dgx” my @NousResearch Hermes agent finished up 2 more benchmark suites, 3 total today (all NVFP4):
Gemma4-31B + DFlash
Qwen3.6-35B-A3B + DFlash
Nemotron-3-Nano-30B-A3B
It just wrote the reports for the last 2 and emailed them to me 🤓

English

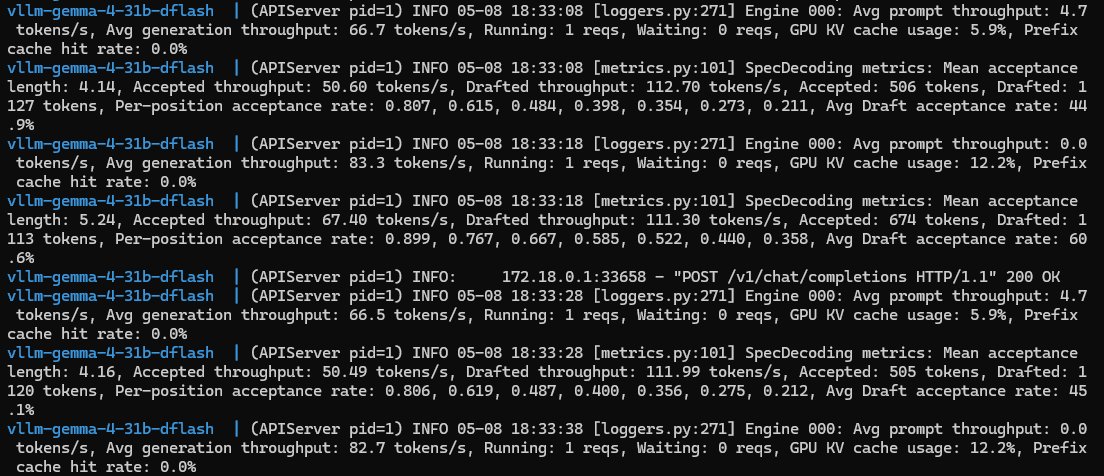
Spent today getting DFlash running on dual 3090 + Gemma 4 31B
From the very beginning I took a wrong turn
- AWQ 8bit + DFlash = 0.4% acceptance, drafter was trained on a different quant
- pip install PR branch → trashed my venv
What worked:
@malikwas1f club 3090 recipe, pre patched docker container. Just docker compose up
Results:
- 86 tok/s, accept rate 61.6%
+33% over my MTP result (52 tok/s)
Couldn't hit those 168 tok/s (hello PCIe x4 on the second card)
Gonna try to get better numbers tomorrow
English
@Stellanhaglund Yeah, fp8 + MTP gave us 49% mean draft acceptance (3.45/6). No fp16 baseline (probably should've run one). My hunch is fp8 costs some acceptance vs fp16, but fp8 matmul kernels are ~2× faster than fp16 so the tok/s tradeoff still favors fp8.
English

@chrisdrit Notice any difference in acceptance rate on fp8?
English

my local LLM community, give me one reason I shouldn't place the order.

English
Well... this is interesting!
Matt Van Horn@mvanhorn
Introducing the Printing Press, a CLI-factory and a CLI-library. Built with @trevin. 🏭🖨📚
Most APIs suck for agents. Most MCPs suck for agents. Most official CLIs suck for agents. They waste tokens and time. @steipete started making his own because of this.
📚 A Library of agent-native CLIs you install today (Linear, ESPN, Flight GOAT (Google Flights + Kayak nonstop), Contact Goat (LinkedIn + Happenstance + Deepline more) +30+ more)
🏭 A factory that prints new ones for any service - just type /printing-press
English
follow up receipt for the gemma 4 26b a4b nvfp4 + dflash demo i posted.
same local vllm setup on dgx spark / gb10, but this time with a fixed prompt streamed benchmark sweep:
single stream decode avg: 112.6 tok/s
8 stream wall aggregate avg: 684.6 tok/s
75 measured requests, 0 errors
token counts from final vllm usage packets. not an official benchmark, just a reproducible local run.
English
captured live run on DGX Spark: Gemma 4 26B A4B NVFP4 + DFlash via vLLM hit ~82 decode tok/s on a codegen stream and ~69 decode tok/s on a simultaneous debug/patch stream. not a formal benchmark, just a real local streamed run.
Model: github.com/AEON-7/Gemma-4… @SpaceTimeViking
English
@ai_hakase_ On a Mac M2 Max? That's insane! Thanks for linking to the discussion.
English

【2.5倍速】Qwen 3.6 27B × MTPでローカルAIが爆速化!
Qwen 3.6で「2.5倍速」という驚異の推論速度が実現されました!🚀
MTP(Multi-Token Prediction)技術により、Mac M2 Max環境でも28 tok/sを記録。これまでの常識を覆す爆速のコーディング体験が可能です。
さらに4-bit KVキャッシュ圧縮で、262kもの超ロングコンテキストに対応。膨大なドキュメント解析も、外部APIを使わず低コストで運用できます。ビジネスの生産性が劇的に向上しますね!✨
#Qwen #ローカルLLM

日本語
@eBotServers @MemoryReboot_ @modal @eBotServers "rtx 6000 pro" is that on a desktop? 149tps, i love where things are going!
English

@chrisdrit @MemoryReboot_ @modal That's insane. Going to try Gemma and dflash today on rtx 6000 pro. 🤤 27b hit 149tps, so I can imagine how high we can go vs the base models🙏
English
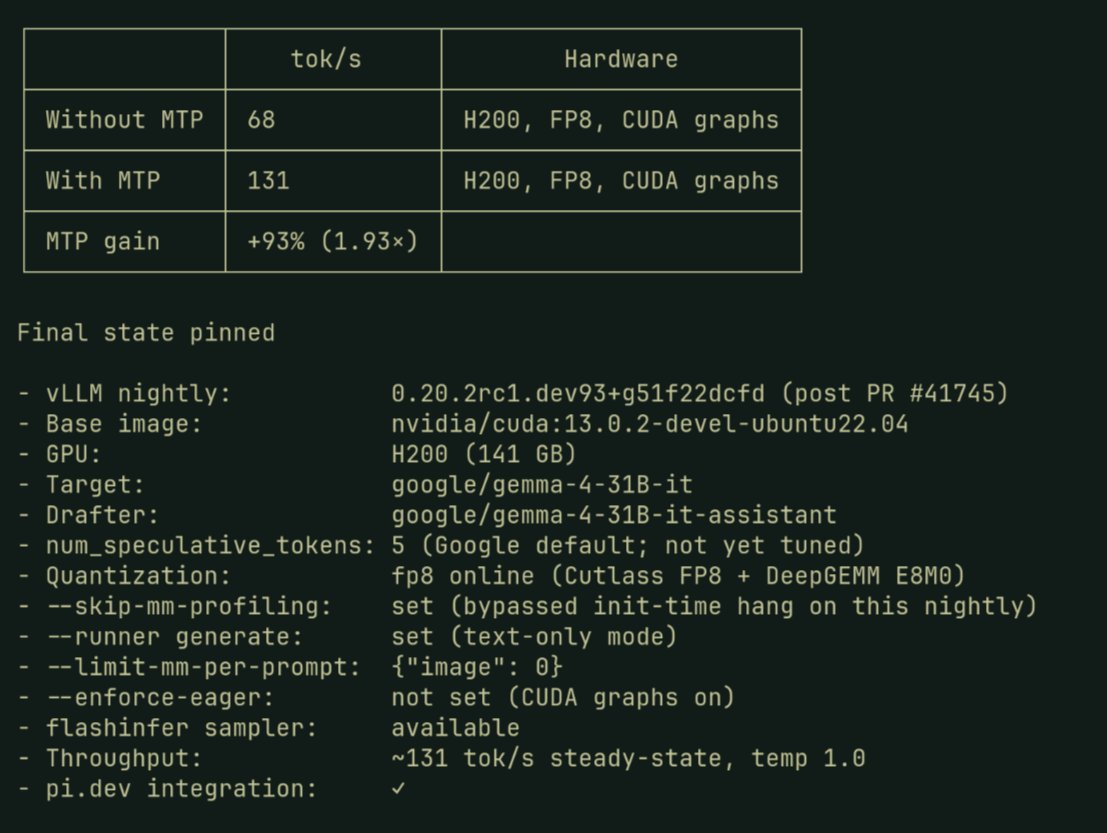
Tested Google's new MTP drafter for Gemma 31B on dual 3090
MTP off: 31 tok/s
MTP on: 52 tok/s (+68%), acceptance rate ~55%
Tried MTP=8 (officially recommended for 31B), got OOM
For comparison, my Qwen 3.6 27B + MTP on the same dual 3090 hits 70 tok/s. Gemma 31B is bigger so the gap makes sense
DFlash test next, going to push it further
Google for Developers@googledevs
Gemma 4: Now up to 3x Faster. ⚡ Same quality, way more speed. Our new MTP drafters allow Gemma 4 to predict multiple tokens at once, effectively tripling your output speed without compromising intelligence.
English
Hosting your own LLM is like growing your own food
First it's expensive, takes a lot of time and mistakes, everyone asks "why are you bothering just buy it at the store"
Then you taste a tomato from your garden and realize that supermarket plastic wasn't even close
Your own weights, context, your own rules — nobody nerfs the model or jacks up the token price
And most importantly: when the internet down or the store is closed — you still eat

English